Tendency-driven Mutual Exclusivity for Weakly Supervised Incremental Semantic Segmentation

0

Sign in to get full access
Overview
- This paper presents a novel approach for weakly supervised incremental semantic segmentation, called Tendency-driven Mutual Exclusivity (TME).
- TME leverages the tendency of pixels to belong to mutually exclusive object classes, which helps the model learn more efficiently from limited training data.
- The method is designed to be used in an incremental learning setting, where new object classes are added to the model over time.
Plain English Explanation
Semantic segmentation is the task of identifying and classifying different objects within an image. Traditional methods for this task require large amounts of labeled training data, which can be expensive and time-consuming to collect.
The authors of this paper propose a new approach called Tendency-driven Mutual Exclusivity (TME) that can learn to perform semantic segmentation with less training data. The key idea behind TME is that pixels in an image tend to belong to only one object class at a time - for example, a pixel cannot be both a car and a person.
By incorporating this "mutual exclusivity" constraint into the model, TME can learn more efficiently from the limited training data available. This makes it particularly useful in an incremental learning setting, where new object classes are added to the model over time. As the model encounters new classes, it can leverage the mutual exclusivity principle to quickly adapt and learn to identify them, without forgetting the classes it had learned previously.
The authors demonstrate the effectiveness of TME on several semantic segmentation benchmarks, showing that it can outperform other weakly supervised approaches while requiring less training data.
Technical Explanation
The paper introduces a novel method called Tendency-driven Mutual Exclusivity (TME) for weakly supervised incremental semantic segmentation. TME builds on the observation that pixels in an image tend to belong to only a single object class, a property known as mutual exclusivity.
The authors leverage this mutual exclusivity tendency to guide the model's learning process in an incremental setting. As new object classes are added to the model over time, TME enforces the constraint that pixels should be assigned to at most one class. This helps the model learn more efficiently from the limited training data available for each new class, without forgetting the classes it had learned previously.
The TME framework consists of two key components:
- A tendency module that estimates the tendency of each pixel to belong to each object class, based on the model's current predictions.
- A mutual exclusivity loss that penalizes the model for assigning a pixel to multiple object classes, encouraging it to respect the mutual exclusivity principle.
The authors evaluate TME on several semantic segmentation benchmarks, including PASCAL VOC, COCO, and ADE20K. They show that TME outperforms other weakly supervised approaches while requiring less training data, demonstrating the effectiveness of leveraging the mutual exclusivity tendency in an incremental learning setting.
Critical Analysis
The key strength of the TME approach is its ability to efficiently learn new object classes in an incremental setting by exploiting the mutual exclusivity tendency of pixels. This is a valuable contribution, as real-world applications often require models to adapt to new classes over time without forgetting previous knowledge.
However, the paper does not address several potential limitations and areas for further research. For example, it is unclear how TME would perform in cases where the mutual exclusivity assumption is violated, such as in images with overlapping or partially occluded objects. Additionally, the paper does not explore the scalability of the approach as the number of object classes grows, or how it might handle classes with significant visual similarities.
Further research could also investigate ways to make the tendency module more robust and adaptive, potentially by incorporating additional cues or learning the tendencies in a more data-driven manner. Exploring the integration of TME with other weakly supervised or incremental learning techniques may also lead to further improvements.
Conclusion
The Tendency-driven Mutual Exclusivity (TME) method presented in this paper offers a novel approach to weakly supervised incremental semantic segmentation. By leveraging the mutual exclusivity tendency of pixels, TME can learn new object classes efficiently while maintaining performance on previously learned classes.
The results demonstrate the effectiveness of this approach, but also highlight areas for further research to address potential limitations and expand the applicability of the method. As models continue to be deployed in real-world settings that require adaptability and efficiency, techniques like TME will become increasingly important for advancing the state of the art in semantic segmentation and other computer vision tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tendency-driven Mutual Exclusivity for Weakly Supervised Incremental Semantic Segmentation
Chongjie Si, Xuehui Wang, Xiaokang Yang, Wei Shen
Weakly Incremental Learning for Semantic Segmentation (WILSS) leverages a pre-trained segmentation model to segment new classes using cost-effective and readily available image-level labels. A prevailing way to solve WILSS is the generation of seed areas for each new class, serving as a form of pixel-level supervision. However, a scenario usually arises where a pixel is concurrently predicted as an old class by the pre-trained segmentation model and a new class by the seed areas. Such a scenario becomes particularly problematic in WILSS, as the lack of pixel-level annotations on new classes makes it intractable to ascertain whether the pixel pertains to the new class or not. To surmount this issue, we propose an innovative, tendency-driven relationship of mutual exclusivity, meticulously tailored to govern the behavior of the seed areas and the predictions generated by the pre-trained segmentation model. This relationship stipulates that predictions for the new and old classes must not conflict whilst prioritizing the preservation of predictions for the old classes, which not only addresses the conflicting prediction issue but also effectively mitigates the inherent challenge of incremental learning - catastrophic forgetting. Furthermore, under the auspices of this tendency-driven mutual exclusivity relationship, we generate pseudo masks for the new classes, allowing for concurrent execution with model parameter updating via the resolution of a bi-level optimization problem. Extensive experiments substantiate the effectiveness of our framework, resulting in the establishment of new benchmarks and paving the way for further research in this field.
Read more4/22/2024
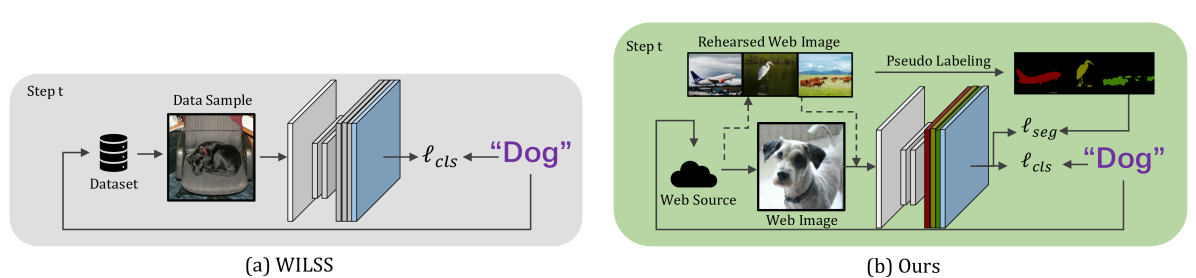
0
Learning from the Web: Language Drives Weakly-Supervised Incremental Learning for Semantic Segmentation
Chang Liu, Giulia Rizzoli, Pietro Zanuttigh, Fu Li, Yi Niu
Current weakly-supervised incremental learning for semantic segmentation (WILSS) approaches only consider replacing pixel-level annotations with image-level labels, while the training images are still from well-designed datasets. In this work, we argue that widely available web images can also be considered for the learning of new classes. To achieve this, firstly we introduce a strategy to select web images which are similar to previously seen examples in the latent space using a Fourier-based domain discriminator. Then, an effective caption-driven reharsal strategy is proposed to preserve previously learnt classes. To our knowledge, this is the first work to rely solely on web images for both the learning of new concepts and the preservation of the already learned ones in WILSS. Experimental results show that the proposed approach can reach state-of-the-art performances without using manually selected and annotated data in the incremental steps.
Read more9/4/2024
👨🏫
0
Enhancing Weakly Supervised Semantic Segmentation with Multi-modal Foundation Models: An End-to-End Approach
Elham Ravanbakhsh, Cheng Niu, Yongqing Liang, J. Ramanujam, Xin Li
Semantic segmentation is a core computer vision problem, but the high costs of data annotation have hindered its wide application. Weakly-Supervised Semantic Segmentation (WSSS) offers a cost-efficient workaround to extensive labeling in comparison to fully-supervised methods by using partial or incomplete labels. Existing WSSS methods have difficulties in learning the boundaries of objects leading to poor segmentation results. We propose a novel and effective framework that addresses these issues by leveraging visual foundation models inside the bounding box. Adopting a two-stage WSSS framework, our proposed network consists of a pseudo-label generation module and a segmentation module. The first stage leverages Segment Anything Model (SAM) to generate high-quality pseudo-labels. To alleviate the problem of delineating precise boundaries, we adopt SAM inside the bounding box with the help of another pre-trained foundation model (e.g., Grounding-DINO). Furthermore, we eliminate the necessity of using the supervision of image labels, by employing CLIP in classification. Then in the second stage, the generated high-quality pseudo-labels are used to train an off-the-shelf segmenter that achieves the state-of-the-art performance on PASCAL VOC 2012 and MS COCO 2014.
Read more5/13/2024

0
Weakly-supervised Semantic Segmentation via Dual-stream Contrastive Learning of Cross-image Contextual Information
Qi Lai, Chi-Man Vong
Weakly supervised semantic segmentation (WSSS) aims at learning a semantic segmentation model with only image-level tags. Despite intensive research on deep learning approaches over a decade, there is still a significant performance gap between WSSS and full semantic segmentation. Most current WSSS methods always focus on a limited single image (pixel-wise) information while ignoring the valuable inter-image (semantic-wise) information. From this perspective, a novel end-to-end WSSS framework called DSCNet is developed along with two innovations: i) pixel-wise group contrast and semantic-wise graph contrast are proposed and introduced into the WSSS framework; ii) a novel dual-stream contrastive learning (DSCL) mechanism is designed to jointly handle pixel-wise and semantic-wise context information for better WSSS performance. Specifically, the pixel-wise group contrast learning (PGCL) and semantic-wise graph contrast learning (SGCL) tasks form a more comprehensive solution. Extensive experiments on PASCAL VOC and MS COCO benchmarks verify the superiority of DSCNet over SOTA approaches and baseline models.
Read more5/9/2024