Protein Representation Learning by Capturing Protein Sequence-Structure-Function Relationship

0
Sign in to get full access
Overview
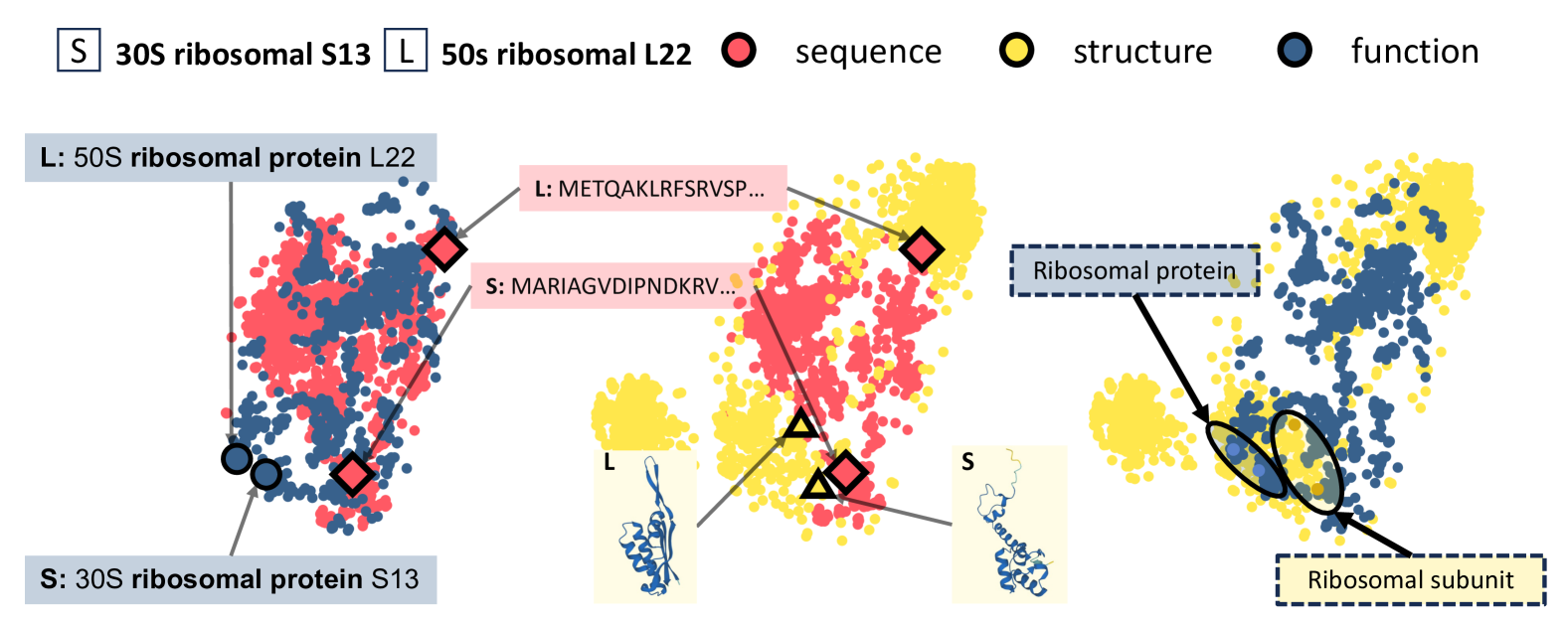
- This paper presents a novel approach for learning protein representations that capture the relationship between a protein's sequence, structure, and function.
- The proposed model, called prot2text-multimodal-proteins-function-generation-gnns-transformers, uses a multi-modal framework to learn expressive and generalizable protein representations.
- The model leverages both protein sequence and structure data to predict the protein's function, demonstrating improved performance compared to existing methods.
Plain English Explanation
Proteins are the basic building blocks of life, performing a vast array of critical functions in our bodies. Understanding the relationship between a protein's sequence (the order of its building blocks), structure (how it folds in 3D space), and function (what it does) is a fundamental challenge in biology.
The researchers developed a new machine learning model that can learn powerful representations of proteins by considering both their sequence and structure. This model is trained to predict a protein's function based on these inputs, and the internal representations it learns can be used for other tasks like protein design or drug discovery.
The key insight is that by jointly modeling a protein's sequence and structure, the model can capture more nuanced and expressive features that are relevant to its function. This contrasts with previous approaches that only used one type of information or treated them separately.
The researchers show that their prot2text-multimodal-proteins-function-generation-gnns-transformers model outperforms existing methods on benchmark tasks, demonstrating the power of this multi-modal protein representation learning approach.
Technical Explanation
The prot2text-multimodal-proteins-function-generation-gnns-transformers model uses a multi-modal architecture to learn protein representations. It takes as input both the protein's primary sequence (the linear chain of amino acids) and its 3D structural information (obtained from experimental techniques like X-ray crystallography).
The sequence is processed by a Transformer-based language model, while the structure is encoded using a Graph Neural Network (GNN) that captures the spatial relationships between amino acids. These two modalities are then fused using attention mechanisms, allowing the model to learn how sequence and structure relate to a protein's function.
The combined representation is then used to predict the protein's function, which is represented as a set of relevant Gene Ontology (GO) terms. This multi-task learning setup encourages the model to learn rich, generalizable protein representations that capture the sequence-structure-function relationship.
The researchers evaluate their model on several benchmark datasets for protein function prediction, comparing it to prior state-of-the-art methods that use only sequence or structure. The prot2text-multimodal-proteins-function-generation-gnns-transformers model demonstrates superior performance, highlighting the benefits of its multi-modal approach.
Critical Analysis
The prot2text-multimodal-proteins-function-generation-gnns-transformers model represents a promising step forward in protein representation learning, but there are a few caveats to consider:
-
The reliance on 3D structural data may limit the model's applicability, as such information is not always readily available, especially for newly discovered proteins. Exploring ways to leverage only sequence data or predict structure from sequence would increase the model's practical utility.
-
The model's performance on rare or novel protein functions is not thoroughly assessed. Evaluating its ability to generalize to unseen functions or handle class imbalance in the data would provide a more comprehensive understanding of its capabilities.
-
While the multi-modal approach shows advantages over single-modality models, the specific contributions of the sequence and structure components are not clearly disentangled. Further analysis could shed light on which aspects of the representation are most crucial for different downstream tasks.
Despite these limitations, the prot2text-multimodal-proteins-function-generation-gnns-transformers model represents an important step towards better understanding the complex relationship between protein sequence, structure, and function. Addressing these areas for improvement could lead to even more powerful and versatile protein representation learning approaches.
Conclusion
This paper introduces the prot2text-multimodal-proteins-function-generation-gnns-transformers model, a novel multi-modal framework for learning expressive protein representations that capture the sequence-structure-function relationship. By jointly modeling protein sequence and structure, the model demonstrates improved performance on protein function prediction tasks compared to existing methods.
The prot2text-multimodal-proteins-function-generation-gnns-transformers approach represents an important advancement in the field of protein representation learning, with potential applications in areas like drug discovery, protein engineering, and understanding the molecular basis of biological processes. Further research to address the identified limitations could lead to even more powerful and versatile protein representation models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Protein Representation Learning by Capturing Protein Sequence-Structure-Function Relationship
Eunji Ko, Seul Lee, Minseon Kim, Dongki Kim
The goal of protein representation learning is to extract knowledge from protein databases that can be applied to various protein-related downstream tasks. Although protein sequence, structure, and function are the three key modalities for a comprehensive understanding of proteins, existing methods for protein representation learning have utilized only one or two of these modalities due to the difficulty of capturing the asymmetric interrelationships between them. To account for this asymmetry, we introduce our novel asymmetric multi-modal masked autoencoder (AMMA). AMMA adopts (1) a unified multi-modal encoder to integrate all three modalities into a unified representation space and (2) asymmetric decoders to ensure that sequence latent features reflect structural and functional information. The experiments demonstrate that the proposed AMMA is highly effective in learning protein representations that exhibit well-aligned inter-modal relationships, which in turn makes it effective for various downstream protein-related tasks.
Read more5/14/2024
0
Learning the Language of Protein Structure
Benoit Gaujac, J'er'emie Don`a, Liviu Copoiu, Timothy Atkinson, Thomas Pierrot, Thomas D. Barrett
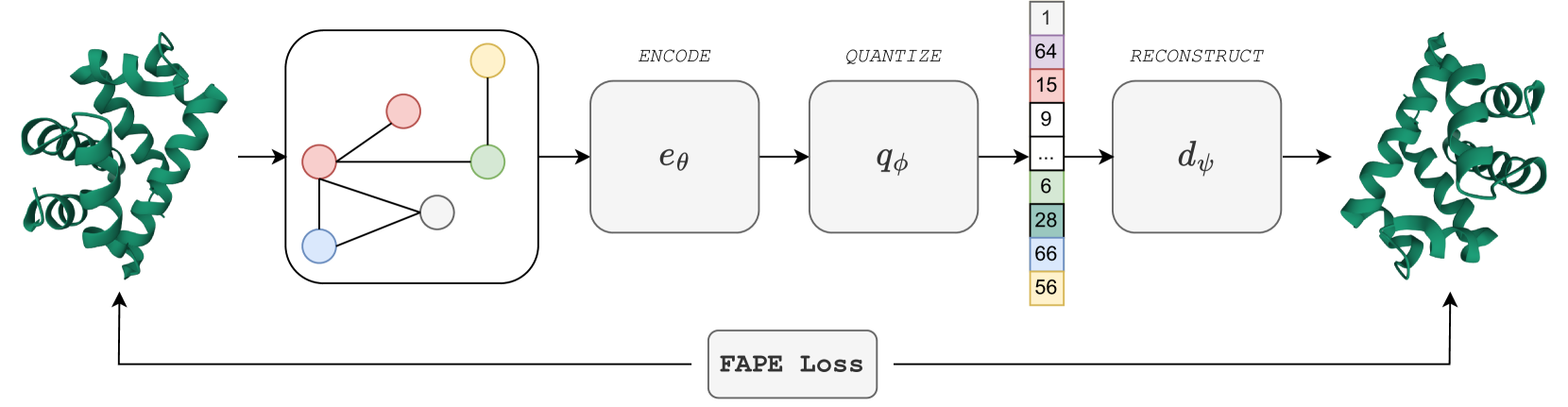
Representation learning and emph{de novo} generation of proteins are pivotal computational biology tasks. Whilst natural language processing (NLP) techniques have proven highly effective for protein sequence modelling, structure modelling presents a complex challenge, primarily due to its continuous and three-dimensional nature. Motivated by this discrepancy, we introduce an approach using a vector-quantized autoencoder that effectively tokenizes protein structures into discrete representations. This method transforms the continuous, complex space of protein structures into a manageable, discrete format with a codebook ranging from 4096 to 64000 tokens, achieving high-fidelity reconstructions with backbone root mean square deviations (RMSD) of approximately 1-5 AA. To demonstrate the efficacy of our learned representations, we show that a simple GPT model trained on our codebooks can generate novel, diverse, and designable protein structures. Our approach not only provides representations of protein structure, but also mitigates the challenges of disparate modal representations and sets a foundation for seamless, multi-modal integration, enhancing the capabilities of computational methods in protein design.
Read more5/28/2024

0
Progressive Multi-Modality Learning for Inverse Protein Folding
Jiangbin Zheng, Stan Z. Li
While deep generative models show promise for learning inverse protein folding directly from data, the lack of publicly available structure-sequence pairings limits their generalization. Previous improvements and data augmentation efforts to overcome this bottleneck have been insufficient. To further address this challenge, we propose a novel protein design paradigm called MMDesign, which leverages multi-modality transfer learning. To our knowledge, MMDesign is the first framework that combines a pretrained structural module with a pretrained contextual module, using an auto-encoder (AE) based language model to incorporate prior protein semantic knowledge. Experimental results, only training with the small dataset, demonstrate that MMDesign consistently outperforms baselines on various public benchmarks. To further assess the biological plausibility, we present systematic quantitative analysis techniques that provide interpretability and reveal more about the laws of protein design.
Read more7/23/2024

0
Protein Representation Learning with Sequence Information Embedding: Does it Always Lead to a Better Performance?
Yang Tan, Lirong Zheng, Bozitao Zhong, Liang Hong, Bingxin Zhou
Deep learning has become a crucial tool in studying proteins. While the significance of modeling protein structure has been discussed extensively in the literature, amino acid types are typically included in the input as a default operation for many inference tasks. This study demonstrates with structure alignment task that embedding amino acid types in some cases may not help a deep learning model learn better representation. To this end, we propose ProtLOCA, a local geometry alignment method based solely on amino acid structure representation. The effectiveness of ProtLOCA is examined by a global structure-matching task on protein pairs with an independent test dataset based on CATH labels. Our method outperforms existing sequence- and structure-based representation learning methods by more quickly and accurately matching structurally consistent protein domains. Furthermore, in local structure pairing tasks, ProtLOCA for the first time provides a valid solution to highlight common local structures among proteins with different overall structures but the same function. This suggests a new possibility for using deep learning methods to analyze protein structure to infer function.
Read more7/1/2024