Learning Efficient and Fair Policies for Uncertainty-Aware Collaborative Human-Robot Order Picking
2404.08006
0
0
Abstract
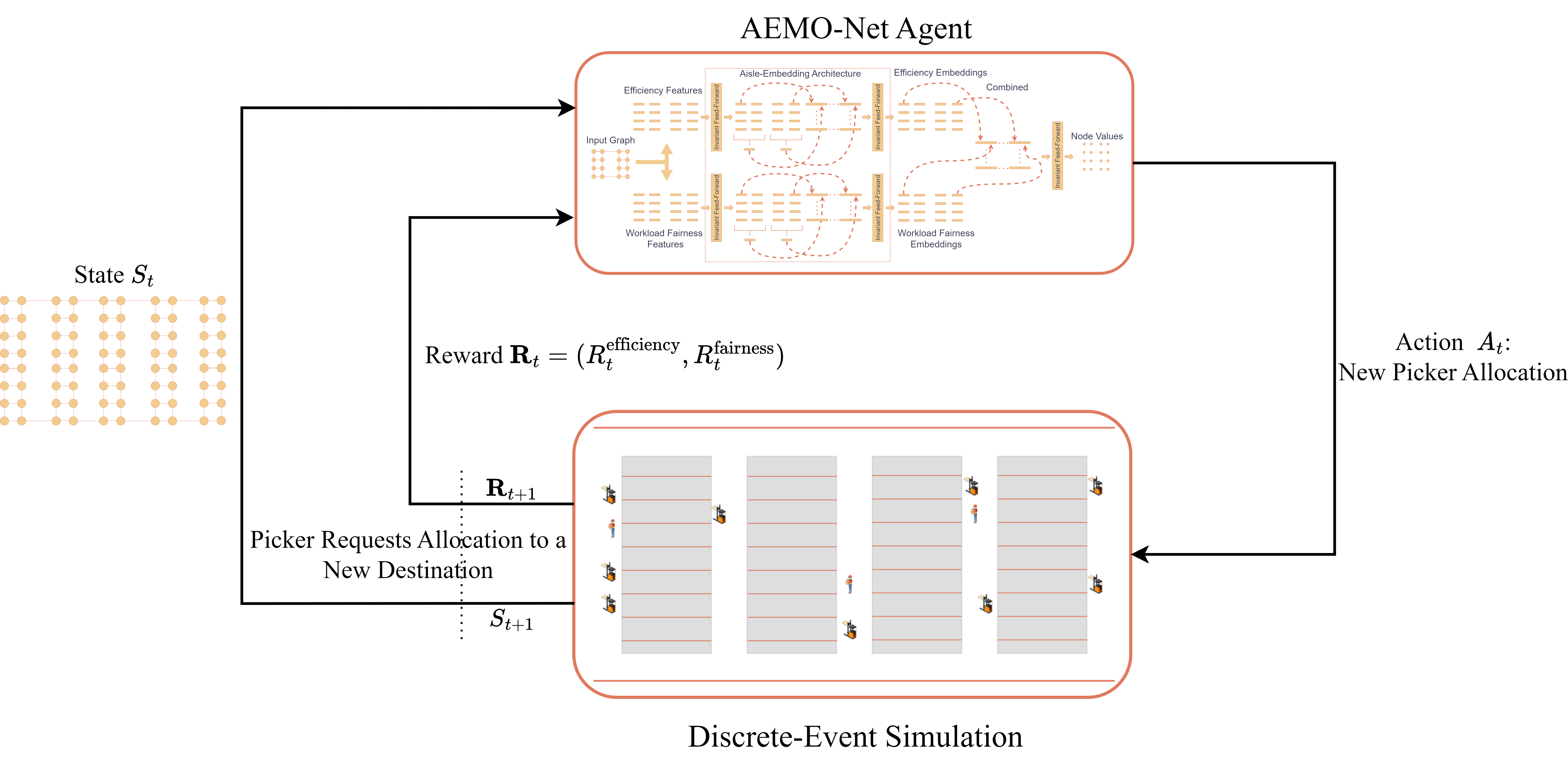
In collaborative human-robot order picking systems, human pickers and Autonomous Mobile Robots (AMRs) travel independently through a warehouse and meet at pick locations where pickers load items onto the AMRs. In this paper, we consider an optimization problem in such systems where we allocate pickers to AMRs in a stochastic environment. We propose a novel multi-objective Deep Reinforcement Learning (DRL) approach to learn effective allocation policies to maximize pick efficiency while also aiming to improve workload fairness amongst human pickers. In our approach, we model the warehouse states using a graph, and define a neural network architecture that captures regional information and effectively extracts representations related to efficiency and workload. We develop a discrete-event simulation model, which we use to train and evaluate the proposed DRL approach. In the experiments, we demonstrate that our approach can find non-dominated policy sets that outline good trade-offs between fairness and efficiency objectives. The trained policies outperform the benchmarks in terms of both efficiency and fairness. Moreover, they show good transferability properties when tested on scenarios with different warehouse sizes. The implementation of the simulation model, proposed approach, and experiments are published.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a study on learning efficient and fair policies for uncertainty-aware collaborative human-robot order picking.
- The researchers developed a reinforcement learning-based approach to optimize order picking with a human-robot team, considering uncertainty in task completion times.
- The goal is to improve the efficiency and fairness of the order picking process while accounting for the unpredictability of human behavior.
Plain English Explanation
In a warehouse or distribution center, the process of picking and packing orders is an important but complex task. This paper looks at ways to improve this process when it's done by a team of humans and robots working together.
The key challenge is that the time it takes for humans to complete their tasks can be unpredictable and uncertain. This uncertainty makes it hard to efficiently coordinate the work between the human and robot team members. The researchers developed a new machine learning approach to address this challenge.
Their approach uses reinforcement learning, a type of AI that learns by trial-and-error, to find the best way for the human and robot to work together. The goal is to complete orders as quickly as possible, while also making sure the workload is distributed fairly between the human and robot.
By accounting for the uncertainty in how long human tasks take, the approach can adapt and optimize the team's workflow. This helps improve both the efficiency of order picking and the fairness of how work is divided between the human and robot.
The researchers tested their approach in simulations and found it outperformed other methods at balancing efficiency and fairness in collaborative human-robot order picking.
Technical Explanation
The paper presents a reinforcement learning-based approach for learning efficient and fair policies for uncertainty-aware collaborative human-robot order picking.
The key challenge addressed is the uncertainty in human task completion times, which makes it difficult to effectively coordinate the workflow between human and robot team members. The researchers developed a Markov decision process (MDP) formulation to model the collaborative order picking problem, incorporating uncertainty in human task durations.
They then propose a reinforcement learning algorithm, called Intervention-Assisted Policy Gradient (IAPG), to learn efficient and fair policies for assigning tasks to the human and robot. IAPG combines policy gradient methods with human interventions to guide the learning process towards more efficient and fair solutions.
The performance of the proposed approach is evaluated through simulations, comparing it to other baselines such as JUICER and MESA-DRL. The results demonstrate that the IAPG-based approach can effectively balance efficiency and fairness in collaborative human-robot order picking, outperforming the compared methods.
Critical Analysis
The paper presents a well-designed study that addresses an important practical problem in warehouse operations. The incorporation of uncertainty in human task completion times is a key strength, as it aligns with the real-world challenges of coordinating human-robot collaboration.
However, the paper does not discuss potential limitations or caveats of the proposed approach. For example, it would be useful to understand how the method would scale to larger-scale order picking scenarios with more human and robot team members, or how sensitive the performance is to the accuracy of the estimated human task duration distributions.
Additionally, while the fairness objective is an important consideration, the paper does not explore alternative fairness metrics or the potential trade-offs between efficiency and different fairness criteria. Investigating these trade-offs could provide valuable insights for practitioners.
Overall, the research presented in this paper is a meaningful contribution to the field of collaborative human-robot task planning. Further exploration of the method's robustness and generalization to a wider range of scenarios would strengthen the work and help practitioners better understand its practical applicability.
Conclusion
This paper introduces a reinforcement learning-based approach for learning efficient and fair policies in uncertainty-aware collaborative human-robot order picking. By accounting for the unpredictability of human task completion times, the proposed method can optimize the workflow to balance efficiency and fairness between the human and robot team members.
The results demonstrate the effectiveness of the approach compared to other state-of-the-art methods, highlighting its potential to improve the productivity and equitable distribution of work in warehouse order picking operations. As automation and human-robot collaboration become increasingly prevalent in logistics, this research contributes valuable insights for designing robust and adaptive task planning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Reducing Risk for Assistive Reinforcement Learning Policies with Diffusion Models
Andrii Tytarenko
0
0
Care-giving and assistive robotics, driven by advancements in AI, offer promising solutions to meet the growing demand for care, particularly in the context of increasing numbers of individuals requiring assistance. This creates a pressing need for efficient and safe assistive devices, particularly in light of heightened demand due to war-related injuries. While cost has been a barrier to accessibility, technological progress is able to democratize these solutions. Safety remains a paramount concern, especially given the intricate interactions between assistive robots and humans. This study explores the application of reinforcement learning (RL) and imitation learning, in improving policy design for assistive robots. The proposed approach makes the risky policies safer without additional environmental interactions. Through experimentation using simulated environments, the enhancement of the conventional RL approaches in tasks related to assistive robotics is demonstrated.
5/14/2024

Learning Manipulation Tasks in Dynamic and Shared 3D Spaces
Hariharan Arunachalam, Marc Hanheide, Sariah Mghames
0
0
Automating the segregation process is a need for every sector experiencing a high volume of materials handling, repetitive and exhaustive operations, in addition to risky exposures. Learning automated pick-and-place operations can be efficiently done by introducing collaborative autonomous systems (e.g. manipulators) in the workplace and among human operators. In this paper, we propose a deep reinforcement learning strategy to learn the place task of multi-categorical items from a shared workspace between dual-manipulators and to multi-goal destinations, assuming the pick has been already completed. The learning strategy leverages first a stochastic actor-critic framework to train an agent's policy network, and second, a dynamic 3D Gym environment where both static and dynamic obstacles (e.g. human factors and robot mate) constitute the state space of a Markov decision process. Learning is conducted in a Gazebo simulator and experiments show an increase in cumulative reward function for the agent further away from human factors. Future investigations will be conducted to enhance the task performance for both agents simultaneously.
4/30/2024

Efficient Reinforcement Learning of Task Planners for Robotic Palletization through Iterative Action Masking Learning
Zheng Wu, Yichuan Li, Wei Zhan, Changliu Liu, Yun-Hui Liu, Masayoshi Tomizuka
0
0
The development of robotic systems for palletization in logistics scenarios is of paramount importance, addressing critical efficiency and precision demands in supply chain management. This paper investigates the application of Reinforcement Learning (RL) in enhancing task planning for such robotic systems. Confronted with the substantial challenge of a vast action space, which is a significant impediment to efficiently apply out-of-the-shelf RL methods, our study introduces a novel method of utilizing supervised learning to iteratively prune and manage the action space effectively. By reducing the complexity of the action space, our approach not only accelerates the learning phase but also ensures the effectiveness and reliability of the task planning in robotic palletization. The experimental results underscore the efficacy of this method, highlighting its potential in improving the performance of RL applications in complex and high-dimensional environments like logistics palletization.
4/9/2024
Towards Optimizing Human-Centric Objectives in AI-Assisted Decision-Making With Offline Reinforcement Learning
Zana Buc{c}inca, Siddharth Swaroop, Amanda E. Paluch, Susan A. Murphy, Krzysztof Z. Gajos
0
0
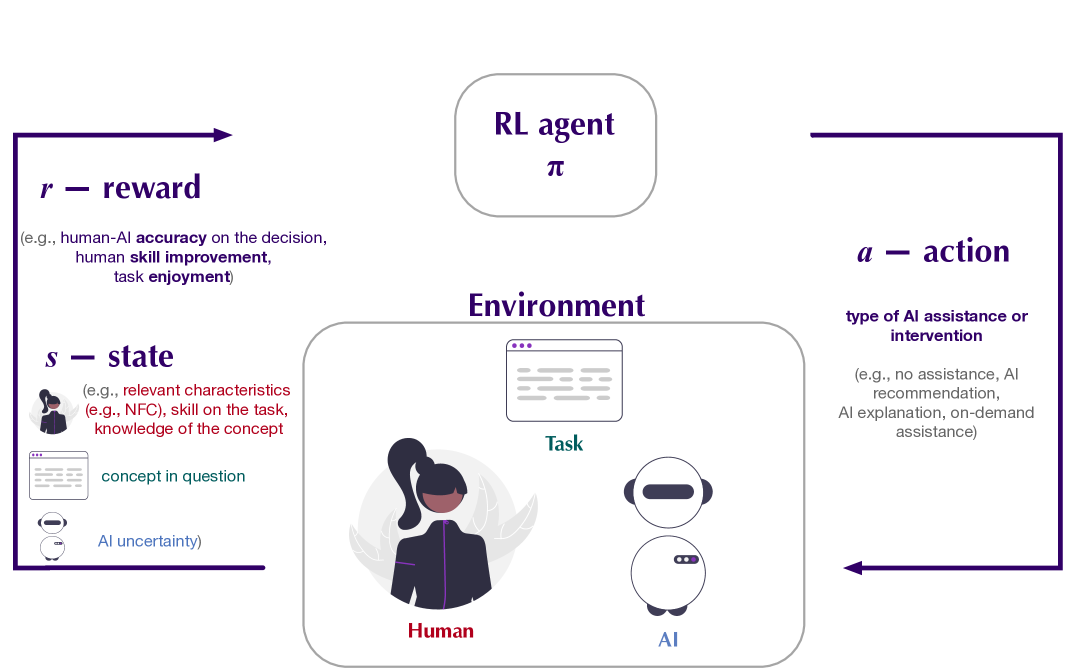
Imagine if AI decision-support tools not only complemented our ability to make accurate decisions, but also improved our skills, boosted collaboration, and elevated the joy we derive from our tasks. Despite the potential to optimize a broad spectrum of such human-centric objectives, the design of current AI tools remains focused on decision accuracy alone. We propose offline reinforcement learning (RL) as a general approach for modeling human-AI decision-making to optimize human-AI interaction for diverse objectives. RL can optimize such objectives by tailoring decision support, providing the right type of assistance to the right person at the right time. We instantiated our approach with two objectives: human-AI accuracy on the decision-making task and human learning about the task and learned decision support policies from previous human-AI interaction data. We compared the optimized policies against several baselines in AI-assisted decision-making. Across two experiments (N=316 and N=964), our results demonstrated that people interacting with policies optimized for accuracy achieve significantly better accuracy -- and even human-AI complementarity -- compared to those interacting with any other type of AI support. Our results further indicated that human learning was more difficult to optimize than accuracy, with participants who interacted with learning-optimized policies showing significant learning improvement only at times. Our research (1) demonstrates offline RL to be a promising approach to model human-AI decision-making, leading to policies that may optimize human-centric objectives and provide novel insights about the AI-assisted decision-making space, and (2) emphasizes the importance of considering human-centric objectives beyond decision accuracy in AI-assisted decision-making, opening up the novel research challenge of optimizing human-AI interaction for such objectives.
4/16/2024