Learning Embeddings for Sequential Tasks Using Population of Agents

0
📶
Sign in to get full access
Overview
- This paper presents an information-theoretic framework to learn fixed-dimensional embeddings for tasks in reinforcement learning.
- The key idea is that two tasks are considered similar if observing an agent's performance on one task reduces the uncertainty about its performance on the other.
- The authors use a diverse agent population as an approximation for the space of agents to measure this task similarity in sequential decision-making settings.
- They demonstrate the effectiveness of this approach for two applications: predicting an agent's performance on a new task and selecting tasks with desired characteristics from a set of options.
Plain English Explanation
The researchers have developed a new way to understand how similar different tasks are in reinforcement learning. The core idea is that if observing how well an agent performs on one task helps you predict how it will do on another task, then those two tasks are considered similar.
To measure this, the researchers use a diverse collection of agents as a stand-in for the full space of possible agents. They then look at how much information about an agent's performance on one task is revealed by its performance on another task. Tasks that share a lot of this "mutual information" are deemed more similar.
The researchers show that this information-theoretic approach to quantifying task similarity is useful for two practical applications in reinforcement learning. First, it allows them to predict how well an agent will perform on a new task, just by looking at its performance on a small set of "quiz" tasks. Second, it helps them select tasks from a larger pool that have desired characteristics, like being more or less similar to a reference task.
This work provides a principled, information-based way to understand the relationships between different decision-making tasks, which could be valuable for applications that leverage task embeddings or transfer learning in reinforcement learning.
Technical Explanation
The core of this work is an information-theoretic framework for learning task embeddings in reinforcement learning. The authors start from the intuition that two tasks are similar if an agent's performance on one task provides information about its performance on the other.
Formally, they define a task similarity metric based on the mutual information between an agent's performance on two tasks. To approximate this, they use a diverse population of agents as a stand-in for the full space of possible agents. They then compute the mutual information between each pair of tasks by looking at the performance correlations across this agent population.
The authors demonstrate the value of these learned task embeddings in two reinforcement learning scenarios. First, they show that the task similarities can be used to predict an agent's performance on a new task by observing its performance on a small "quiz" of related tasks, via meta-learning. Second, they use the task embeddings to select a subset of tasks from a larger pool that have desired characteristics, like being more or less similar to a reference task, which could be useful for curriculum learning or transfer learning scenarios.
Critical Analysis
The core information-theoretic approach in this work provides a principled and flexible way to quantify task similarity in reinforcement learning. However, the authors note that their framework relies on having access to a diverse population of agents as a proxy for the full agent space. In practice, this agent diversity may be difficult to obtain, which could limit the applicability of their techniques.
Additionally, the paper does not deeply explore the nature of the task similarities captured by the learned embeddings. While the authors demonstrate the utility of these embeddings for specific applications, it would be valuable to further investigate the types of task relationships that are being encoded and their cognitive interpretability.
Finally, the authors primarily evaluate their approach on relatively simple synthetic environments. Demonstrating the effectiveness of their techniques on more complex, real-world reinforcement learning problems would further strengthen the impact of this work.
Conclusion
This paper presents an innovative information-theoretic framework for learning task embeddings in reinforcement learning. By quantifying task similarity based on mutual information between agent performance, the authors enable new applications like predicting agent performance on novel tasks and selecting subsets of tasks with desired characteristics.
While the reliance on a diverse agent population is a potential limitation, this work provides a principled and flexible approach to understanding relationships between decision-making tasks. Further research into the nature of the learned task embeddings and their effectiveness on more complex real-world problems could unlock even greater practical benefits.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Learning Embeddings for Sequential Tasks Using Population of Agents
Mridul Mahajan, Georgios Tzannetos, Goran Radanovic, Adish Singla
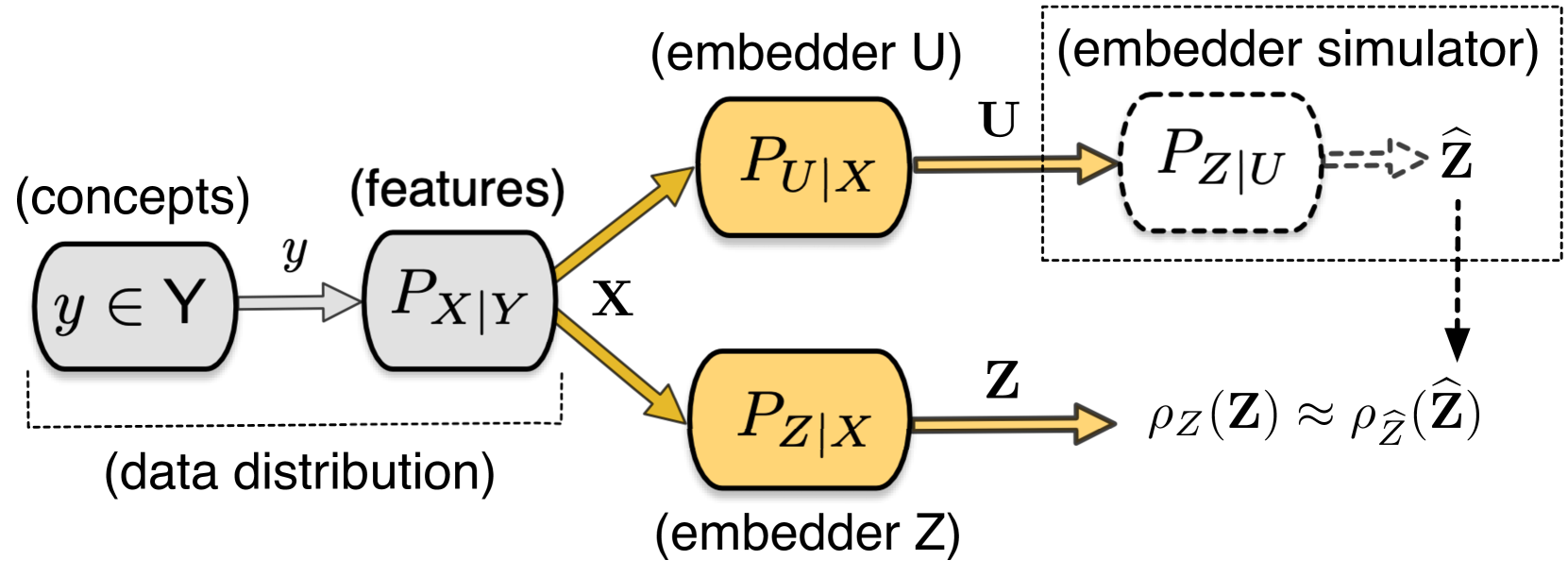
We present an information-theoretic framework to learn fixed-dimensional embeddings for tasks in reinforcement learning. We leverage the idea that two tasks are similar if observing an agent's performance on one task reduces our uncertainty about its performance on the other. This intuition is captured by our information-theoretic criterion which uses a diverse agent population as an approximation for the space of agents to measure similarity between tasks in sequential decision-making settings. In addition to qualitative assessment, we empirically demonstrate the effectiveness of our techniques based on task embeddings by quantitative comparisons against strong baselines on two application scenarios: predicting an agent's performance on a new task by observing its performance on a small quiz of tasks, and selecting tasks with desired characteristics from a given set of options.
Read more5/10/2024
0
When is an Embedding Model More Promising than Another?
Maxime Darrin, Philippe Formont, Ismail Ben Ayed, Jackie CK Cheung, Pablo Piantanida
Embedders play a central role in machine learning, projecting any object into numerical representations that can, in turn, be leveraged to perform various downstream tasks. The evaluation of embedding models typically depends on domain-specific empirical approaches utilizing downstream tasks, primarily because of the lack of a standardized framework for comparison. However, acquiring adequately large and representative datasets for conducting these assessments is not always viable and can prove to be prohibitively expensive and time-consuming. In this paper, we present a unified approach to evaluate embedders. First, we establish theoretical foundations for comparing embedding models, drawing upon the concepts of sufficiency and informativeness. We then leverage these concepts to devise a tractable comparison criterion (information sufficiency), leading to a task-agnostic and self-supervised ranking procedure. We demonstrate experimentally that our approach aligns closely with the capability of embedding models to facilitate various downstream tasks in both natural language processing and molecular biology. This effectively offers practitioners a valuable tool for prioritizing model trials.
Read more6/13/2024

0
DeepVoting: Learning Voting Rules with Tailored Embeddings
Leonardo Matone, Ben Abramowitz, Nicholas Mattei, Avinash Balakrishnan
Aggregating the preferences of multiple agents into a collective decision is a common step in many important problems across areas of computer science including information retrieval, reinforcement learning, and recommender systems. As Social Choice Theory has shown, the problem of designing algorithms for aggregation rules with specific properties (axioms) can be difficult, or provably impossible in some cases. Instead of designing algorithms by hand, one can learn aggregation rules, particularly voting rules, from data. However, the prior work in this area has required extremely large models, or been limited by the choice of preference representation, i.e., embedding. We recast the problem of designing a good voting rule into one of learning probabilistic versions of voting rules that output distributions over a set of candidates. Specifically, we use neural networks to learn probabilistic social choice functions from the literature. We show that embeddings of preference profiles derived from the social choice literature allows us to learn existing voting rules more efficiently and scale to larger populations of voters more easily than other work if the embedding is tailored to the learning objective. Moreover, we show that rules learned using embeddings can be tweaked to create novel voting rules with improved axiomatic properties. Namely, we show that existing voting rules require only minor modification to combat a probabilistic version of the No Show Paradox.
Read more8/27/2024

0
Performance Prediction of Hub-Based Swarms
Puneet Jain, Chaitanya Dwivedi, Vigynesh Bhatt, Nick Smith, Michael A Goodrich
A hub-based colony consists of multiple agents who share a common nest site called the hub. Agents perform tasks away from the hub like foraging for food or gathering information about future nest sites. Modeling hub-based colonies is challenging because the size of the collective state space grows rapidly as the number of agents grows. This paper presents a graph-based representation of the colony that can be combined with graph-based encoders to create low-dimensional representations of collective state that can scale to many agents for a best-of-N colony problem. We demonstrate how the information in the low-dimensional embedding can be used with two experiments. First, we show how the information in the tensor can be used to cluster collective states by the probability of choosing the best site for a very small problem. Second, we show how structured collective trajectories emerge when a graph encoder is used to learn the low-dimensional embedding, and these trajectories have information that can be used to predict swarm performance.
Read more8/12/2024