Learning Generalized Policies for Fully Observable Non-Deterministic Planning Domains

0
🌐
Sign in to get full access
Overview
- This paper explores a technique for learning generalized policies that can handle non-deterministic planning problems in fully observable environments.
- The proposed approach uses a neural network architecture to learn a policy that can adapt to different problem instances, rather than requiring a specialized solver for each scenario.
- The authors demonstrate the effectiveness of their method on a range of benchmark planning problems, showing it can outperform traditional planning algorithms.
Plain English Explanation
The paper presents a new way to tackle planning problems where the outcomes of actions are uncertain or unpredictable. In many real-world situations, like navigating a robot through a cluttered environment, the effects of an action may vary depending on factors we can't fully control.
Traditional planning algorithms struggle with this type of non-deterministic problem, as they require precise models of how the world works. The authors' approach instead uses machine learning to train a neural network that can learn a generalized policy - a decision-making strategy that can adapt to handle a wide range of possible outcomes.
The key idea is to train the neural network on many different problem instances, exposing it to the variability and uncertainty inherent in the domain. Over time, the network learns to recognize patterns and develop a flexible decision-making strategy that works well across a variety of scenarios, rather than being specialized for a single problem.
The authors show this learned policy outperforms classical planning algorithms on benchmark tasks. This suggests the potential for such generalized approaches to tackle complex real-world planning problems where the environment is not perfectly predictable.
Technical Explanation
The paper focuses on fully observable non-deterministic planning problems, where the current state of the world is known but the outcomes of actions are uncertain. The authors propose a neural network architecture called a Generalized Policy Network (GPN) that can learn a policy to handle such problems.
The GPN takes the current state as input and outputs a probability distribution over the available actions. During training, the network is exposed to many problem instances with varying dynamics, allowing it to learn patterns and develop a flexible decision-making strategy.
The core of the GPN is a recurrent neural network that maintains an internal state to track the history of the problem-solving process. This allows the policy to reason about and adapt to the evolving situation, rather than just reacting myopically to the current state.
The authors evaluate their approach on several benchmark planning domains, including probabilistic variants of classic problems like grid navigation and block puzzles. They show the GPN can outperform traditional planners that rely on precise models of the environment dynamics.
Critical Analysis
A key strength of the proposed approach is its ability to handle uncertainty and adapt to a wide range of problem instances. By learning a generalized policy, the system can be applied to new scenarios without requiring a specialized solver to be developed for each case.
However, the paper does note some limitations. The training process can be computationally intensive, as the network must be exposed to a diverse set of problem instances to learn a robust policy. Additionally, the performance of the GPN may degrade as the complexity or variability of the planning domain increases.
Further research could explore ways to improve the sample efficiency of the training process, perhaps by incorporating additional inductive biases or leveraging structured representations of the planning problem. It would also be valuable to test the approach on more complex real-world planning scenarios beyond the benchmark tasks presented here.
Overall, this work represents an interesting step towards more flexible and generalizable planning systems that can handle the uncertainties inherent in many real-world domains. The authors have demonstrated the potential of learned policies to outperform traditional planning algorithms, opening up new avenues for further exploration and application.
Conclusion
This paper introduces a neural network-based approach for learning generalized policies to solve non-deterministic planning problems in fully observable environments. By training the network on a diverse set of problem instances, the system can develop a flexible decision-making strategy that can adapt to handle uncertain outcomes.
The authors show their Generalized Policy Network outperforms classical planning algorithms on benchmark tasks, suggesting the potential for such learned policies to tackle complex real-world planning challenges where the environment is not perfectly predictable. While further research is needed to address limitations around training efficiency and scalability, this work represents an important advance in the field of planning under uncertainty.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Learning Generalized Policies for Fully Observable Non-Deterministic Planning Domains
Till Hofmann, Hector Geffner
General policies represent reactive strategies for solving large families of planning problems like the infinite collection of solvable instances from a given domain. Methods for learning such policies from a collection of small training instances have been developed successfully for classical domains. In this work, we extend the formulations and the resulting combinatorial methods for learning general policies over fully observable, non-deterministic (FOND) domains. We also evaluate the resulting approach experimentally over a number of benchmark domains in FOND planning, present the general policies that result in some of these domains, and prove their correctness. The method for learning general policies for FOND planning can actually be seen as an alternative FOND planning method that searches for solutions, not in the given state space but in an abstract space defined by features that must be learned as well.
Read more5/14/2024

0
Planning with a Learned Policy Basis to Optimally Solve Complex Tasks
Guillermo Infante, David Kuric, Anders Jonsson, Vicenc{c} G'omez, Herke van Hoof
Conventional reinforcement learning (RL) methods can successfully solve a wide range of sequential decision problems. However, learning policies that can generalize predictably across multiple tasks in a setting with non-Markovian reward specifications is a challenging problem. We propose to use successor features to learn a policy basis so that each (sub)policy in it solves a well-defined subproblem. In a task described by a finite state automaton (FSA) that involves the same set of subproblems, the combination of these (sub)policies can then be used to generate an optimal solution without additional learning. In contrast to other methods that combine (sub)policies via planning, our method asymptotically attains global optimality, even in stochastic environments.
Read more6/4/2024

0
Epistemic Exploration for Generalizable Planning and Learning in Non-Stationary Settings
Rushang Karia, Pulkit Verma, Alberto Speranzon, Siddharth Srivastava
This paper introduces a new approach for continual planning and model learning in relational, non-stationary stochastic environments. Such capabilities are essential for the deployment of sequential decision-making systems in the uncertain and constantly evolving real world. Working in such practical settings with unknown (and non-stationary) transition systems and changing tasks, the proposed framework models gaps in the agent's current state of knowledge and uses them to conduct focused, investigative explorations. Data collected using these explorations is used for learning generalizable probabilistic models for solving the current task despite continual changes in the environment dynamics. Empirical evaluations on several non-stationary benchmark domains show that this approach significantly outperforms planning and RL baselines in terms of sample complexity. Theoretical results show that the system exhibits desirable convergence properties when stationarity holds.
Read more6/10/2024
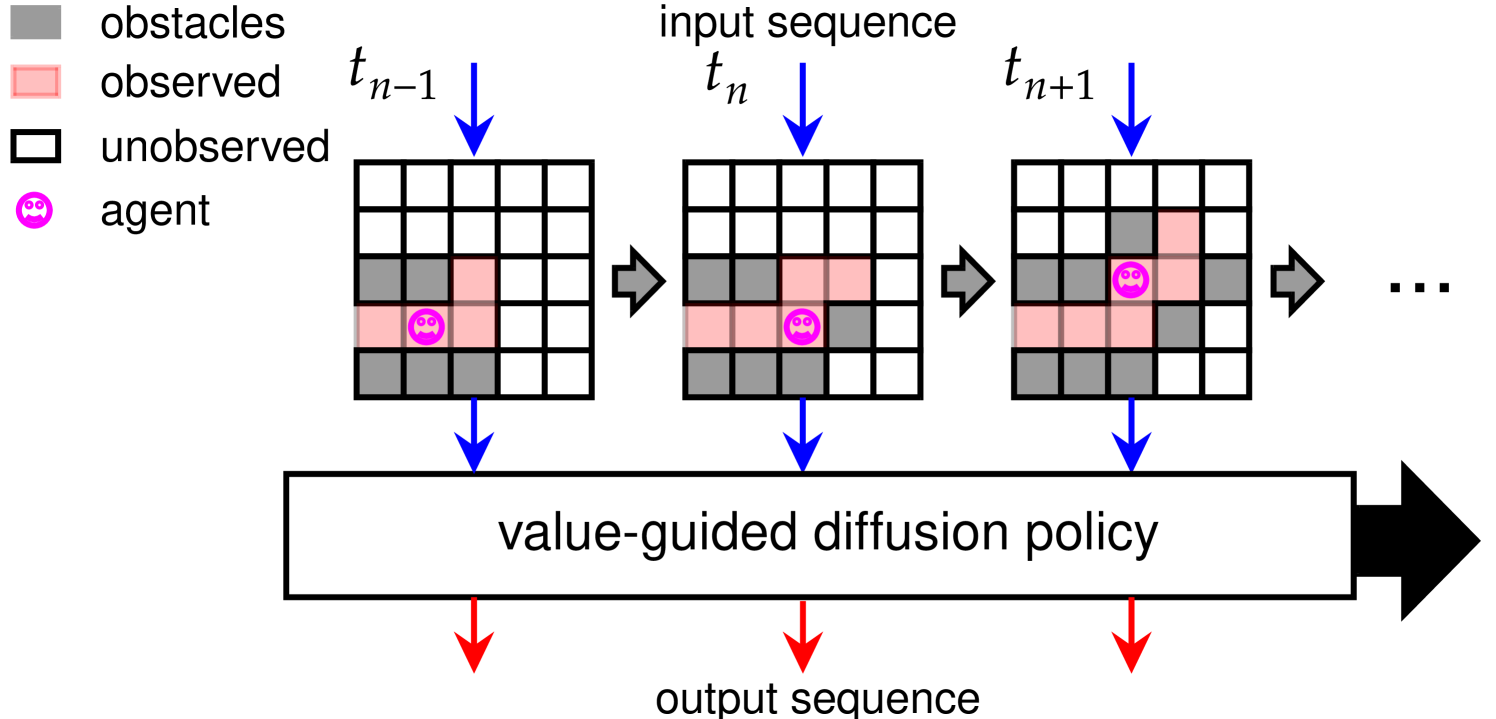
0
Versatile Navigation under Partial Observability via Value-guided Diffusion Policy
Gengyu Zhang, Hao Tang, Yan Yan
Route planning for navigation under partial observability plays a crucial role in modern robotics and autonomous driving. Existing route planning approaches can be categorized into two main classes: traditional autoregressive and diffusion-based methods. The former often fails due to its myopic nature, while the latter either assumes full observability or struggles to adapt to unfamiliar scenarios, due to strong couplings with behavior cloning from experts. To address these deficiencies, we propose a versatile diffusion-based approach for both 2D and 3D route planning under partial observability. Specifically, our value-guided diffusion policy first generates plans to predict actions across various timesteps, providing ample foresight to the planning. It then employs a differentiable planner with state estimations to derive a value function, directing the agent's exploration and goal-seeking behaviors without seeking experts while explicitly addressing partial observability. During inference, our policy is further enhanced by a best-plan-selection strategy, substantially boosting the planning success rate. Moreover, we propose projecting point clouds, derived from RGB-D inputs, onto 2D grid-based bird-eye-view maps via semantic segmentation, generalizing to 3D environments. This simple yet effective adaption enables zero-shot transfer from 2D-trained policy to 3D, cutting across the laborious training for 3D policy, and thus certifying our versatility. Experimental results demonstrate our superior performance, particularly in navigating situations beyond expert demonstrations, surpassing state-of-the-art autoregressive and diffusion-based baselines for both 2D and 3D scenarios.
Read more4/4/2024