Finetuning Large Language Model for Personalized Ranking
2405.16127
0
0
Abstract
Large Language Models (LLMs) have demonstrated remarkable performance across various domains, motivating researchers to investigate their potential use in recommendation systems. However, directly applying LLMs to recommendation tasks has proven challenging due to the significant disparity between the data used for pre-training LLMs and the specific requirements of recommendation tasks. In this study, we introduce Direct Multi-Preference Optimization (DMPO), a streamlined framework designed to bridge the gap and enhance the alignment of LLMs for recommendation tasks. DMPO enhances the performance of LLM-based recommenders by simultaneously maximizing the probability of positive samples and minimizing the probability of multiple negative samples. We conducted experimental evaluations to compare DMPO against traditional recommendation methods and other LLM-based recommendation approaches. The results demonstrate that DMPO significantly improves the recommendation capabilities of LLMs across three real-world public datasets in few-shot scenarios. Additionally, the experiments indicate that DMPO exhibits superior generalization ability in cross-domain recommendations. A case study elucidates the reasons behind these consistent improvements and also underscores DMPO's potential as an explainable recommendation system.
Create account to get full access
Introduction
This research paper explores a novel approach to personalizing the ranking of recommendations by finetuning large language models. Large language models (LLMs) have shown impressive capabilities in various natural language tasks, but applying them to personalized recommendation systems has remained a challenge. The key insight of this work is to leverage the expressive power of LLMs and directly optimize their preferences to align with user preferences, rather than relying on more traditional recommendation algorithms.
Related Work
Preference Optimization for Large Language Models
Recent research has explored ways to directly optimize the preferences of large language models to better align them with user preferences. This includes techniques like token-level direct preference optimization and multi-reference preference optimization. The current work builds on these advancements to apply preference optimization for personalized ranking.
Finetuning Language Models for Recommendation
Researchers have also investigated finetuning large language models for recommendation tasks, leveraging their ability to capture semantic relationships and user preferences. Techniques like Mallows DPO have shown promise in this area, demonstrating how LLMs can be directly optimized for preference alignment.
Plain English Explanation
This research aims to improve personalized recommendation systems by combining the power of large language models (LLMs) with a technique called "preference optimization." LLMs are AI models that can understand and generate human-like text, and they have proven to be very versatile.
The key idea here is to take an LLM and fine-tune it specifically for the task of ranking recommendations for individual users. Traditionally, recommendation systems have relied on algorithms that try to predict what a user might like based on their past behavior. However, this can be limited, as user preferences can be complex and difficult to capture fully.
By directly optimizing the preferences of the LLM, the researchers believe they can create a more personalized and accurate recommendation system. This means training the LLM to align its preferences with the preferences of each individual user, rather than just trying to predict what they might like.
The paper builds on previous work that has explored ways to directly optimize the preferences of LLMs, including techniques like "token-level direct preference optimization" and "multi-reference preference optimization." The researchers apply these ideas to the specific problem of personalized ranking, with the goal of creating recommendation systems that are better tailored to each user's unique tastes and interests.
Technical Explanation
The researchers propose a framework for finetuning large language models (LLMs) to perform personalized ranking for recommendation systems. They leverage recent advancements in direct preference optimization for LLMs, which aim to directly align the preferences of the model with user preferences, rather than relying on traditional recommendation algorithms.
The key elements of their approach include:
-
Preference Modeling: The researchers model user preferences using a ranking-based approach, where users provide pairwise preferences between items. This preference information is used to fine-tune the LLM.
-
Finetuning for Personalization: The LLM is finetuned on the user's preference data using techniques like token-level direct preference optimization and Mallows DPO. This allows the model to learn the user's unique preferences and ranking patterns.
-
Personalized Ranking: During inference, the finetuned LLM is used to rank recommendations for the user, with the model's preferences aligned to the user's own preferences through the finetuning process.
The researchers evaluate their approach on several real-world datasets and compare it to traditional recommendation algorithms. Their results demonstrate the effectiveness of finetuning LLMs for personalized ranking, outperforming baseline methods and highlighting the potential of this approach for building more tailored and accurate recommendation systems.
Critical Analysis
The researchers present a promising approach to leveraging the power of large language models for personalized recommendation systems. By directly optimizing the preferences of the LLM to align with user preferences, they are able to create more personalized and accurate ranking of recommendations.
One potential limitation of the approach is the reliance on user-provided pairwise preferences, which may not always be readily available or easy to collect. Exploring ways to infer user preferences from other sources, such as implicit feedback or user behavior, could further improve the practicality of this approach.
Additionally, the researchers note that the finetuning process can be computationally expensive, as it requires training the LLM on individual user preference data. Investigating more efficient finetuning techniques or alternative approaches to personalization could help address this scalability challenge.
Overall, this research represents an important step forward in applying large language models to the problem of personalized recommendation. By directly optimizing for user preferences, the approach has the potential to unlock new possibilities for building more tailored and engaging recommendation systems.
Conclusion
This research paper presents a novel approach to finetuning large language models for personalized ranking in recommendation systems. By leveraging recent advancements in direct preference optimization, the researchers demonstrate how LLMs can be fine-tuned to align their preferences with those of individual users, leading to more accurate and personalized recommendations.
The work builds on a growing body of research exploring the use of LLMs for recommendation tasks, and it highlights the potential of these powerful AI models to transform the way we personalize and deliver content to users. As the field of recommendation systems continues to evolve, techniques like the one described in this paper will likely play an increasingly important role in creating more tailored and engaging user experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
On Softmax Direct Preference Optimization for Recommendation
Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, Tat-Seng Chua
0
0
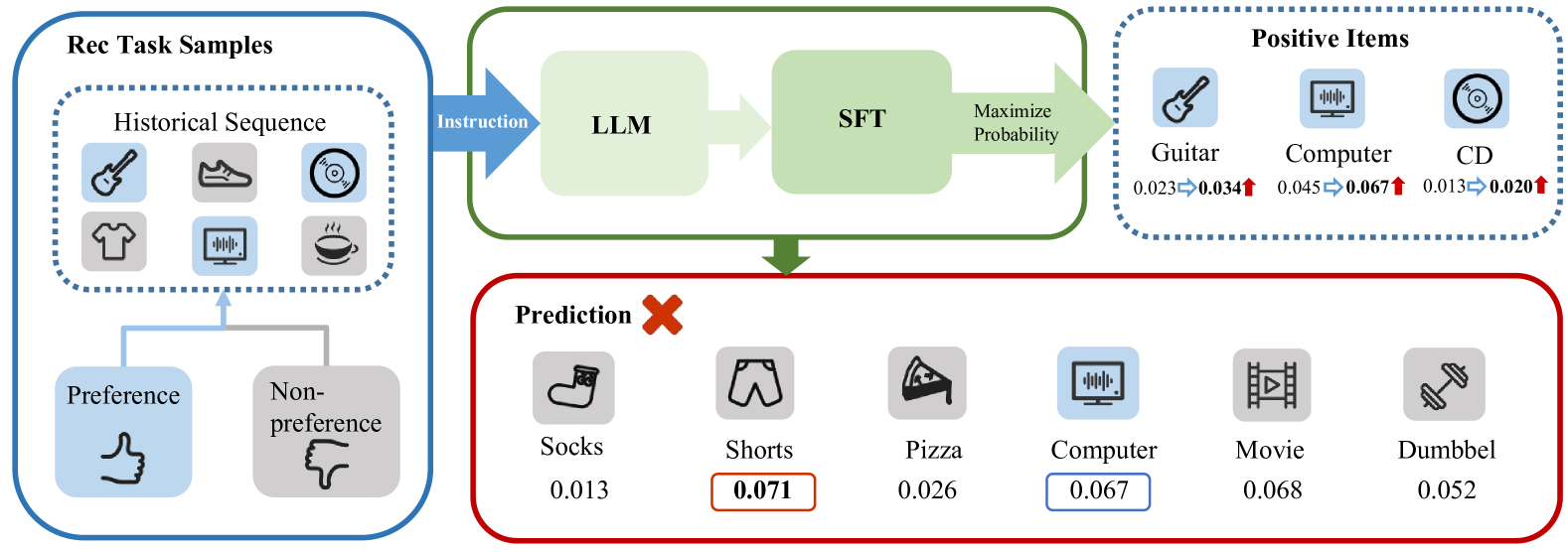
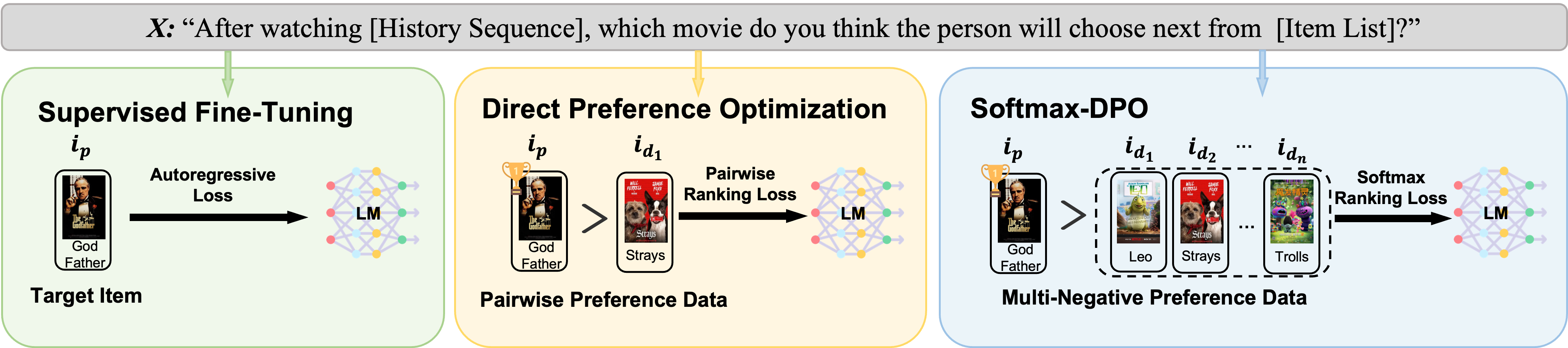
Recommender systems aim to predict personalized rankings based on user preference data. With the rise of Language Models (LMs), LM-based recommenders have been widely explored due to their extensive world knowledge and powerful reasoning abilities. Most of the LM-based recommenders convert historical interactions into language prompts, pairing with a positive item as the target response and fine-tuning LM with a language modeling loss. However, the current objective fails to fully leverage preference data and is not optimized for personalized ranking tasks, which hinders the performance of LM-based recommenders. Inspired by the current advancement of Direct Preference Optimization (DPO) in human preference alignment and the success of softmax loss in recommendations, we propose Softmax-DPO (S-DPO) to instill ranking information into the LM to help LM-based recommenders distinguish preferred items from negatives, rather than solely focusing on positives. Specifically, we incorporate multiple negatives in user preference data and devise an alternative version of DPO loss tailored for LM-based recommenders, connected to softmax sampling strategies. Theoretically, we bridge S-DPO with the softmax loss over negative sampling and find that it has a side effect of mining hard negatives, which assures its exceptional capabilities in recommendation tasks. Empirically, extensive experiments conducted on three real-world datasets demonstrate the superiority of S-DPO to effectively model user preference and further boost recommendation performance while mitigating the data likelihood decline issue of DPO. Our codes are available at https://github.com/chenyuxin1999/S-DPO.
6/17/2024
Multi-Reference Preference Optimization for Large Language Models
Hung Le, Quan Tran, Dung Nguyen, Kien Do, Saloni Mittal, Kelechi Ogueji, Svetha Venkatesh
0
0
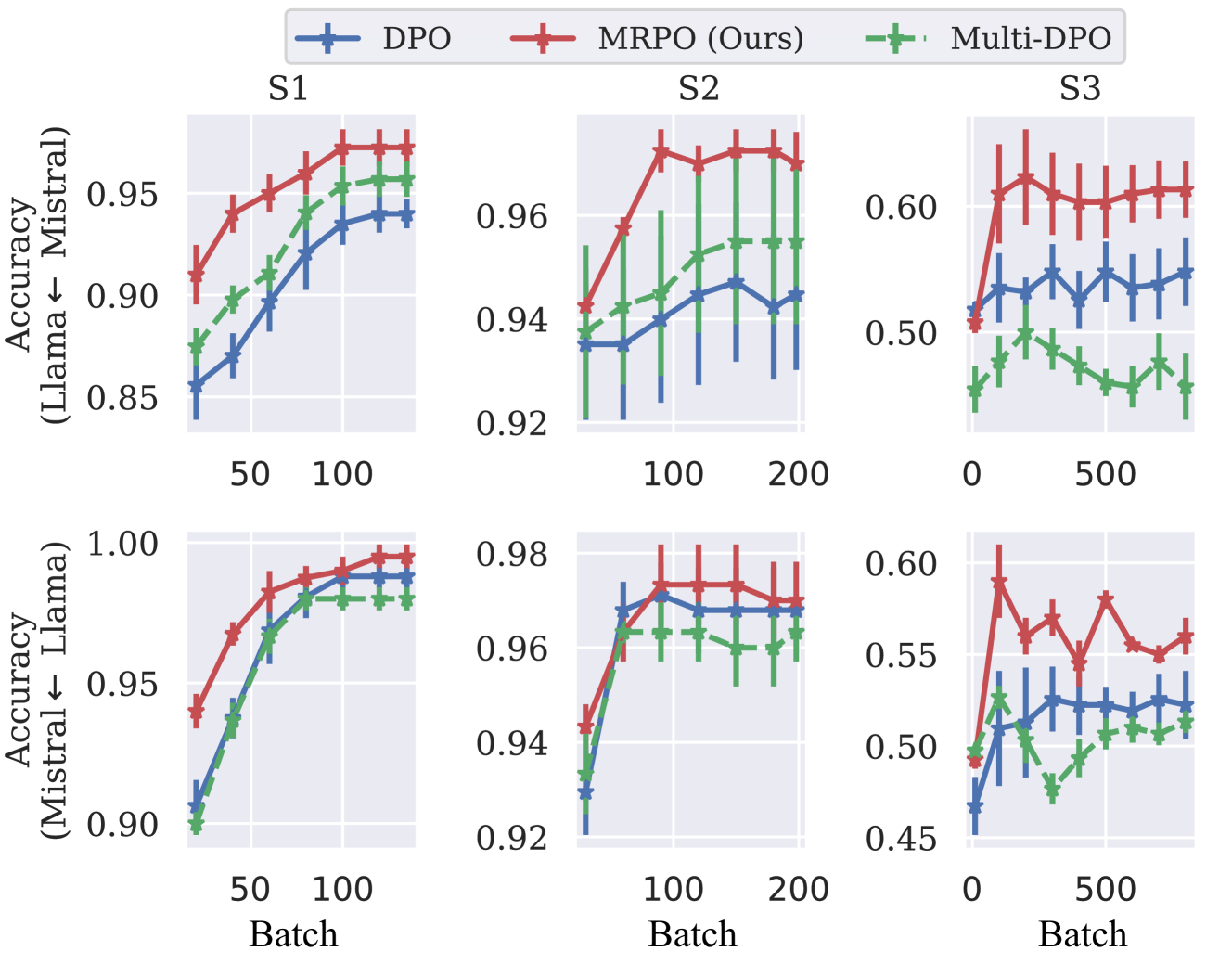
How can Large Language Models (LLMs) be aligned with human intentions and values? A typical solution is to gather human preference on model outputs and finetune the LLMs accordingly while ensuring that updates do not deviate too far from a reference model. Recent approaches, such as direct preference optimization (DPO), have eliminated the need for unstable and sluggish reinforcement learning optimization by introducing close-formed supervised losses. However, a significant limitation of the current approach is its design for a single reference model only, neglecting to leverage the collective power of numerous pretrained LLMs. To overcome this limitation, we introduce a novel closed-form formulation for direct preference optimization using multiple reference models. The resulting algorithm, Multi-Reference Preference Optimization (MRPO), leverages broader prior knowledge from diverse reference models, substantially enhancing preference learning capabilities compared to the single-reference DPO. Our experiments demonstrate that LLMs finetuned with MRPO generalize better in various preference data, regardless of data scarcity or abundance. Furthermore, MRPO effectively finetunes LLMs to exhibit superior performance in several downstream natural language processing tasks such as GSM8K and TruthfulQA.
5/28/2024
Token-level Direct Preference Optimization
Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, Jun Wang
0
0
Fine-tuning pre-trained Large Language Models (LLMs) is essential to align them with human values and intentions. This process often utilizes methods like pairwise comparisons and KL divergence against a reference LLM, focusing on the evaluation of full answers generated by the models. However, the generation of these responses occurs in a token level, following a sequential, auto-regressive fashion. In this paper, we introduce Token-level Direct Preference Optimization (TDPO), a novel approach to align LLMs with human preferences by optimizing policy at the token level. Unlike previous methods, which face challenges in divergence efficiency, TDPO incorporates forward KL divergence constraints for each token, improving alignment and diversity. Utilizing the Bradley-Terry model for a token-based reward system, TDPO enhances the regulation of KL divergence, while preserving simplicity without the need for explicit reward modeling. Experimental results across various text tasks demonstrate TDPO's superior performance in balancing alignment with generation diversity. Notably, fine-tuning with TDPO strikes a better balance than DPO in the controlled sentiment generation and single-turn dialogue datasets, and significantly improves the quality of generated responses compared to both DPO and PPO-based RLHF methods. Our code is open-sourced at https://github.com/Vance0124/Token-level-Direct-Preference-Optimization.
6/4/2024
Mallows-DPO: Fine-Tune Your LLM with Preference Dispersions
Haoxian Chen, Hanyang Zhao, Henry Lam, David Yao, Wenpin Tang
0
0
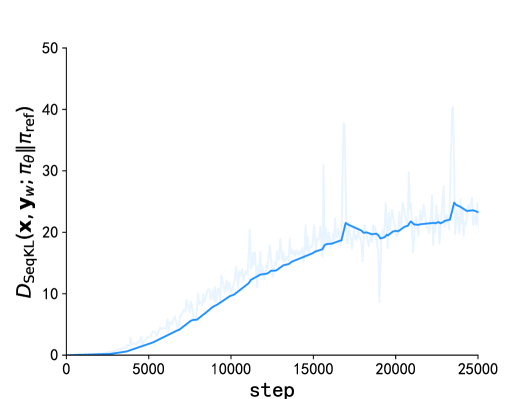
Direct Preference Optimization (DPO) has recently emerged as a popular approach to improve reinforcement learning with human feedback (RLHF), leading to better techniques to fine-tune large language models (LLM). A weakness of DPO, however, lies in its lack of capability to characterize the diversity of human preferences. Inspired by Mallows' theory of preference ranking, we develop in this paper a new approach, the Mallows-DPO. A distinct feature of this approach is a dispersion index, which reflects the dispersion of human preference to prompts. We show that existing DPO models can be reduced to special cases of this dispersion index, thus unified with Mallows-DPO. More importantly, we demonstrate (empirically) how to use this dispersion index to enhance the performance of DPO in a broad array of benchmark tasks, from synthetic bandit selection to controllable generations and dialogues, while maintaining great generalization capabilities.
5/27/2024