Learning k-Determinantal Point Processes for Personalized Ranking

0

Sign in to get full access
Overview
- This paper introduces a novel approach to personalized ranking using Determinantal Point Processes (DPPs).
- DPPs are a class of probabilistic models that can capture the notion of diversity and relevance in item selection.
- The authors propose a method to learn the parameters of a k-DPP (a variant of DPP that selects k items) for personalized ranking tasks.
- The approach aims to optimize an objective function that balances relevance and diversity, leading to personalized recommendation lists that are both relevant and diverse for each user.
Plain English Explanation
The paper discusses a way to personalize the ranking of items (e.g., products, articles, etc.) for individual users. The key idea is to use a mathematical model called a Determinantal Point Process (DPP), which can capture the notion of diversity and relevance when selecting a set of items.
Imagine you're looking for a new book to read. You might want recommendations that are both highly relevant to your interests and cover a diverse range of topics. A standard recommendation system might simply suggest the most popular or highest-rated books, but this could lead to a list of very similar books. In contrast, a DPP-based system would try to find a set of books that are both relevant to you and cover a wide range of subjects, giving you a more diverse and interesting selection to choose from.
The authors of the paper develop a specific type of DPP called a "k-DPP", where the system selects k items (e.g., 10 book recommendations) that balance relevance and diversity. The key contribution is a method to learn the parameters of the k-DPP model for each user, so that the recommendations are tailored to their individual preferences.
By using this personalized DPP-based approach, the authors aim to provide users with recommendation lists that are both highly relevant and diverse, leading to a better overall experience.
Technical Explanation
The paper introduces a novel approach to personalized ranking using Determinantal Point Processes (DPPs). DPPs are a class of probabilistic models that can capture the notion of diversity and relevance in item selection. The authors propose a method to learn the parameters of a k-DPP (a variant of DPP that selects k items) for personalized ranking tasks.
The key idea is to optimize an objective function that balances relevance and diversity, leading to personalized recommendation lists that are both relevant and diverse for each user. Specifically, the authors formulate the problem as learning the parameters of a k-DPP model that maximizes the log-likelihood of the observed user preferences, subject to a constraint on the diversity of the selected items.
The authors conduct extensive experiments on several real-world datasets, comparing their DPP-based approach to various baselines, including matrix factorization and other ranking methods. The results show that the proposed method outperforms the baselines in terms of both relevance and diversity of the recommendations, demonstrating the effectiveness of the DPP-based personalization approach.
Critical Analysis
The paper presents a promising approach to personalized ranking using DPPs, but there are a few potential limitations and areas for further research:
-
Scalability: The authors mention that learning the parameters of the k-DPP model can be computationally expensive, especially for large-scale applications. Developing more efficient optimization techniques or approximation methods could be an important direction for future work.
-
Interpretability: DPPs can be seen as "black-box" models, making it challenging to understand the underlying factors driving the recommendations. Incorporating more interpretable components or providing explanations for the recommendations could enhance the trust and transparency of the system.
-
Robustness: The paper does not explore the robustness of the DPP-based approach to noisy or sparse user data, which is a common challenge in real-world recommender systems. Investigating the performance of the method under various data conditions could be valuable.
-
Generalization: The experiments in the paper focus on specific datasets and recommendation tasks. Exploring the applicability of the DPP-based approach to a wider range of personalization scenarios, such as cross-domain recommendations or interactive recommender systems, could broaden the impact of this research.
Despite these potential limitations, the paper presents a compelling and well-designed study that demonstrates the potential of DPPs for personalized ranking. The authors' insights into balancing relevance and diversity could inspire further advancements in the field of personalized recommendations and diversity-aware ranking algorithms.
Conclusion
This paper presents a novel approach to personalized ranking using Determinantal Point Processes (DPPs). The key contribution is a method to learn the parameters of a k-DPP model that optimizes an objective function balancing relevance and diversity, leading to personalized recommendation lists that are both relevant and diverse for each user.
The empirical results demonstrate the effectiveness of the DPP-based personalization approach, outperforming various baselines in terms of both relevance and diversity. While the paper highlights a few potential limitations, the proposed method represents a promising step towards more personalized and diverse recommendation systems, which could have significant implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning k-Determinantal Point Processes for Personalized Ranking
Yuli Liu, Christian Walder, Lexing Xie
The key to personalized recommendation is to predict a personalized ranking on a catalog of items by modeling the user's preferences. There are many personalized ranking approaches for item recommendation from implicit feedback like Bayesian Personalized Ranking (BPR) and listwise ranking. Despite these methods have shown performance benefits, there are still limitations affecting recommendation performance. First, none of them directly optimize ranking of sets, causing inadequate exploitation of correlations among multiple items. Second, the diversity aspect of recommendations is insufficiently addressed compared to relevance. In this work, we present a new optimization criterion LkP based on set probability comparison for personalized ranking that moves beyond traditional ranking-based methods. It formalizes set-level relevance and diversity ranking comparisons through a Determinantal Point Process (DPP) kernel decomposition. To confer ranking interpretability to the DPP set probabilities and prioritize the practicality of LkP, we condition the standard DPP on the cardinality k of the DPP-distributed set, known as k-DPP, a less-explored extension of DPP. The generic stochastic gradient descent based technique can be directly applied to optimizing models that employ LkP. We implement LkP in the context of both Matrix Factorization (MF) and neural networks approaches, on three real-world datasets, obtaining improved relevance and diversity performances. LkP is broadly applicable, and when applied to existing recommendation models it also yields strong performance improvements, suggesting that LkP holds significant value to the field of recommender systems.
Read more6/26/2024
🌐
0
Naturally Private Recommendations with Determinantal Point Processes
Jack Fitzsimons, Agust'in Freitas Pasqualini, Robert Pisarczyk, Dmitrii Usynin
Often we consider machine learning models or statistical analysis methods which we endeavour to alter, by introducing a randomized mechanism, to make the model conform to a differential privacy constraint. However, certain models can often be implicitly differentially private or require significantly fewer alterations. In this work, we discuss Determinantal Point Processes (DPPs) which are dispersion models that balance recommendations based on both the popularity and the diversity of the content. We introduce DPPs, derive and discuss the alternations required for them to satisfy epsilon-Differential Privacy and provide an analysis of their sensitivity. We conclude by proposing simple alternatives to DPPs which would make them more efficient with respect to their privacy-utility trade-off.
Read more5/24/2024

0
A Family of Distributions of Random Subsets for Controlling Positive and Negative Dependence
Takahiro Kawashima, Hideitsu Hino
Positive and negative dependence are fundamental concepts that characterize the attractive and repulsive behavior of random subsets. Although some probabilistic models are known to exhibit positive or negative dependence, it is challenging to seamlessly bridge them with a practicable probabilistic model. In this study, we introduce a new family of distributions, named the discrete kernel point process (DKPP), which includes determinantal point processes and parts of Boltzmann machines. We also develop some computational methods for probabilistic operations and inference with DKPPs, such as calculating marginal and conditional probabilities and learning the parameters. Our numerical experiments demonstrate the controllability of positive and negative dependence and the effectiveness of the computational methods for DKPPs.
Read more8/6/2024
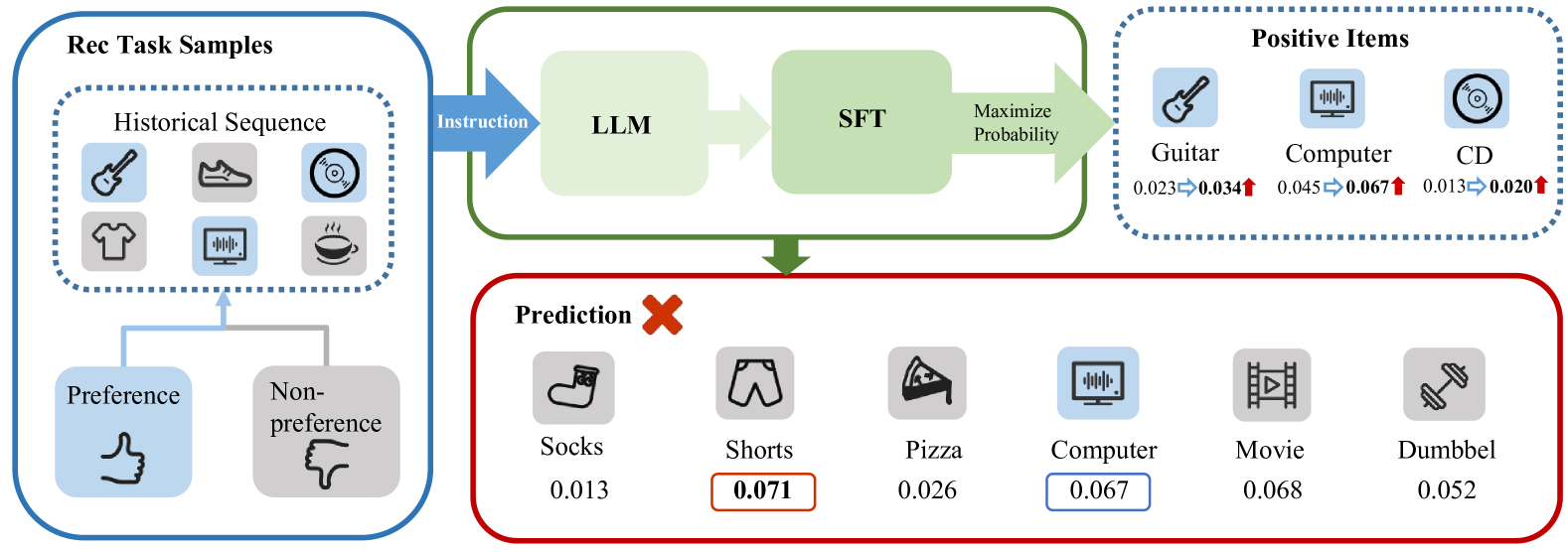
0
Finetuning Large Language Model for Personalized Ranking
Zhuoxi Bai, Ning Wu, Fengyu Cai, Xinyi Zhu, Yun Xiong
Large Language Models (LLMs) have demonstrated remarkable performance across various domains, motivating researchers to investigate their potential use in recommendation systems. However, directly applying LLMs to recommendation tasks has proven challenging due to the significant disparity between the data used for pre-training LLMs and the specific requirements of recommendation tasks. In this study, we introduce Direct Multi-Preference Optimization (DMPO), a streamlined framework designed to bridge the gap and enhance the alignment of LLMs for recommendation tasks. DMPO enhances the performance of LLM-based recommenders by simultaneously maximizing the probability of positive samples and minimizing the probability of multiple negative samples. We conducted experimental evaluations to compare DMPO against traditional recommendation methods and other LLM-based recommendation approaches. The results demonstrate that DMPO significantly improves the recommendation capabilities of LLMs across three real-world public datasets in few-shot scenarios. Additionally, the experiments indicate that DMPO exhibits superior generalization ability in cross-domain recommendations. A case study elucidates the reasons behind these consistent improvements and also underscores DMPO's potential as an explainable recommendation system.
Read more6/21/2024