Towards Optimizing Human-Centric Objectives in AI-Assisted Decision-Making With Offline Reinforcement Learning
2403.05911
0
0
Abstract
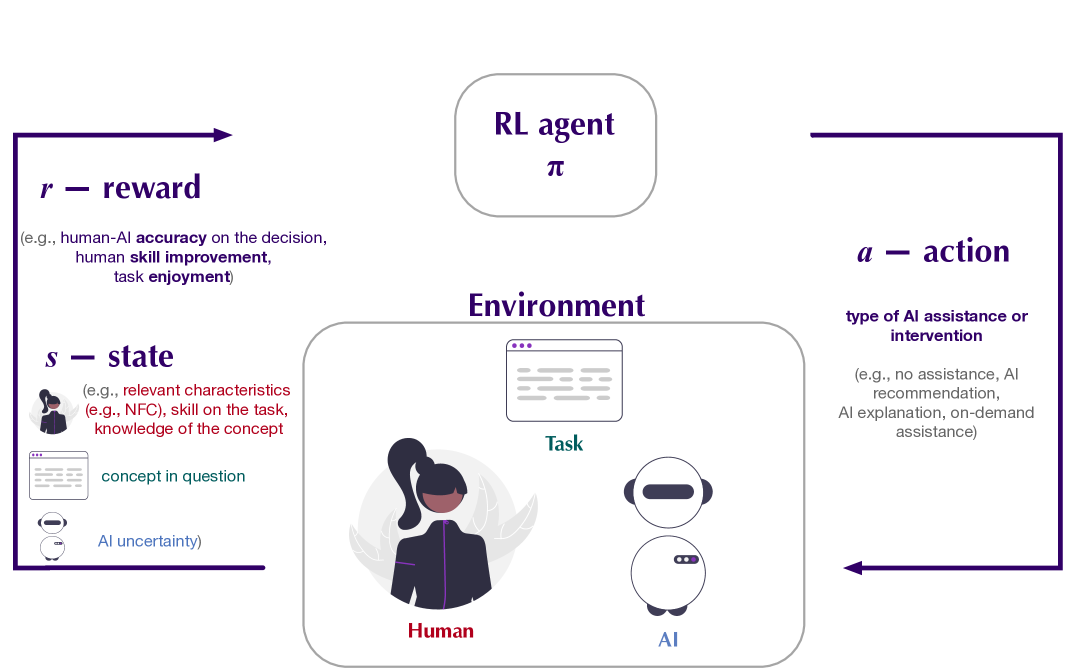
Imagine if AI decision-support tools not only complemented our ability to make accurate decisions, but also improved our skills, boosted collaboration, and elevated the joy we derive from our tasks. Despite the potential to optimize a broad spectrum of such human-centric objectives, the design of current AI tools remains focused on decision accuracy alone. We propose offline reinforcement learning (RL) as a general approach for modeling human-AI decision-making to optimize human-AI interaction for diverse objectives. RL can optimize such objectives by tailoring decision support, providing the right type of assistance to the right person at the right time. We instantiated our approach with two objectives: human-AI accuracy on the decision-making task and human learning about the task and learned decision support policies from previous human-AI interaction data. We compared the optimized policies against several baselines in AI-assisted decision-making. Across two experiments (N=316 and N=964), our results demonstrated that people interacting with policies optimized for accuracy achieve significantly better accuracy -- and even human-AI complementarity -- compared to those interacting with any other type of AI support. Our results further indicated that human learning was more difficult to optimize than accuracy, with participants who interacted with learning-optimized policies showing significant learning improvement only at times. Our research (1) demonstrates offline RL to be a promising approach to model human-AI decision-making, leading to policies that may optimize human-centric objectives and provide novel insights about the AI-assisted decision-making space, and (2) emphasizes the importance of considering human-centric objectives beyond decision accuracy in AI-assisted decision-making, opening up the novel research challenge of optimizing human-AI interaction for such objectives.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how to optimize human-centric objectives in AI-assisted decision-making using offline reinforcement learning.
- The research aims to address potential issues with overreliance on AI systems and ensure that human-centric goals are prioritized.
- Key focus areas include human-centered AI, explainable AI, and improving human-AI interaction in decision support systems.
Plain English Explanation
This research paper looks at ways to make AI-powered decision-making systems better align with human values and priorities. The main idea is to use a machine learning technique called "offline reinforcement learning" to train AI models to optimize for objectives that are meaningful to humans, rather than just raw performance metrics.
The researchers are concerned that as AI becomes more capable, people may start to overly rely on AI recommendations without understanding how the AI is making decisions. This could lead to AI-assisted decisions that don't actually reflect human preferences. To address this, the paper explores methods for developing AI systems that are more "human-centered" - meaning they take into account human values, preferences, and needs.
Some key concepts explored in the paper include "explainable AI," which refers to making AI decision-making more transparent and understandable to humans, and improving the overall interaction between humans and AI in decision support systems. The goal is to create AI assistants that can help people make choices, while still keeping human decision-makers in control and ensuring the outcomes align with human-centric objectives.
Technical Explanation
The paper proposes an approach that uses offline reinforcement learning to optimize AI-assisted decision-making for human-centric objectives. Offline reinforcement learning is a machine learning technique that allows an AI model to be trained on historical data, without requiring direct interaction with a live environment.
The researchers argue that this offline approach is well-suited for human-AI decision support systems, as it allows the AI to be trained on past human decisions and behaviors, rather than having to learn directly from human interactions. This can help ensure the AI's recommendations are more aligned with how humans actually make choices in the real world.
The paper also discusses the importance of explainable AI - making the AI's decision-making process more transparent and interpretable to human users. By increasing the explainability of the AI system, the researchers aim to build greater trust and better collaboration between humans and the AI assistant.
Additionally, the paper explores techniques for strategic opponent modeling - allowing the AI to better understand and anticipate human decision-making patterns. This can further enhance the AI's ability to provide helpful, human-centric recommendations.
Critical Analysis
The paper presents a thoughtful approach to addressing the challenge of overreliance on AI in decision-making. By focusing on human-centric objectives and improving human-AI collaboration, the researchers acknowledge the importance of keeping human decision-makers in the loop and ensuring AI recommendations align with human values.
However, the paper does not fully address potential issues around bias in the historical data used to train the AI models. If the past human decisions reflected in the training data are themselves biased or suboptimal, the AI may learn to perpetuate those biases. Further research may be needed to address this challenge.
Additionally, the paper does not delve into how to effectively guide human decision-makers using the AI system. While the focus is on human-centric objectives, more detail on the specific mechanisms for incorporating human preferences and values into the AI's recommendations would be helpful.
Conclusion
This research paper presents a promising approach for developing AI-assisted decision-making systems that are better aligned with human values and priorities. By leveraging offline reinforcement learning and emphasizing explainability and human-AI collaboration, the researchers aim to create AI assistants that can enhance human decision-making without leading to overreliance or unintended consequences.
While the paper raises important considerations around the challenges of human-centric AI, further research will be needed to fully address issues of bias, transparency, and the practical integration of these systems into real-world decision-making processes. Overall, this work represents a valuable contribution to the ongoing effort to ensure AI technologies empower and augment human decision-makers, rather than replace or undermine them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Reducing Risk for Assistive Reinforcement Learning Policies with Diffusion Models
Andrii Tytarenko
0
0
Care-giving and assistive robotics, driven by advancements in AI, offer promising solutions to meet the growing demand for care, particularly in the context of increasing numbers of individuals requiring assistance. This creates a pressing need for efficient and safe assistive devices, particularly in light of heightened demand due to war-related injuries. While cost has been a barrier to accessibility, technological progress is able to democratize these solutions. Safety remains a paramount concern, especially given the intricate interactions between assistive robots and humans. This study explores the application of reinforcement learning (RL) and imitation learning, in improving policy design for assistive robots. The proposed approach makes the risky policies safer without additional environmental interactions. Through experimentation using simulated environments, the enhancement of the conventional RL approaches in tasks related to assistive robotics is demonstrated.
5/14/2024
🏅
Robust Reinforcement Learning Objectives for Sequential Recommender Systems
Melissa Mozifian, Tristan Sylvain, Dave Evans, Lili Meng
0
0
Attention-based sequential recommendation methods have shown promise in accurately capturing users' evolving interests from their past interactions. Recent research has also explored the integration of reinforcement learning (RL) into these models, in addition to generating superior user representations. By framing sequential recommendation as an RL problem with reward signals, we can develop recommender systems that incorporate direct user feedback in the form of rewards, enhancing personalization for users. Nonetheless, employing RL algorithms presents challenges, including off-policy training, expansive combinatorial action spaces, and the scarcity of datasets with sufficient reward signals. Contemporary approaches have attempted to combine RL and sequential modeling, incorporating contrastive-based objectives and negative sampling strategies for training the RL component. In this work, we further emphasize the efficacy of contrastive-based objectives paired with augmentation to address datasets with extended horizons. Additionally, we recognize the potential instability issues that may arise during the application of negative sampling. These challenges primarily stem from the data imbalance prevalent in real-world datasets, which is a common issue in offline RL contexts. Furthermore, we introduce an enhanced methodology aimed at providing a more effective solution to these challenges. Experimental results across several real datasets show our method with increased robustness and state-of-the-art performance.
4/19/2024
Understanding the performance gap between online and offline alignment algorithms
Yunhao Tang, Daniel Zhaohan Guo, Zeyu Zheng, Daniele Calandriello, Yuan Cao, Eugene Tarassov, R'emi Munos, Bernardo 'Avila Pires, Michal Valko, Yong Cheng, Will Dabney
0
0
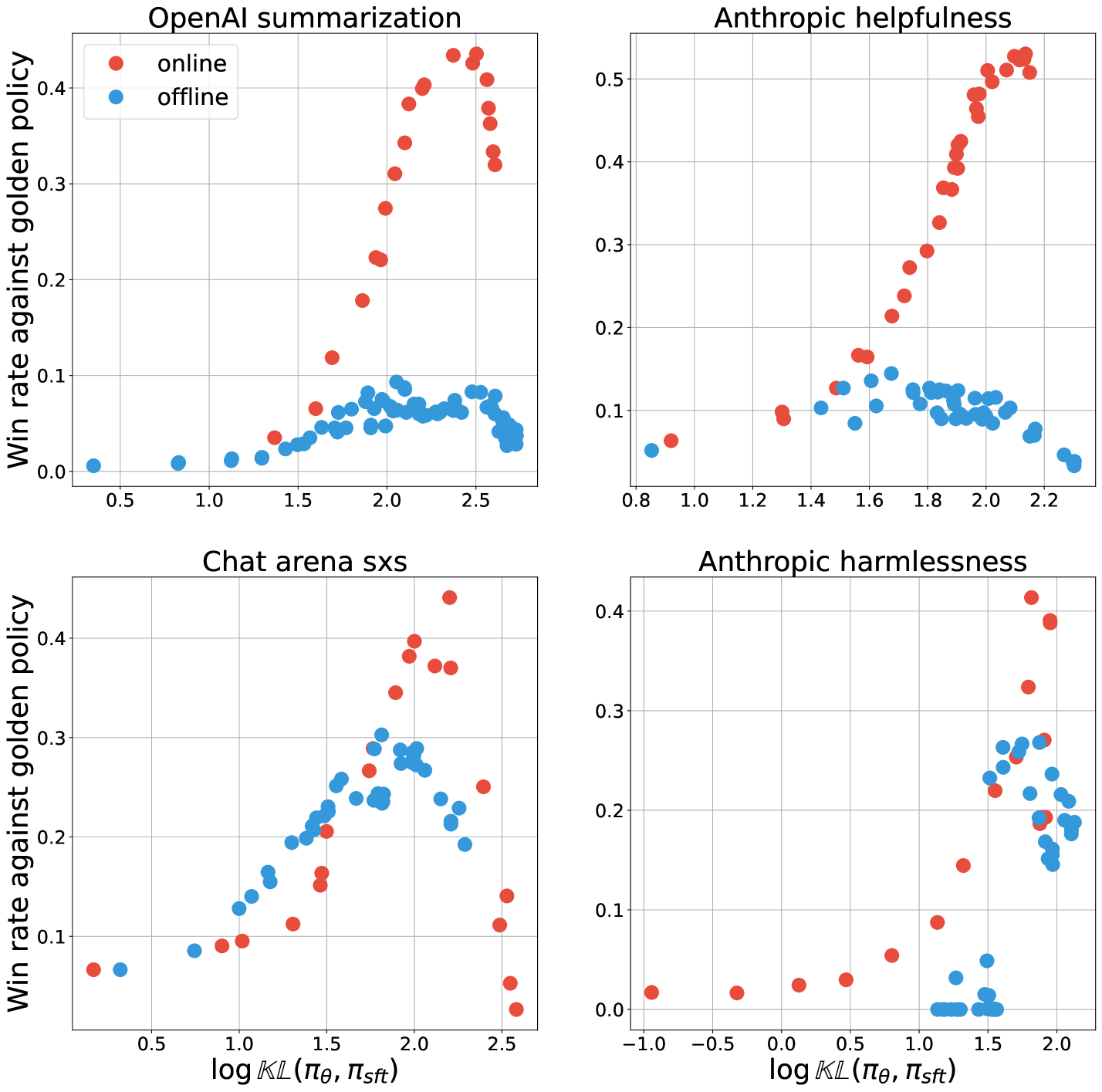
Reinforcement learning from human feedback (RLHF) is the canonical framework for large language model alignment. However, rising popularity in offline alignment algorithms challenge the need for on-policy sampling in RLHF. Within the context of reward over-optimization, we start with an opening set of experiments that demonstrate the clear advantage of online methods over offline methods. This prompts us to investigate the causes to the performance discrepancy through a series of carefully designed experimental ablations. We show empirically that hypotheses such as offline data coverage and data quality by itself cannot convincingly explain the performance difference. We also find that while offline algorithms train policy to become good at pairwise classification, it is worse at generations; in the meantime the policies trained by online algorithms are good at generations while worse at pairwise classification. This hints at a unique interplay between discriminative and generative capabilities, which is greatly impacted by the sampling process. Lastly, we observe that the performance discrepancy persists for both contrastive and non-contrastive loss functions, and appears not to be addressed by simply scaling up policy networks. Taken together, our study sheds light on the pivotal role of on-policy sampling in AI alignment, and hints at certain fundamental challenges of offline alignment algorithms.
5/15/2024
Designing Algorithmic Recommendations to Achieve Human-AI Complementarity
Bryce McLaughlin, Jann Spiess
0
0
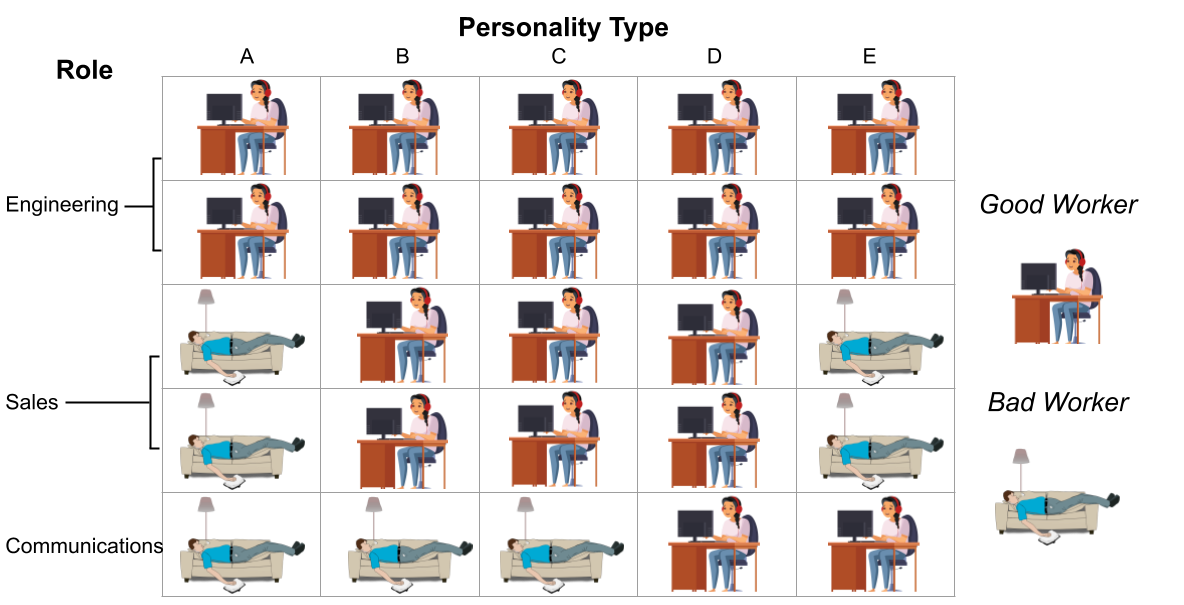
Algorithms frequently assist, rather than replace, human decision-makers. However, the design and analysis of algorithms often focus on predicting outcomes and do not explicitly model their effect on human decisions. This discrepancy between the design and role of algorithmic assistants becomes of particular concern in light of empirical evidence that suggests that algorithmic assistants again and again fail to improve human decisions. In this article, we formalize the design of recommendation algorithms that assist human decision-makers without making restrictive ex-ante assumptions about how recommendations affect decisions. We formulate an algorithmic-design problem that leverages the potential-outcomes framework from causal inference to model the effect of recommendations on a human decision-maker's binary treatment choice. Within this model, we introduce a monotonicity assumption that leads to an intuitive classification of human responses to the algorithm. Under this monotonicity assumption, we can express the human's response to algorithmic recommendations in terms of their compliance with the algorithm and the decision they would take if the algorithm sends no recommendation. We showcase the utility of our framework using an online experiment that simulates a hiring task. We argue that our approach explains the relative performance of different recommendation algorithms in the experiment, and can help design solutions that realize human-AI complementarity.
5/3/2024