Sequential Decision Making with Expert Demonstrations under Unobserved Heterogeneity

0
Sign in to get full access
Overview
- This paper explores sequential decision-making problems where an agent learns from expert demonstrations, but there is unobserved heterogeneity in the environment or the expert's preferences.
- The authors propose a Bayesian framework that can capture this unobserved heterogeneity and learn the optimal policy for the agent.
- Key contributions include a theoretically-grounded approach, efficient algorithms, and empirical validation on simulated and real-world tasks.
Plain English Explanation
In many real-world decision-making problems, an agent (such as a robot or AI system) may have access to demonstrations from expert humans, who can show the agent how to perform a task effectively. However, the environment the agent operates in or the expert's preferences may have hidden factors that are not directly observable.
For example, imagine a robot learning to navigate a warehouse. The expert demonstration videos may not fully capture all the subtle obstacles or layout changes that the robot will encounter. Or the expert's preferences for optimal routes could be influenced by factors like fatigue or personal biases that are not obvious.
The authors of this paper have developed a new Bayesian framework to help the agent deal with this "unobserved heterogeneity." Their approach allows the agent to build a probabilistic model that can capture these hidden factors, and then use that model to learn the optimal policy for its decision-making.
This is a significant advancement, as previous methods struggled to handle such hidden complexities in real-world settings. The authors demonstrate the effectiveness of their framework through both theoretical analysis and practical experiments, showing how it can outperform existing techniques on a range of simulated and real-world tasks.
Technical Explanation
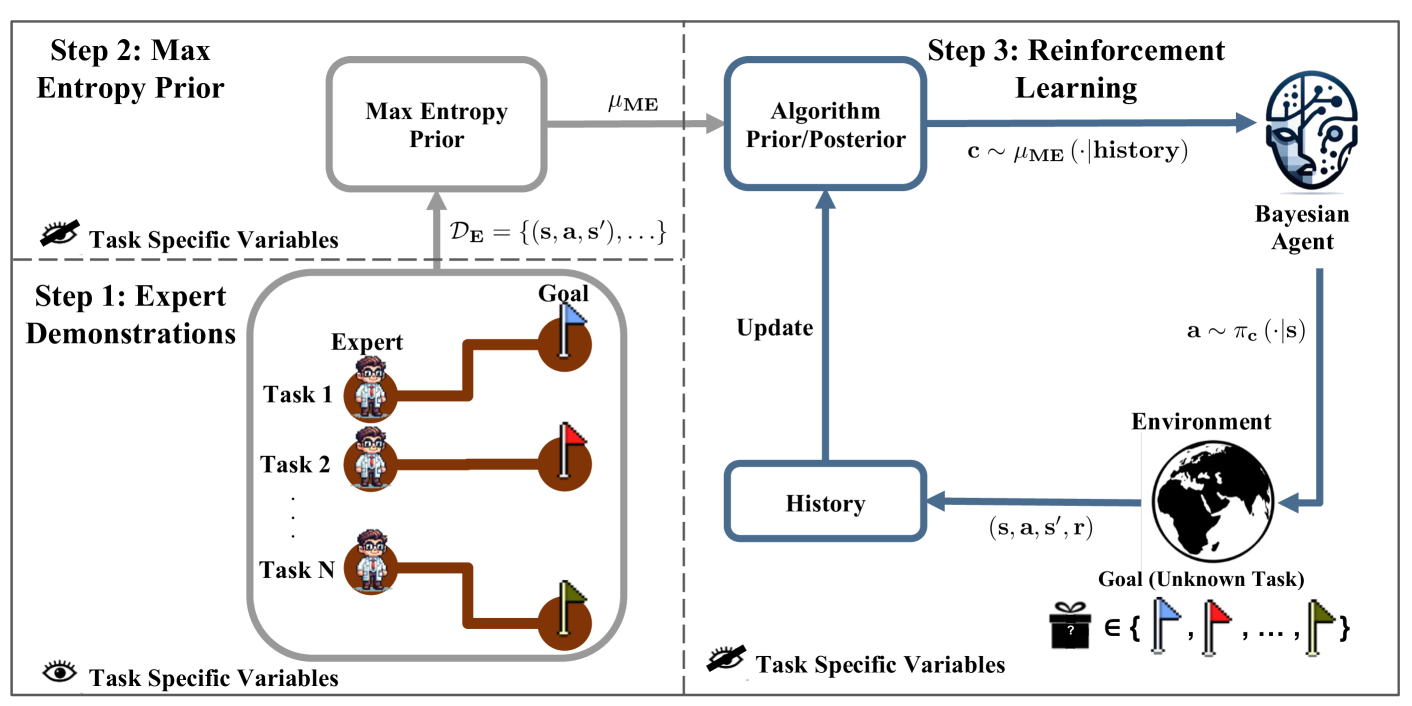
The core of the authors' approach is a Bayesian nonparametric framework that can model the unobserved heterogeneity in the environment and the expert's preferences. Specifically, they define a latent variable model where the agent's rewards and the expert's demonstrations are generated from an unknown, potentially complex distribution.
To learn this distribution, the authors propose an efficient inference algorithm based on variational methods. This allows the agent to jointly estimate the hidden factors and learn the optimal policy for its decision-making, without requiring full observability of the environment or the expert's true objectives.
The authors provide theoretical guarantees on the convergence and regret bounds of their approach, and validate its performance through extensive experiments. They consider simulated environments as well as real-world tasks, such as robot navigation and dialog systems, where the agent must learn from expert demonstrations in the presence of unobserved heterogeneity.
The results demonstrate that the authors' Bayesian framework significantly outperforms previous state-of-the-art methods, highlighting its practical relevance for a wide range of sequential decision-making problems under partial observability.
Critical Analysis
The authors acknowledge several limitations and avenues for future work. For instance, their framework assumes the unobserved heterogeneity can be captured by a latent variable model, which may not always be the case in complex, real-world settings. Additionally, the inference algorithm, while efficient, may still be computationally expensive for large-scale problems.
Another potential concern is the reliance on expert demonstrations, which may not always be available or representative of the true optimal behavior. In such cases, the agent's learning performance could be affected by the quality and coverage of the demonstrations.
Further research could explore ways to relax the assumptions of the latent variable model, perhaps by investigating other probabilistic frameworks or by incorporating active exploration techniques to better identify the hidden factors. Combining this Bayesian approach with active exploration methods could be a promising direction.
Additionally, extending the framework to handle group decision-making scenarios or exploring variational approaches for self-supervised exploration could further broaden the applicability of this research.
Conclusion
This paper presents a novel Bayesian framework for sequential decision-making problems where an agent learns from expert demonstrations in the presence of unobserved heterogeneity. By modeling the hidden factors that influence the environment and the expert's preferences, the authors have developed a principled approach that can outperform existing methods on a range of tasks.
The theoretical analysis and empirical results showcase the potential of this research to advance the field of inverse reinforcement learning and sequential decision-making under partial observability. While there are still some limitations to address, this work represents an important step towards more robust and adaptable AI systems that can learn effectively from human experts in complex, real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sequential Decision Making with Expert Demonstrations under Unobserved Heterogeneity
Vahid Balazadeh, Keertana Chidambaram, Viet Nguyen, Rahul G. Krishnan, Vasilis Syrgkanis
We study the problem of online sequential decision-making given auxiliary demonstrations from experts who made their decisions based on unobserved contextual information. These demonstrations can be viewed as solving related but slightly different tasks than what the learner faces. This setting arises in many application domains, such as self-driving cars, healthcare, and finance, where expert demonstrations are made using contextual information, which is not recorded in the data available to the learning agent. We model the problem as a zero-shot meta-reinforcement learning setting with an unknown task distribution and a Bayesian regret minimization objective, where the unobserved tasks are encoded as parameters with an unknown prior. We propose the Experts-as-Priors algorithm (ExPerior), a non-parametric empirical Bayes approach that utilizes the principle of maximum entropy to establish an informative prior over the learner's decision-making problem. This prior enables the application of any Bayesian approach for online decision-making, such as posterior sampling. We demonstrate that our strategy surpasses existing behaviour cloning and online algorithms for multi-armed bandits and reinforcement learning, showcasing the utility of our approach in leveraging expert demonstrations across different decision-making setups.
Read more4/12/2024
🏅
0
A Bayesian Approach to Robust Inverse Reinforcement Learning
Ran Wei, Siliang Zeng, Chenliang Li, Alfredo Garcia, Anthony McDonald, Mingyi Hong
We consider a Bayesian approach to offline model-based inverse reinforcement learning (IRL). The proposed framework differs from existing offline model-based IRL approaches by performing simultaneous estimation of the expert's reward function and subjective model of environment dynamics. We make use of a class of prior distributions which parameterizes how accurate the expert's model of the environment is to develop efficient algorithms to estimate the expert's reward and subjective dynamics in high-dimensional settings. Our analysis reveals a novel insight that the estimated policy exhibits robust performance when the expert is believed (a priori) to have a highly accurate model of the environment. We verify this observation in the MuJoCo environments and show that our algorithms outperform state-of-the-art offline IRL algorithms.
Read more4/9/2024
0
Learning to Steer Markovian Agents under Model Uncertainty
Jiawei Huang, Vinzenz Thoma, Zebang Shen, Heinrich H. Nax, Niao He
Designing incentives for an adapting population is a ubiquitous problem in a wide array of economic applications and beyond. In this work, we study how to design additional rewards to steer multi-agent systems towards desired policies emph{without} prior knowledge of the agents' underlying learning dynamics. We introduce a model-based non-episodic Reinforcement Learning (RL) formulation for our steering problem. Importantly, we focus on learning a emph{history-dependent} steering strategy to handle the inherent model uncertainty about the agents' learning dynamics. We introduce a novel objective function to encode the desiderata of achieving a good steering outcome with reasonable cost. Theoretically, we identify conditions for the existence of steering strategies to guide agents to the desired policies. Complementing our theoretical contributions, we provide empirical algorithms to approximately solve our objective, which effectively tackles the challenge in learning history-dependent strategies. We demonstrate the efficacy of our algorithms through empirical evaluations.
Read more7/16/2024

0
Sequential sampling without comparison to boundary through model-free reinforcement learning
Jamal Esmaily, Rani Moran, Yasser Roudi, Bahador Bahrami
Although evidence integration to the boundary model has successfully explained a wide range of behavioral and neural data in decision making under uncertainty, how animals learn and optimize the boundary remains unresolved. Here, we propose a model-free reinforcement learning algorithm for perceptual decisions under uncertainty that dispenses entirely with the concepts of decision boundary and evidence accumulation. Our model learns whether to commit to a decision given the available evidence or continue sampling information at a cost. We reproduced the canonical features of perceptual decision-making such as dependence of accuracy and reaction time on evidence strength, modulation of speed-accuracy trade-off by payoff regime, and many others. By unifying learning and decision making within the same framework, this model can account for unstable behavior during training as well as stabilized post-training behavior, opening the door to revisiting the extensive volumes of discarded training data in the decision science literature.
Read more8/13/2024