Learning the Language of Protein Structure

0
Sign in to get full access
Overview
- This paper presents a novel approach for learning the language of protein structure, which could have important applications in areas like protein design and drug discovery.
- The key idea is to use a protein structure autoencoder, a type of neural network, to learn a compact representation of protein 3D structures.
- The authors train this model on a large dataset of protein structures and show that the learned representations can be used to accurately predict various structural and functional properties of proteins.
Plain English Explanation
The paper is about a new way to understand the "language" of protein structure. Proteins are fundamental molecules in biology, and their 3D shape is crucial for how they work. However, understanding protein structure is challenging, as it involves complex 3D information.
The researchers developed a protein structure autoencoder, a type of neural network that can learn a compact, simplified representation of protein 3D structures. They trained this model on a large dataset of known protein structures.
Once trained, the model can take a protein structure as input and compress it into a concise "code" that captures the key features of that structure. This code can then be used to predict various properties of the protein, like how it might fold or interact with other molecules.
The key idea is that this learned "language of protein structure" could be very useful for applications like protein design and drug discovery. By having a better way to represent and understand protein structures, researchers may be able to more efficiently design new proteins or find drug molecules that bind to target proteins.
Technical Explanation
The core of the paper is a protein structure autoencoder, a type of neural network that can learn a compact representation of protein 3D structures. The autoencoder consists of an encoder that compresses the input protein structure into a low-dimensional latent representation, and a decoder that can reconstruct the original structure from that compressed code.
The authors train this autoencoder on a large dataset of known protein structures. By learning to efficiently encode and decode these structures, the model develops an understanding of the "language" of protein 3D shape. The authors show that the learned latent representations capture various structural and functional properties of the proteins, and can be used for tasks like predicting protein stability and binding affinity.
Key innovations in the paper include:
- A novel protein structure encoding scheme that allows the autoencoder to efficiently process 3D protein structures
- Unsupervised pretraining of the encoder to learn general protein structure representations
- Supervised fine-tuning of the model on specific prediction tasks to further enhance the learned representations
Critical Analysis
The paper presents a compelling approach for learning rich representations of protein structures, with promising results on several downstream tasks. However, a few potential limitations and areas for further research are worth noting:
-
Dataset size and diversity: The experiments are conducted on a large but still relatively narrow dataset of protein structures. It would be important to validate the approach on even more diverse datasets to ensure the learned representations generalize well.
-
Interpretability: While the latent representations capture relevant structural and functional properties, it's not always clear what specific features the model has learned. More work is needed to make these models and their inner workings more interpretable.
-
Application to protein design: The authors mention potential uses in protein design, but don't demonstrate this directly. Fully realizing the potential of this approach for de novo protein design remains an open challenge.
Overall, this is an impressive piece of research that advances the state-of-the-art in protein representation learning. With further development and validation, the techniques presented here could have significant impact in fields like structural biology and rational drug design.
Conclusion
This paper introduces a novel protein structure autoencoder that can learn a compact, expressive representation of 3D protein shapes. By training on large datasets of known protein structures, the model develops an understanding of the "language of protein structure" that can then be leveraged for a variety of downstream applications.
The learned representations capture key structural and functional properties, suggesting this approach could be highly useful for tasks like protein design, drug discovery, and predicting protein interactions. While some limitations and open challenges remain, this work represents an important step forward in our ability to computationally model and understand the fundamental building blocks of biology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning the Language of Protein Structure
Benoit Gaujac, J'er'emie Don`a, Liviu Copoiu, Timothy Atkinson, Thomas Pierrot, Thomas D. Barrett
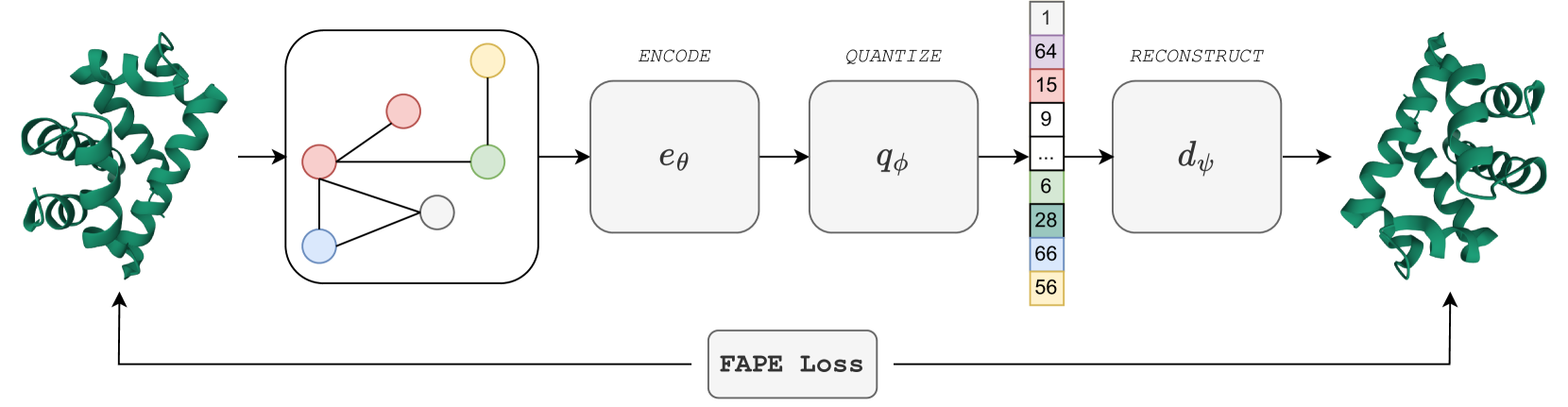
Representation learning and emph{de novo} generation of proteins are pivotal computational biology tasks. Whilst natural language processing (NLP) techniques have proven highly effective for protein sequence modelling, structure modelling presents a complex challenge, primarily due to its continuous and three-dimensional nature. Motivated by this discrepancy, we introduce an approach using a vector-quantized autoencoder that effectively tokenizes protein structures into discrete representations. This method transforms the continuous, complex space of protein structures into a manageable, discrete format with a codebook ranging from 4096 to 64000 tokens, achieving high-fidelity reconstructions with backbone root mean square deviations (RMSD) of approximately 1-5 AA. To demonstrate the efficacy of our learned representations, we show that a simple GPT model trained on our codebooks can generate novel, diverse, and designable protein structures. Our approach not only provides representations of protein structure, but also mitigates the challenges of disparate modal representations and sets a foundation for seamless, multi-modal integration, enhancing the capabilities of computational methods in protein design.
Read more5/28/2024
0
Protein Representation Learning by Capturing Protein Sequence-Structure-Function Relationship
Eunji Ko, Seul Lee, Minseon Kim, Dongki Kim
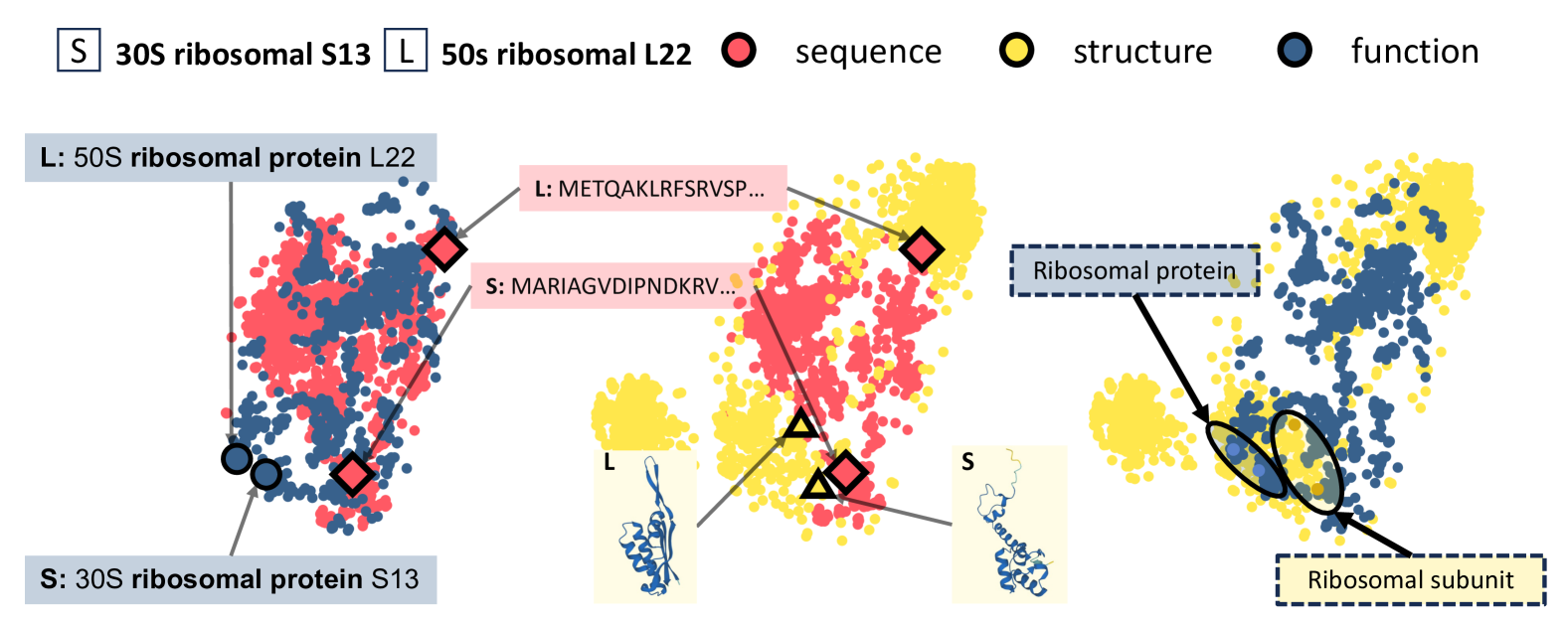
The goal of protein representation learning is to extract knowledge from protein databases that can be applied to various protein-related downstream tasks. Although protein sequence, structure, and function are the three key modalities for a comprehensive understanding of proteins, existing methods for protein representation learning have utilized only one or two of these modalities due to the difficulty of capturing the asymmetric interrelationships between them. To account for this asymmetry, we introduce our novel asymmetric multi-modal masked autoencoder (AMMA). AMMA adopts (1) a unified multi-modal encoder to integrate all three modalities into a unified representation space and (2) asymmetric decoders to ensure that sequence latent features reflect structural and functional information. The experiments demonstrate that the proposed AMMA is highly effective in learning protein representations that exhibit well-aligned inter-modal relationships, which in turn makes it effective for various downstream protein-related tasks.
Read more5/14/2024

0
Exploring Latent Space for Generating Peptide Analogs Using Protein Language Models
Po-Yu Liang, Xueting Huang, Tibo Duran, Andrew J. Wiemer, Jun Bai
Generating peptides with desired properties is crucial for drug discovery and biotechnology. Traditional sequence-based and structure-based methods often require extensive datasets, which limits their effectiveness. In this study, we proposed a novel method that utilized autoencoder shaped models to explore the protein embedding space, and generate novel peptide analogs by leveraging protein language models. The proposed method requires only a single sequence of interest, avoiding the need for large datasets. Our results show significant improvements over baseline models in similarity indicators of peptide structures, descriptors and bioactivities. The proposed method validated through Molecular Dynamics simulations on TIGIT inhibitors, demonstrates that our method produces peptide analogs with similar yet distinct properties, highlighting its potential to enhance peptide screening processes.
Read more8/19/2024
0
FoldToken2: Learning compact, invariant and generative protein structure language
Zhangyang Gao, Cheng Tan, Stan Z. Li
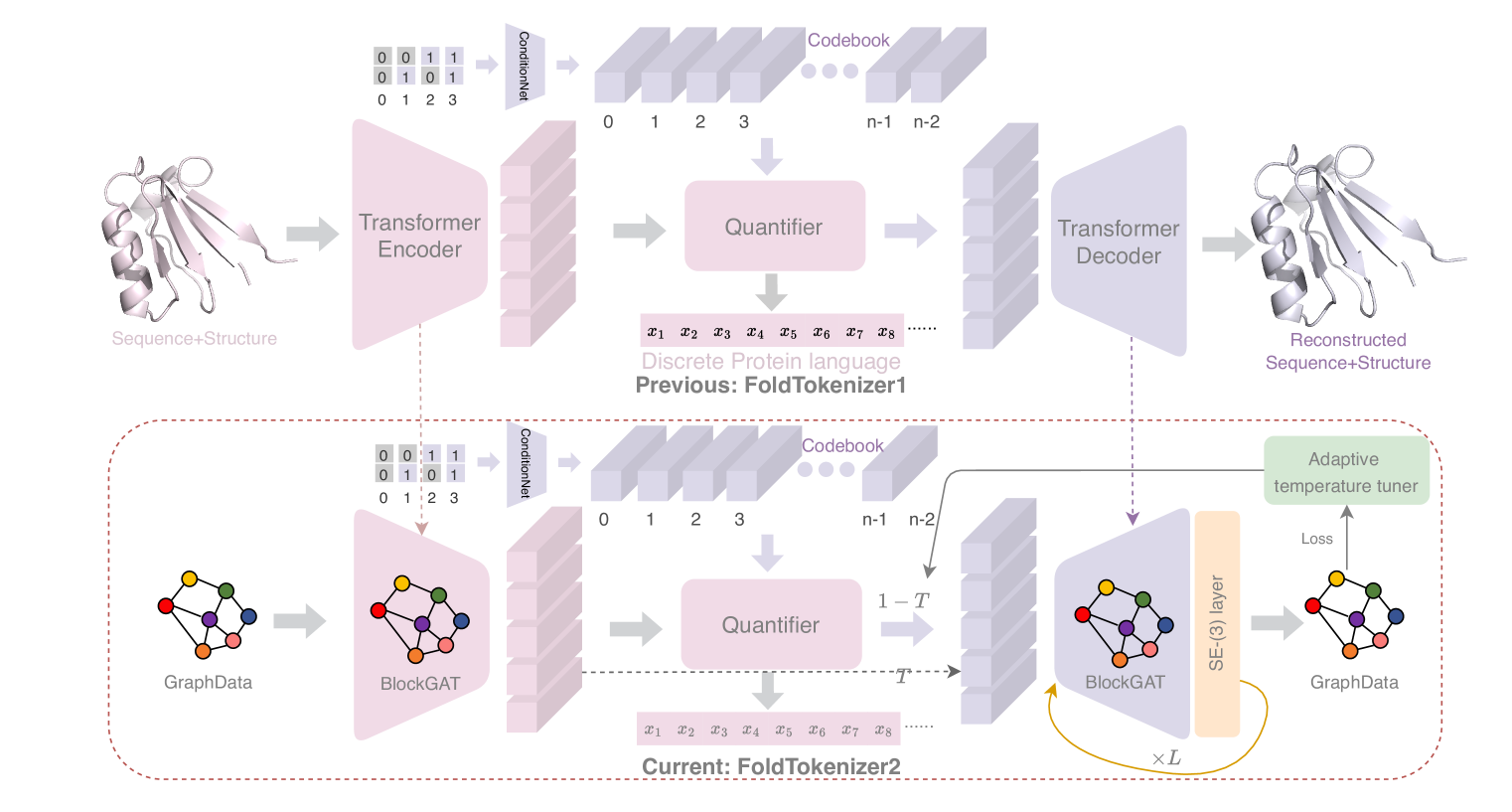
The equivalent nature of 3D coordinates has posed long term challenges in protein structure representation learning, alignment, and generation. Can we create a compact and invariant language that equivalently represents protein structures? Towards this goal, we propose FoldToken2 to transfer equivariant structures into discrete tokens, while maintaining the recoverability of the original structures. From FoldToken1 to FoldToken2, we improve three key components: (1) invariant structure encoder, (2) vector-quantized compressor, and (3) equivalent structure decoder. We evaluate FoldToken2 on the protein structure reconstruction task and show that it outperforms previous FoldToken1 by 20% in TMScore and 81% in RMSD. FoldToken2 probably be the first method that works well on both single-chain and multi-chain protein structures quantization. We believe that FoldToken2 will inspire further improvement in protein structure representation learning, structure alignment, and structure generation tasks.
Read more7/2/2024