Meta Reinforcement Learning with Finite Training Tasks -- a Density Estimation Approach
2206.10716
0
0
🏅
Abstract
In meta reinforcement learning (meta RL), an agent learns from a set of training tasks how to quickly solve a new task, drawn from the same task distribution. The optimal meta RL policy, a.k.a. the Bayes-optimal behavior, is well defined, and guarantees optimal reward in expectation, taken with respect to the task distribution. The question we explore in this work is how many training tasks are required to guarantee approximately optimal behavior with high probability. Recent work provided the first such PAC analysis for a model-free setting, where a history-dependent policy was learned from the training tasks. In this work, we propose a different approach: directly learn the task distribution, using density estimation techniques, and then train a policy on the learned task distribution. We show that our approach leads to bounds that depend on the dimension of the task distribution. In particular, in settings where the task distribution lies in a low-dimensional manifold, we extend our analysis to use dimensionality reduction techniques and account for such structure, obtaining significantly better bounds than previous work, which strictly depend on the number of states and actions. The key of our approach is the regularization implied by the kernel density estimation method. We further demonstrate that this regularization is useful in practice, when `plugged in' the state-of-the-art VariBAD meta RL algorithm.
Create account to get full access
Overview
- In meta reinforcement learning (meta-RL), an agent learns from a set of training tasks how to quickly solve a new task drawn from the same distribution.
- The optimal meta-RL policy, known as Bayes-optimal behavior, guarantees optimal reward in expectation over the task distribution.
- This paper explores how many training tasks are required to achieve approximately optimal behavior with high probability.
- The authors propose a new approach that directly learns the task distribution using density estimation techniques, then trains a policy on the learned distribution.
Plain English Explanation
Imagine you're teaching a robot how to navigate a variety of mazes. Instead of showing it every single maze, you show it a bunch of similar mazes and let it figure out the general strategies for solving them quickly. This is the idea behind meta-RL.
The "best" way for the robot to navigate any new maze would be to have a perfect understanding of the overall maze distribution. This "optimal" behavior is called Bayes-optimal. The key question is: how many example mazes does the robot need to see before it can reliably solve any new maze with near-optimal performance?
The authors propose a new approach where the robot first learns a model of the maze distribution using statistical techniques. It then uses this learned distribution to train a policy that can quickly solve new mazes. This approach can lead to significantly better performance than previous methods, especially when the true maze distribution has an underlying low-dimensional structure.
The key insight is that the statistical modeling process inherently regularizes the learned distribution, preventing the robot from over-fitting to the training examples. This regularization proves very useful in practice when plugged into state-of-the-art meta-RL algorithms.
Technical Explanation
The paper presents a new approach to meta-RL that directly models the task distribution using density estimation techniques, rather than learning a history-dependent policy as in prior work.
The authors show that this distribution-based approach leads to bounds on the number of training tasks required for near-optimal performance that depend on the dimensionality of the task distribution, rather than the number of states and actions. In settings where the true task distribution has low-dimensional structure, this allows for significantly better sample complexity bounds compared to previous methods.
The key insight is that the regularization inherent in kernel density estimation helps prevent overfitting to the training tasks. The authors leverage this by incorporating the learned task distribution into the VariBAD meta-RL algorithm, demonstrating improved performance in practice.
Critical Analysis
The paper provides a strong theoretical analysis and compelling empirical results. However, a few potential limitations are worth noting:
- The analysis assumes access to an "oracle" that can perfectly sample from the true task distribution. In practice, this distribution may be difficult to estimate, especially in high-dimensional settings.
- The experiments focus on relatively simple maze navigation tasks. It remains to be seen how well the approach scales to more complex, real-world decision-making problems.
- The proposed method relies on the task distribution having low-dimensional structure. While this may hold in some domains, it may not be the case more generally.
Further research could explore more practical task sampling methods, apply the approach to a wider range of meta-RL benchmarks, and investigate the implications of the low-dimensional assumption in greater depth.
Conclusion
This paper presents a novel meta-RL approach that directly models the task distribution using density estimation techniques. By leveraging the inherent regularization of this approach, the authors are able to obtain significantly better sample complexity bounds compared to previous work, especially when the true task distribution has low-dimensional structure.
The proposed method shows promising results when incorporated into a state-of-the-art meta-RL algorithm. While there are a few potential limitations to consider, this research represents an important step forward in understanding the theoretical foundations of meta-RL and developing more efficient algorithms for this setting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Constrained Meta Agnostic Reinforcement Learning
Karam Daaboul, Florian Kuhm, Tim Joseph, J. Marius Zoellner
0
0
Meta-Reinforcement Learning (Meta-RL) aims to acquire meta-knowledge for quick adaptation to diverse tasks. However, applying these policies in real-world environments presents a significant challenge in balancing rapid adaptability with adherence to environmental constraints. Our novel approach, Constraint Model Agnostic Meta Learning (C-MAML), merges meta learning with constrained optimization to address this challenge. C-MAML enables rapid and efficient task adaptation by incorporating task-specific constraints directly into its meta-algorithm framework during the training phase. This fusion results in safer initial parameters for learning new tasks. We demonstrate the effectiveness of C-MAML in simulated locomotion with wheeled robot tasks of varying complexity, highlighting its practicality and robustness in dynamic environments.
6/21/2024
🏅
The Power of Active Multi-Task Learning in Reinforcement Learning from Human Feedback
Ruitao Chen, Liwei Wang
0
0
Reinforcement learning from human feedback (RLHF) has contributed to performance improvements in large language models. To tackle its reliance on substantial amounts of human-labeled data, a successful approach is multi-task representation learning, which involves learning a high-quality, low-dimensional representation from a wide range of source tasks. In this paper, we formulate RLHF as the contextual dueling bandit problem and assume a common linear representation. We demonstrate that the sample complexity of source tasks in multi-task RLHF can be reduced by considering task relevance and allocating different sample sizes to source tasks with varying task relevance. We further propose an algorithm to estimate task relevance by a small number of additional data and then learn a policy. We prove that to achieve $varepsilon-$optimal, the sample complexity of the source tasks can be significantly reduced compared to uniform sampling. Additionally, the sample complexity of the target task is only linear in the dimension of the latent space, thanks to representation learning.
5/21/2024
🧪
More Flexible PAC-Bayesian Meta-Learning by Learning Learning Algorithms
Hossein Zakerinia, Amin Behjati, Christoph H. Lampert
0
0
We introduce a new framework for studying meta-learning methods using PAC-Bayesian theory. Its main advantage over previous work is that it allows for more flexibility in how the transfer of knowledge between tasks is realized. For previous approaches, this could only happen indirectly, by means of learning prior distributions over models. In contrast, the new generalization bounds that we prove express the process of meta-learning much more directly as learning the learning algorithm that should be used for future tasks. The flexibility of our framework makes it suitable to analyze a wide range of meta-learning mechanisms and even design new mechanisms. Other than our theoretical contributions we also show empirically that our framework improves the prediction quality in practical meta-learning mechanisms.
5/30/2024
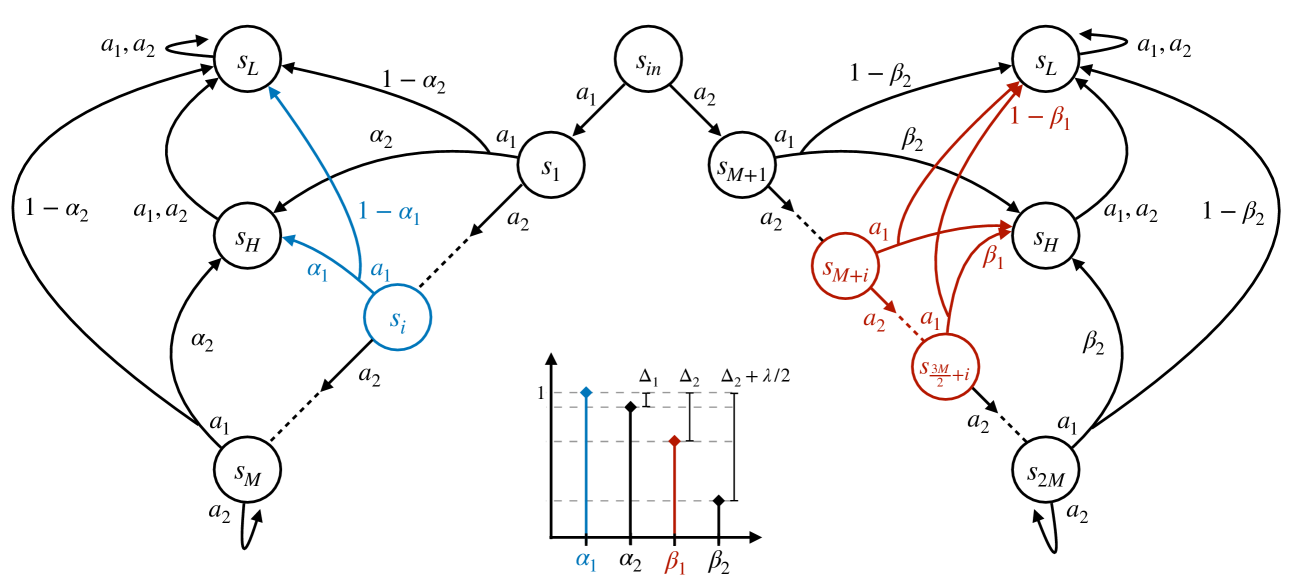
Test-Time Regret Minimization in Meta Reinforcement Learning
Mirco Mutti, Aviv Tamar
0
0
Meta reinforcement learning sets a distribution over a set of tasks on which the agent can train at will, then is asked to learn an optimal policy for any test task efficiently. In this paper, we consider a finite set of tasks modeled through Markov decision processes with various dynamics. We assume to have endured a long training phase, from which the set of tasks is perfectly recovered, and we focus on regret minimization against the optimal policy in the unknown test task. Under a separation condition that states the existence of a state-action pair revealing a task against another, Chen et al. (2022) show that $O(M^2 log(H))$ regret can be achieved, where $M, H$ are the number of tasks in the set and test episodes, respectively. In our first contribution, we demonstrate that the latter rate is nearly optimal by developing a novel lower bound for test-time regret minimization under separation, showing that a linear dependence with $M$ is unavoidable. Then, we present a family of stronger yet reasonable assumptions beyond separation, which we call strong identifiability, enabling algorithms achieving fast rates $log (H)$ and sublinear dependence with $M$ simultaneously. Our paper provides a new understanding of the statistical barriers of test-time regret minimization and when fast rates can be achieved.
6/5/2024