Learning Joint Models of Prediction and Optimization

0

Sign in to get full access
Overview
- This paper proposes a novel approach called EPO (Efficient Prediction and Optimization) that learns joint models for prediction and optimization.
- The key idea is to train a single model that can both accurately predict outcomes and efficiently solve optimization problems, rather than treating these as separate tasks.
- The paper demonstrates the effectiveness of EPO on several real-world problems, including hyperparameter tuning and portfolio optimization.
Plain English Explanation
Learning joint models of prediction and optimization is a technical paper that introduces a new approach called EPO (Efficient Prediction and Optimization). The core insight is that many real-world problems involve both making predictions and then optimizing some desired outcome based on those predictions.
Rather than treating these as separate tasks, the EPO method trains a single model that can do both - accurately predict the outcomes of different decisions, and then efficiently find the optimal decision that maximizes the desired outcome. This is in contrast to traditional approaches that use one model for prediction and a separate optimization algorithm.
By learning a joint model for prediction and optimization, the EPO method can be more efficient and effective than the traditional approach. The paper demonstrates this on several example problems, such as tuning the hyperparameters of a machine learning model, and optimizing an investment portfolio. In these cases, EPO was able to find better solutions more quickly than the standard approach of using separate prediction and optimization components.
The key advantage of EPO is that it allows the prediction and optimization components to work together and reinforce each other, rather than operating in isolation. This can lead to improved performance and faster convergence to the optimal solution. Overall, the EPO framework represents an interesting advance in the field of decision-making and optimization, with potential applications across a variety of domains.
Technical Explanation
The paper introduces the EPO (Efficient Prediction and Optimization) framework, which learns a single joint model to perform both prediction and optimization. This is in contrast to traditional approaches that use separate models or algorithms for these two tasks.
The key technical insight is to frame the optimization problem as a differentiable objective that can be integrated directly into the training of the prediction model. Specifically, the model is trained to not only accurately predict outcomes, but also to produce outputs that optimize some desired objective function.
This is achieved by backpropagating gradients from the optimization objective through the prediction model during training. The authors show that this allows the prediction and optimization components to co-evolve and reinforce each other, leading to improved performance compared to decoupled approaches.
The paper demonstrates the effectiveness of EPO on several real-world problems, including hyperparameter tuning for machine learning models and portfolio optimization. In these experiments, EPO was able to find better solutions more efficiently than traditional methods that treated prediction and optimization as separate steps.
One key technical contribution is the use of "optimization proxies" - differentiable functions that approximate the true optimization objective. This allows the gradient-based training of the joint model, even when the true objective is non-differentiable or expensive to evaluate.
Overall, the EPO framework represents an interesting advance in the field of decision-making and optimization, by learning a single model that can both predict outcomes and optimize for desired objectives. The authors highlight several promising directions for future research, such as extending EPO to handle multiple objectives and richer problem structures.
Critical Analysis
The EPO paper presents a compelling approach for jointly learning prediction and optimization models. The key insight of backpropagating gradients from the optimization objective through the prediction model is novel and effective.
One potential limitation is the reliance on "optimization proxies" - differentiable functions that approximate the true optimization objective. While this allows for gradient-based training, it raises questions about how well the proxies capture the true underlying optimization problem. The authors acknowledge this as an area for future research, and suggest exploring methods to make the proxies more accurate and problem-specific.
Additionally, the paper focuses on single-objective optimization problems. Extending EPO to handle multi-objective scenarios, where there may be tradeoffs between competing objectives, could significantly broaden its applicability. The authors mention this as a direction for future work, but do not provide details on how such an extension could be implemented.
Another area for further exploration is the interpretability and explainability of the EPO models. As these are complex joint models, it may be challenging to understand the reasoning behind their predictions and optimization decisions. Developing techniques to improve the interpretability of EPO models could be valuable, especially in domains where transparency is important, such as finance or healthcare.
Despite these potential limitations, the EPO paper represents an important step forward in the field of decision-making and optimization. By learning a single model that can perform both prediction and optimization, the EPO approach has the potential to significantly improve the efficiency and effectiveness of real-world problem-solving.
Conclusion
Learning joint models of prediction and optimization introduces a novel framework called EPO (Efficient Prediction and Optimization) that learns a single model to perform both prediction and optimization tasks. This is in contrast to traditional approaches that treat these as separate steps.
The key technical contribution is the backpropagation of gradients from the optimization objective through the prediction model during training, allowing the two components to co-evolve and reinforce each other. The paper demonstrates the effectiveness of EPO on several real-world problems, showing that it can find better solutions more efficiently than decoupled methods.
While the paper presents a promising approach, there are areas for further research, such as improving the accuracy of optimization proxies, extending EPO to handle multi-objective scenarios, and enhancing the interpretability of the joint models. Nonetheless, the EPO framework represents an important advance in the field of decision-making and optimization, with the potential to drive significant improvements in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Joint Models of Prediction and Optimization
James Kotary, Vincenzo Di Vito, Jacob Cristopher, Pascal Van Hentenryck, Ferdinando Fioretto
The Predict-Then-Optimize framework uses machine learning models to predict unknown parameters of an optimization problem from exogenous features before solving. This setting is common to many real-world decision processes, and recently it has been shown that decision quality can be substantially improved by solving and differentiating the optimization problem within an end-to-end training loop. However, this approach requires significant computational effort in addition to handcrafted, problem-specific rules for backpropagation through the optimization step, challenging its applicability to a broad class of optimization problems. This paper proposes an alternative method, in which optimal solutions are learned directly from the observable features by joint predictive models. The approach is generic, and based on an adaptation of the Learning-to-Optimize paradigm, from which a rich variety of existing techniques can be employed. Experimental evaluations show the ability of several Learning-to-Optimize methods to provide efficient and accurate solutions to an array of challenging Predict-Then-Optimize problems.
Read more9/10/2024

0
From Learning to Optimize to Learning Optimization Algorithms
Camille Castera, Peter Ochs
Towards designing learned optimization algorithms that are usable beyond their training setting, we identify key principles that classical algorithms obey, but have up to now, not been used for Learning to Optimize (L2O). Following these principles, we provide a general design pipeline, taking into account data, architecture and learning strategy, and thereby enabling a synergy between classical optimization and L2O, resulting in a philosophy of Learning Optimization Algorithms. As a consequence our learned algorithms perform well far beyond problems from the training distribution. We demonstrate the success of these novel principles by designing a new learning-enhanced BFGS algorithm and provide numerical experiments evidencing its adaptation to many settings at test time.
Read more5/29/2024

0
Differentiation of Multi-objective Data-driven Decision Pipeline
Peng Li, Lixia Wu, Chaoqun Feng, Haoyuan Hu, Lei Fu, Jieping Ye
Real-world scenarios frequently involve multi-objective data-driven optimization problems, characterized by unknown problem coefficients and multiple conflicting objectives. Traditional two-stage methods independently apply a machine learning model to estimate problem coefficients, followed by invoking a solver to tackle the predicted optimization problem. The independent use of optimization solvers and prediction models may lead to suboptimal performance due to mismatches between their objectives. Recent efforts have focused on end-to-end training of predictive models that use decision loss derived from the downstream optimization problem. However, these methods have primarily focused on single-objective optimization problems, thus limiting their applicability. We aim to propose a multi-objective decision-focused approach to address this gap. In order to better align with the inherent properties of multi-objective optimization problems, we propose a set of novel loss functions. These loss functions are designed to capture the discrepancies between predicted and true decision problems, considering solution space, objective space, and decision quality, named landscape loss, Pareto set loss, and decision loss, respectively. Our experimental results demonstrate that our proposed method significantly outperforms traditional two-stage methods and most current decision-focused methods.
Read more6/4/2024
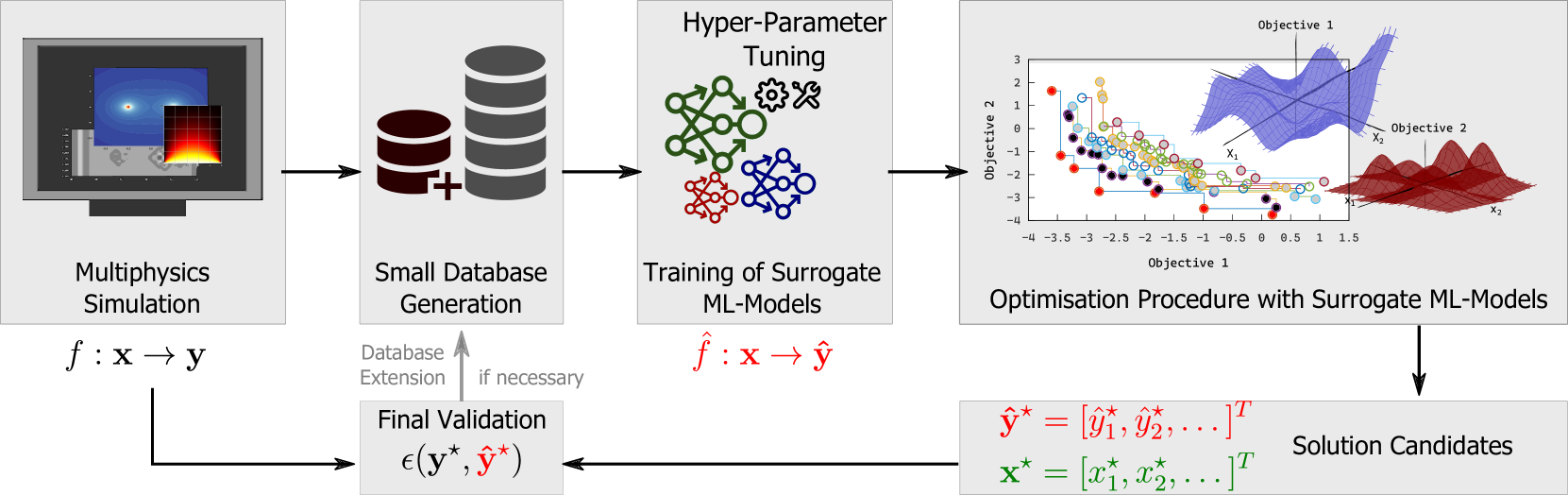
0
Enhancing Multi-Objective Optimization through Machine Learning-Supported Multiphysics Simulation
Diego Botache, Jens Decke, Winfried Ripken, Abhinay Dornipati, Franz Gotz-Hahn, Mohamed Ayeb, Bernhard Sick
This paper presents a methodological framework for training, self-optimising, and self-organising surrogate models to approximate and speed up multiobjective optimisation of technical systems based on multiphysics simulations. At the hand of two real-world datasets, we illustrate that surrogate models can be trained on relatively small amounts of data to approximate the underlying simulations accurately. Including explainable AI techniques allow for highlighting feature relevancy or dependencies and supporting the possible extension of the used datasets. One of the datasets was created for this paper and is made publicly available for the broader scientific community. Extensive experiments combine four machine learning and deep learning algorithms with an evolutionary optimisation algorithm. The performance of the combined training and optimisation pipeline is evaluated by verifying the generated Pareto-optimal results using the ground truth simulations. The results from our pipeline and a comprehensive evaluation strategy show the potential for efficiently acquiring solution candidates in multiobjective optimisation tasks by reducing the number of simulations and conserving a higher prediction accuracy, i.e., with a MAPE score under 5% for one of the presented use cases.
Read more4/4/2024