Learning from Contrastive Prompts: Automated Optimization and Adaptation

0
Sign in to get full access
Overview
- This paper explores a novel approach to training large language models (LLMs) by leveraging contrastive prompts.
- The authors present an automated method for optimizing and adapting prompts to improve the performance of LLMs on various tasks.
- The proposed technique, called "Learning from Contrastive Prompts" (LCP), aims to enhance the versatility and effectiveness of LLMs.
Plain English Explanation
The paper introduces a new way to train large language models (LLMs) that can help them perform better on different tasks. The key idea is to use contrastive prompts - prompts that present the model with a pair of related inputs and ask it to identify the differences between them.
By training LLMs on these contrastive prompts, the authors show that the models can learn to better understand the nuances of language and adapt more effectively to new tasks. This is important because LLMs are often used for a wide variety of applications, from text generation to question answering, and their performance can vary widely depending on the specific task.
The paper presents an automated method for optimizing and adapting these contrastive prompts to further improve the LLM's performance. This involves using techniques like meta-prompting to automatically generate and refine the prompts based on the model's responses.
The key benefit of this approach is that it can make LLMs more versatile and effective, allowing them to perform better across a wider range of tasks and applications.
Technical Explanation
The paper proposes a novel technique called "Learning from Contrastive Prompts" (LCP) to train large language models (LLMs) more effectively. The core idea is to use contrastive prompts - prompts that present the model with a pair of related inputs and ask it to identify the differences between them.
During the training process, the LLM is exposed to these contrastive prompts and learns to better understand the nuances of language and the relationships between different concepts. This, in turn, allows the model to adapt more effectively to new tasks and perform better across a wider range of applications.
To further enhance the performance of LLMs, the authors present an automated method for optimizing and adapting the contrastive prompts. This involves using techniques like meta-prompting, where the model is trained to generate and refine the prompts based on its own responses.
The paper presents extensive experiments demonstrating the effectiveness of the LCP approach. The authors show that LLMs trained with LCP outperform their counterparts trained on traditional prompts across a variety of tasks, including text generation, question answering, and language understanding.
Critical Analysis
The paper presents a compelling approach to improving the performance of large language models, but it's important to consider some potential limitations and areas for further research.
One key concern is the scalability of the LCP method. While the automated prompt optimization is a promising approach, it may become computationally expensive as the model and prompt space grow. The authors acknowledge this and suggest exploring ways to make the process more efficient.
Additionally, the paper focuses on evaluating the LCP approach on a relatively narrow set of tasks. It would be valuable to see how the technique performs on a broader range of applications, including more complex or domain-specific tasks, to fully assess its versatility and adaptability.
Another area for further exploration is the interpretability of the LCP-trained models. Understanding how the models are learning and reasoning with the contrastive prompts could provide valuable insights and help guide future research in this area.
Despite these potential limitations, the LCP approach represents an important step forward in the ongoing efforts to enhance the capabilities and robustness of large language models. The authors' work highlights the potential of leveraging contrastive learning techniques to improve model performance and adaptability, which could have significant implications for a wide range of AI applications.
Conclusion
The paper introduces a novel approach called "Learning from Contrastive Prompts" (LCP) that aims to improve the performance of large language models (LLMs) by leveraging contrastive prompts during the training process. The authors present an automated method for optimizing and adapting these prompts to further enhance the LLM's versatility and effectiveness.
The results presented in the paper demonstrate the potential of the LCP approach, showing that LLMs trained with this technique outperform their counterparts on a variety of tasks. This work represents an important step forward in the ongoing effort to develop more capable and adaptable language models, with potential implications for a wide range of AI applications.
While the paper identifies some potential limitations and areas for further research, the LCP approach is a promising direction that could help unlock new levels of performance and versatility in large language models, ultimately leading to more powerful and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning from Contrastive Prompts: Automated Optimization and Adaptation
Mingqi Li, Karan Aggarwal, Yong Xie, Aitzaz Ahmad, Stephen Lau
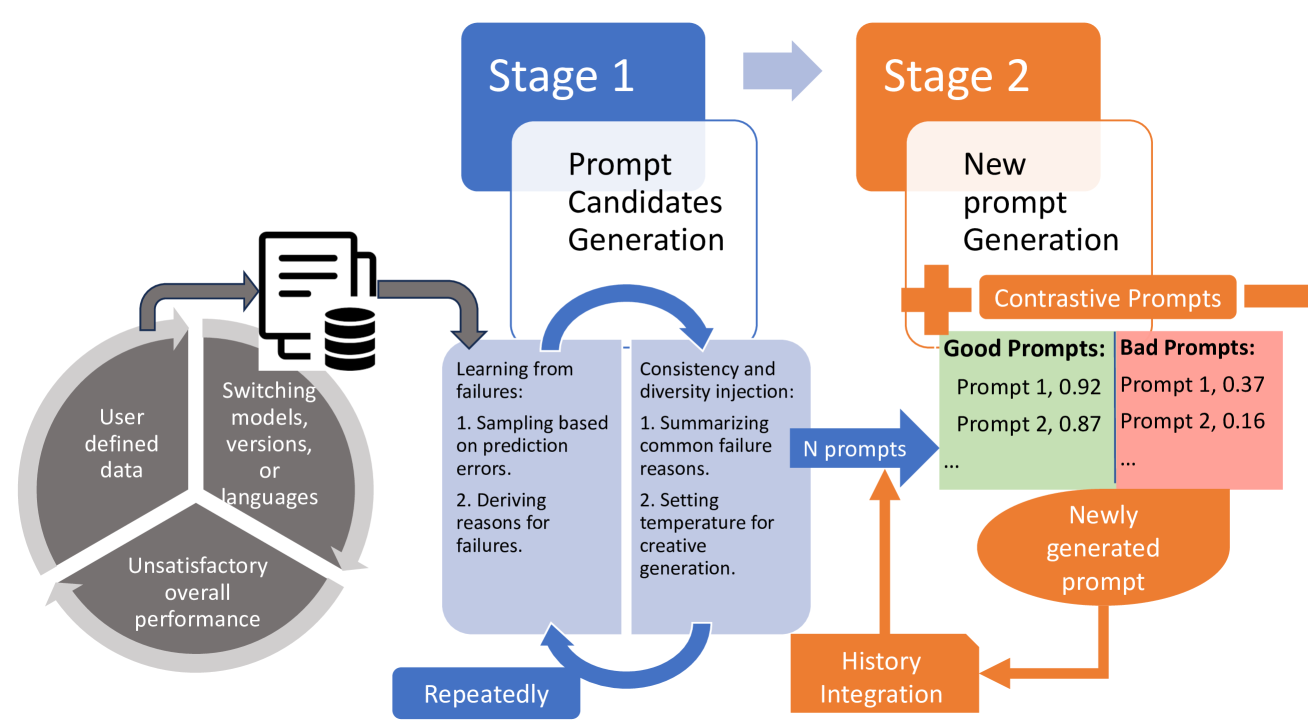
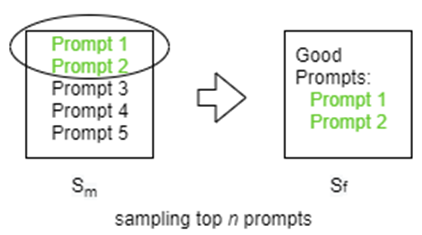
As LLMs evolve, significant effort is spent on manually crafting prompts. While existing prompt optimization methods automate this process, they rely solely on learning from incorrect samples, leading to a sub-optimal performance. Additionally, an unexplored challenge in the literature is prompts effective for prior models may not perform well on newer versions or different languages. We propose the Learning from Contrastive Prompts (LCP) framework to address these gaps, enhancing both prompt optimization and adaptation. LCP employs contrastive learning to generate effective prompts by analyzing patterns in good and bad prompt examples. Our evaluation on the Big-Bench Hard dataset shows that LCP has a win rate of over 76% over existing methods in prompt optimization and demonstrates strong adaptability across different model versions, families, and languages. LCP offers a systematic approach to prompt engineering, reducing manual effort in deploying LLMs across varied contexts.
Read more9/24/2024
0
Large Language Models are Contrastive Reasoners
Liang Yao
Prompting methods play a crucial role in enhancing the capabilities of pre-trained large language models (LLMs). We explore how contrastive prompting (CP) significantly improves the ability of large language models to perform complex reasoning. We demonstrate that LLMs are decent contrastive reasoners by simply adding Let's give a correct and a wrong answer. before LLMs provide answers. Experiments on various large language models show that zero-shot contrastive prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks without any hand-crafted few-shot examples, such as increasing the accuracy on GSM8K from 35.9% to 88.8% and AQUA-RAT from 41.3% to 62.2% with the state-of-the-art GPT-4 model. Our method not only surpasses zero-shot CoT and few-shot CoT in most arithmetic and commonsense reasoning tasks but also can seamlessly integrate with existing prompting methods, resulting in improved or comparable results when compared to state-of-the-art methods. Our code is available at https://github.com/yao8839836/cp
Read more5/24/2024
0
Optimising Hard Prompts with Few-Shot Meta-Prompting
Sayash Raaj Hiraou
Prompting is a flexible and adaptable way of providing instructions to a Large Language Model (LLM). Contextual prompts include context in the form of a document or dialogue along with the natural language instructions to the LLM, often constraining the LLM to restrict facts to that of the given context while complying with the instructions. Masking the context, it acts as template for prompts. In this paper, we present an iterative method to generate better templates using an LLM from an existing set of prompt templates without revealing the context to the LLM. Multiple methods of optimising prompts using the LLM itself are explored to check the effect of few shot sampling methods on iterative propagation while maintaining linguistic styles and syntax on optimisation of prompt templates, yielding a 103.87% improvement using the best performing method. Comparison of the results of multiple contextual tasks demonstrate the ability of LLMs to maintain syntax while learning to replicate linguistic styles. Additionally, the effect on the output with different methods of prompt template generation is shown.
Read more7/30/2024

0
One Prompt is not Enough: Automated Construction of a Mixture-of-Expert Prompts
Ruochen Wang, Sohyun An, Minhao Cheng, Tianyi Zhou, Sung Ju Hwang, Cho-Jui Hsieh
Large Language Models (LLMs) exhibit strong generalization capabilities to novel tasks when prompted with language instructions and in-context demos. Since this ability sensitively depends on the quality of prompts, various methods have been explored to automate the instruction design. While these methods demonstrated promising results, they also restricted the searched prompt to one instruction. Such simplification significantly limits their capacity, as a single demo-free instruction might not be able to cover the entire complex problem space of the targeted task. To alleviate this issue, we adopt the Mixture-of-Expert paradigm and divide the problem space into a set of sub-regions; Each sub-region is governed by a specialized expert, equipped with both an instruction and a set of demos. A two-phase process is developed to construct the specialized expert for each region: (1) demo assignment: Inspired by the theoretical connection between in-context learning and kernel regression, we group demos into experts based on their semantic similarity; (2) instruction assignment: A region-based joint search of an instruction per expert complements the demos assigned to it, yielding a synergistic effect. The resulting method, codenamed Mixture-of-Prompts (MoP), achieves an average win rate of 81% against prior arts across several major benchmarks.
Read more7/2/2024