Optimising Hard Prompts with Few-Shot Meta-Prompting

0
Sign in to get full access
Overview
- The paper explores a technique called "few-shot meta-prompting" to optimize "hard prompts" for language models.
- Hard prompts are prompts that are difficult for language models to understand and respond to effectively.
- The authors propose a method to automatically generate and refine these challenging prompts to improve the language model's performance.
Plain English Explanation
The paper looks at a way to make it easier for language models, like those used in chatbots and virtual assistants, to understand and respond to complex or "hard" prompts. These are prompts that can be difficult for the language model to interpret and generate a good response to.
The researchers developed a technique called "few-shot meta-prompting" that allows them to automatically generate and refine these challenging prompts. This helps the language model adapt and learn to process the prompts more efficiently. The key idea is to create a small set of example prompts that the language model can use to better understand and rewrite the hard prompts for improved performance.
The researchers tested their method on language models performing tasks like introductory computer science problems and found it could significantly boost the model's abilities. This approach could help make language models more capable of handling complex, nuanced prompts in real-world applications.
Technical Explanation
The paper introduces a technique called "few-shot meta-prompting" to optimize "hard prompts" for language models. Hard prompts are those that are difficult for language models to understand and respond to effectively.
The authors propose a two-stage process:
-
Prompt Rewriting: Given a hard prompt, the method generates a set of "meta-prompts" - a small number of related prompts that the language model can use as examples. These meta-prompts are designed to help the model better understand and rephrase the original hard prompt.
-
Prompt Optimization: The language model is then fine-tuned on the set of meta-prompts. This allows the model to learn how to effectively process and respond to the style of the hard prompt.
The authors evaluate their approach on tasks like solving introductory computer science problems. They find that few-shot meta-prompting can significantly boost the language model's performance on these challenging prompts compared to standard fine-tuning approaches.
Critical Analysis
The paper presents a novel and promising approach to improving language model performance on hard prompts. The key strengths are:
- Automated Prompt Generation: The ability to automatically generate meta-prompts to help language models better understand challenging inputs is a valuable contribution.
- Few-Shot Learning: Leveraging a small set of example prompts for fine-tuning, rather than requiring large amounts of training data, makes the approach more practical and scalable.
- Diverse Evaluation: Testing the method on a range of tasks, including introductory programming problems, demonstrates its broad applicability.
However, the paper could be strengthened by addressing a few potential limitations:
- Prompt Diversity: It's unclear how well the method would generalize to an even wider range of "hard" prompt types beyond those evaluated in the paper.
- Computational Costs: The additional step of generating and fine-tuning on meta-prompts could increase the computational overhead compared to standard fine-tuning approaches.
- Interpretability: The paper does not provide much insight into why certain meta-prompts are more effective than others at improving model performance.
Overall, the few-shot meta-prompting approach shows promising results and could be an important step towards making language models more robust and capable of handling complex, real-world prompts.
Conclusion
This paper introduces a novel technique called "few-shot meta-prompting" to optimize language models for "hard prompts" - inputs that are challenging for the models to understand and respond to effectively. By automatically generating a small set of related "meta-prompts" and fine-tuning the model on these examples, the approach can significantly boost the model's performance on tasks like solving introductory computer science problems.
The method demonstrates the value of leveraging few-shot learning to help language models better adapt to and process complex prompts, which could have important implications for improving the capabilities of chatbots, virtual assistants, and other real-world applications of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimising Hard Prompts with Few-Shot Meta-Prompting
Sayash Raaj Hiraou
Prompting is a flexible and adaptable way of providing instructions to a Large Language Model (LLM). Contextual prompts include context in the form of a document or dialogue along with the natural language instructions to the LLM, often constraining the LLM to restrict facts to that of the given context while complying with the instructions. Masking the context, it acts as template for prompts. In this paper, we present an iterative method to generate better templates using an LLM from an existing set of prompt templates without revealing the context to the LLM. Multiple methods of optimising prompts using the LLM itself are explored to check the effect of few shot sampling methods on iterative propagation while maintaining linguistic styles and syntax on optimisation of prompt templates, yielding a 103.87% improvement using the best performing method. Comparison of the results of multiple contextual tasks demonstrate the ability of LLMs to maintain syntax while learning to replicate linguistic styles. Additionally, the effect on the output with different methods of prompt template generation is shown.
Read more7/30/2024

0
One Prompt is not Enough: Automated Construction of a Mixture-of-Expert Prompts
Ruochen Wang, Sohyun An, Minhao Cheng, Tianyi Zhou, Sung Ju Hwang, Cho-Jui Hsieh
Large Language Models (LLMs) exhibit strong generalization capabilities to novel tasks when prompted with language instructions and in-context demos. Since this ability sensitively depends on the quality of prompts, various methods have been explored to automate the instruction design. While these methods demonstrated promising results, they also restricted the searched prompt to one instruction. Such simplification significantly limits their capacity, as a single demo-free instruction might not be able to cover the entire complex problem space of the targeted task. To alleviate this issue, we adopt the Mixture-of-Expert paradigm and divide the problem space into a set of sub-regions; Each sub-region is governed by a specialized expert, equipped with both an instruction and a set of demos. A two-phase process is developed to construct the specialized expert for each region: (1) demo assignment: Inspired by the theoretical connection between in-context learning and kernel regression, we group demos into experts based on their semantic similarity; (2) instruction assignment: A region-based joint search of an instruction per expert complements the demos assigned to it, yielding a synergistic effect. The resulting method, codenamed Mixture-of-Prompts (MoP), achieves an average win rate of 81% against prior arts across several major benchmarks.
Read more7/2/2024
0
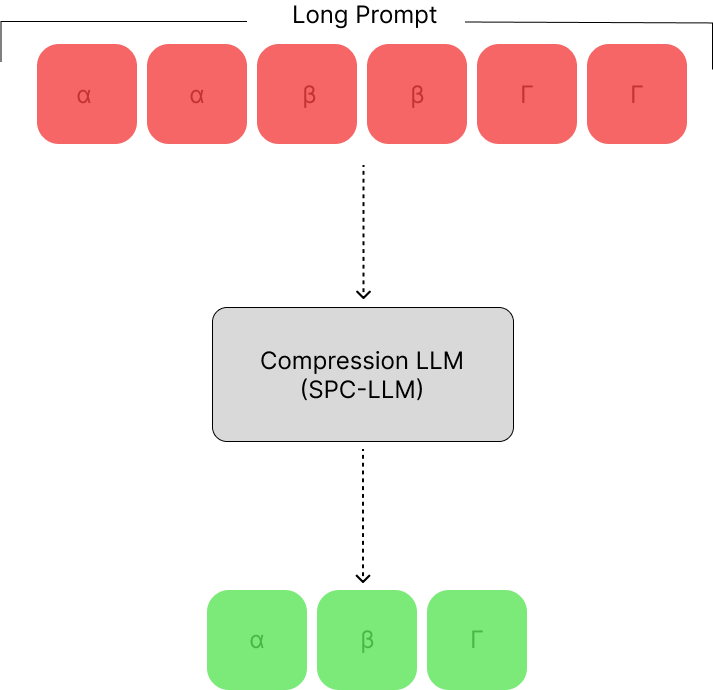
Adapting LLMs for Efficient Context Processing through Soft Prompt Compression
Cangqing Wang, Yutian Yang, Ruisi Li, Dan Sun, Ruicong Cai, Yuzhu Zhang, Chengqian Fu, Lillian Floyd
The rapid advancement of Large Language Models (LLMs) has inaugurated a transformative epoch in natural language processing, fostering unprecedented proficiency in text generation, comprehension, and contextual scrutiny. Nevertheless, effectively handling extensive contexts, crucial for myriad applications, poses a formidable obstacle owing to the intrinsic constraints of the models' context window sizes and the computational burdens entailed by their operations. This investigation presents an innovative framework that strategically tailors LLMs for streamlined context processing by harnessing the synergies among natural language summarization, soft prompt compression, and augmented utility preservation mechanisms. Our methodology, dubbed SoftPromptComp, amalgamates natural language prompts extracted from summarization methodologies with dynamically generated soft prompts to forge a concise yet semantically robust depiction of protracted contexts. This depiction undergoes further refinement via a weighting mechanism optimizing information retention and utility for subsequent tasks. We substantiate that our framework markedly diminishes computational overhead and enhances LLMs' efficacy across various benchmarks, while upholding or even augmenting the caliber of the produced content. By amalgamating soft prompt compression with sophisticated summarization, SoftPromptComp confronts the dual challenges of managing lengthy contexts and ensuring model scalability. Our findings point towards a propitious trajectory for augmenting LLMs' applicability and efficiency, rendering them more versatile and pragmatic for real-world applications. This research enriches the ongoing discourse on optimizing language models, providing insights into the potency of soft prompts and summarization techniques as pivotal instruments for the forthcoming generation of NLP solutions.
Read more4/22/2024

0
Instances Need More Care: Rewriting Prompts for Instances with LLMs in the Loop Yields Better Zero-Shot Performance
Saurabh Srivastava, Chengyue Huang, Weiguo Fan, Ziyu Yao
Large language models (LLMs) have revolutionized zero-shot task performance, mitigating the need for task-specific annotations while enhancing task generalizability. Despite its advancements, current methods using trigger phrases such as Let's think step by step remain limited. This study introduces PRomPTed, an approach that optimizes the zero-shot prompts for individual task instances following an innovative manner of LLMs in the loop. Our comprehensive evaluation across 13 datasets and 10 task types based on GPT-4 reveals that PRomPTed significantly outperforms both the naive zero-shot approaches and a strong baseline (i.e., Output Refinement) which refines the task output instead of the input prompt. Our experimental results also confirmed the generalization of this advantage to the relatively weaker GPT-3.5. Even more intriguingly, we found that leveraging GPT-3.5 to rewrite prompts for the stronger GPT-4 not only matches but occasionally exceeds the efficacy of using GPT-4 as the prompt rewriter. Our research thus presents a huge value in not only enhancing zero-shot LLM performance but also potentially enabling supervising LLMs with their weaker counterparts, a capability attracting much interest recently. Finally, our additional experiments confirm the generalization of the advantages to open-source LLMs such as Mistral 7B and Mixtral 8x7B.
Read more6/13/2024