Learning Language Structures through Grounding

0

Sign in to get full access
Overview
- Presents a new approach to 3D visual grounding, which involves aligning language and visual representations
- Introduces a novel "naturally supervised" training paradigm that leverages language supervision to learn grounded representations
- Demonstrates state-of-the-art performance on 3D visual grounding benchmarks
- Proposes a joint study on phrase grounding and its connection to overall task performance
- Explores compositional generalization in grounded language models
- Introduces a method for annotating FrameNet via structure-conditioned language generation
Plain English Explanation
The provided research explores several fascinating developments in the field of grounded language models. Grounded language models aim to connect language and visual representations, allowing AI systems to better understand the world.
One key innovation is a "naturally supervised" training approach for 3D visual grounding. Instead of relying on manually annotated data, this method leverages language supervision to learn grounded representations, leading to strong performance on benchmark tasks.
The research also proposes a joint study on phrase grounding - the ability to map language to visual elements. This provides insights into how phrase grounding relates to overall task performance.
Another area of exploration is compositional generalization in grounded language models. This refers to the ability to understand and generate novel language by composing familiar elements, which is a hallmark of human language understanding.
Finally, the researchers introduce a method for annotating FrameNet - a widely used resource for semantic analysis - via structure-conditioned language generation. This could streamline the process of building and expanding such linguistic resources.
Overall, these innovations represent important steps forward in the quest to build AI systems that can truly understand and engage with the world around them through language and vision.
Technical Explanation
The paper presents several advancements in the field of grounded language models. First, it introduces a novel "naturally supervised" training approach for 3D visual grounding. This method leverages language supervision to learn grounded representations, bypassing the need for manually annotated data. Experiments demonstrate state-of-the-art performance on 3D visual grounding benchmarks.
The research also proposes a joint study on phrase grounding - the ability to map language to visual elements. This analysis reveals interesting connections between phrase grounding and overall task performance, providing insights into the role of grounding in language understanding.
Another contribution is the exploration of compositional generalization in grounded language models. The authors investigate the model's ability to understand and generate novel language by composing familiar linguistic elements, a key aspect of human language understanding.
Finally, the researchers introduce a method for annotating FrameNet - a widely used resource for semantic analysis - via structure-conditioned language generation. This approach could streamline the process of building and expanding such linguistic resources.
Critical Analysis
The research presented in this paper represents significant advancements in the field of grounded language models. The "naturally supervised" training approach for 3D visual grounding is a particularly noteworthy innovation, as it addresses the challenge of acquiring large, annotated datasets for this task.
The joint study on phrase grounding and its connection to overall task performance provides valuable insights into the role of grounding in language understanding. However, the paper could have explored this relationship in greater depth, perhaps investigating specific linguistic phenomena or cognitive mechanisms that underlie the observed effects.
The exploration of compositional generalization in grounded language models is an important area of research, but the paper could have provided more details on the specific techniques used and the limitations or challenges encountered.
The proposed method for annotating FrameNet via structure-conditioned language generation is a promising approach, but the paper could have discussed potential biases or errors that may arise from this automated annotation process, as well as plans for human validation or refinement.
Overall, the research presented in this paper represents significant advancements in the field of grounded language models, but there are opportunities for further exploration and refinement of the techniques and insights provided.
Conclusion
This research paper presents several exciting developments in the field of grounded language models. The introduction of a "naturally supervised" training approach for 3D visual grounding is a particularly notable contribution, as it addresses the challenge of data availability for this task.
The joint study on phrase grounding and its connection to overall task performance provides valuable insights into the role of grounding in language understanding, while the exploration of compositional generalization in grounded language models represents an important step towards building more robust and flexible language models.
The proposed method for annotating FrameNet via structure-conditioned language generation could streamline the process of building and expanding such linguistic resources, potentially benefiting a wide range of natural language processing applications.
Overall, this research represents significant progress towards the goal of developing AI systems that can truly understand and engage with the world through language and vision. The innovations and insights presented in this paper pave the way for further advancements in this exciting field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Language Structures through Grounding
Freda Shi
Language is highly structured, with syntactic and semantic structures, to some extent, agreed upon by speakers of the same language. With implicit or explicit awareness of such structures, humans can learn and use language efficiently and generalize to sentences that contain unseen words. Motivated by human language learning, in this dissertation, we consider a family of machine learning tasks that aim to learn language structures through grounding. We seek distant supervision from other data sources (i.e., grounds), including but not limited to other modalities (e.g., vision), execution results of programs, and other languages. We demonstrate the potential of this task formulation and advocate for its adoption through three schemes. In Part I, we consider learning syntactic parses through visual grounding. We propose the task of visually grounded grammar induction, present the first models to induce syntactic structures from visually grounded text and speech, and find that the visual grounding signals can help improve the parsing quality over language-only models. As a side contribution, we propose a novel evaluation metric that enables the evaluation of speech parsing without text or automatic speech recognition systems involved. In Part II, we propose two execution-aware methods to map sentences into corresponding semantic structures (i.e., programs), significantly improving compositional generalization and few-shot program synthesis. In Part III, we propose methods that learn language structures from annotations in other languages. Specifically, we propose a method that sets a new state of the art on cross-lingual word alignment. We then leverage the learned word alignments to improve the performance of zero-shot cross-lingual dependency parsing, by proposing a novel substructure-based projection method that preserves structural knowledge learned from the source language.
Read more6/17/2024
0
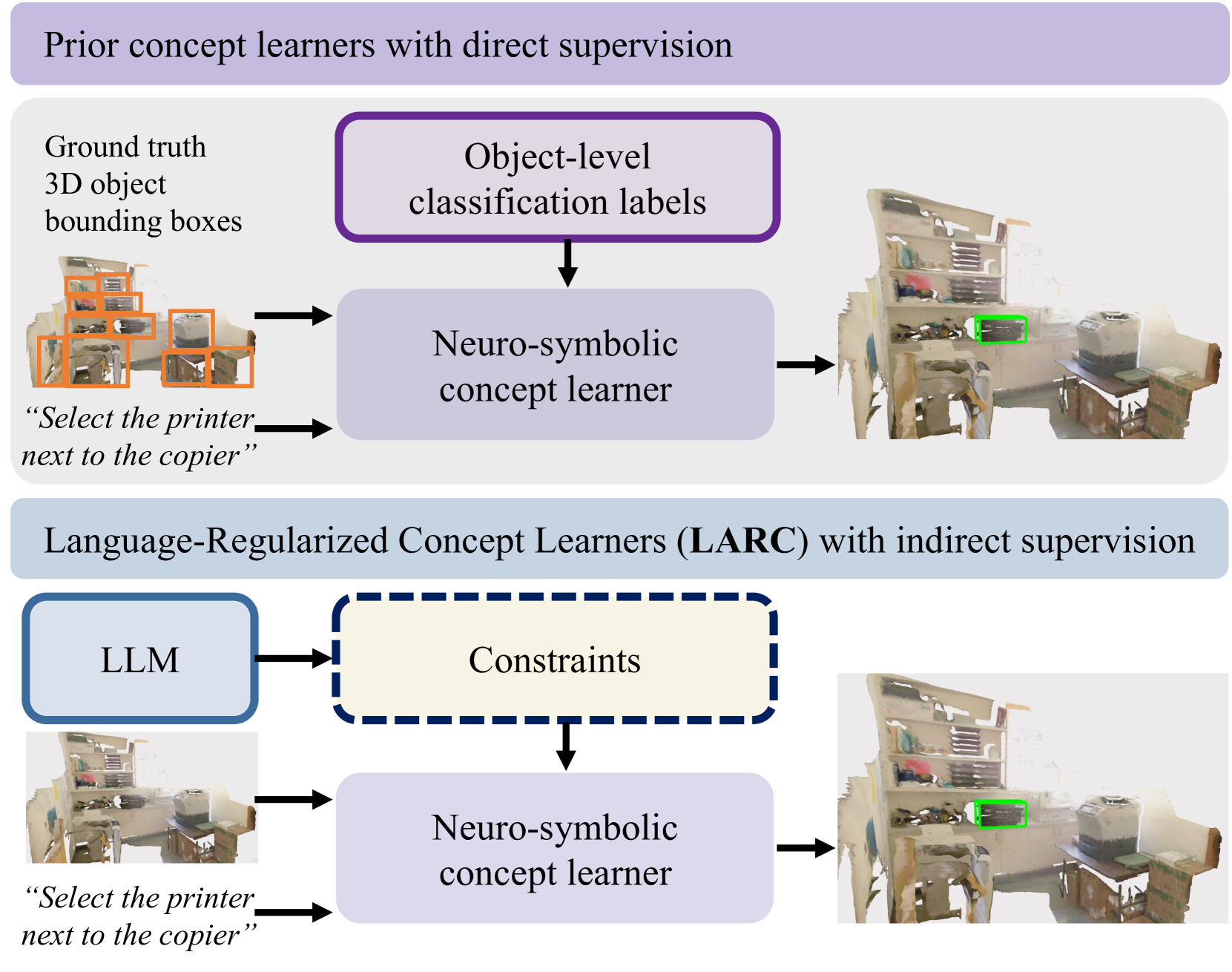
Naturally Supervised 3D Visual Grounding with Language-Regularized Concept Learners
Chun Feng, Joy Hsu, Weiyu Liu, Jiajun Wu
3D visual grounding is a challenging task that often requires direct and dense supervision, notably the semantic label for each object in the scene. In this paper, we instead study the naturally supervised setting that learns from only 3D scene and QA pairs, where prior works underperform. We propose the Language-Regularized Concept Learner (LARC), which uses constraints from language as regularization to significantly improve the accuracy of neuro-symbolic concept learners in the naturally supervised setting. Our approach is based on two core insights: the first is that language constraints (e.g., a word's relation to another) can serve as effective regularization for structured representations in neuro-symbolic models; the second is that we can query large language models to distill such constraints from language properties. We show that LARC improves performance of prior works in naturally supervised 3D visual grounding, and demonstrates a wide range of 3D visual reasoning capabilities-from zero-shot composition, to data efficiency and transferability. Our method represents a promising step towards regularizing structured visual reasoning frameworks with language-based priors, for learning in settings without dense supervision.
Read more5/1/2024
🚀
0
A Joint Study of Phrase Grounding and Task Performance in Vision and Language Models
Noriyuki Kojima, Hadar Averbuch-Elor, Yoav Artzi
Key to tasks that require reasoning about natural language in visual contexts is grounding words and phrases to image regions. However, observing this grounding in contemporary models is complex, even if it is generally expected to take place if the task is addressed in a way that is conductive to generalization. We propose a framework to jointly study task performance and phrase grounding, and propose three benchmarks to study the relation between the two. Our results show that contemporary models demonstrate inconsistency between their ability to ground phrases and solve tasks. We show how this can be addressed through brute-force training on ground phrasing annotations, and analyze the dynamics it creates. Code and at available at https://github.com/lil-lab/phrase_grounding.
Read more6/3/2024

0
Learning Visual Grounding from Generative Vision and Language Model
Shijie Wang, Dahun Kim, Ali Taalimi, Chen Sun, Weicheng Kuo
Visual grounding tasks aim to localize image regions based on natural language references. In this work, we explore whether generative VLMs predominantly trained on image-text data could be leveraged to scale up the text annotation of visual grounding data. We find that grounding knowledge already exists in generative VLM and can be elicited by proper prompting. We thus prompt a VLM to generate object-level descriptions by feeding it object regions from existing object detection datasets. We further propose attribute modeling to explicitly capture the important object attributes, and spatial relation modeling to capture inter-object relationship, both of which are common linguistic pattern in referring expression. Our constructed dataset (500K images, 1M objects, 16M referring expressions) is one of the largest grounding datasets to date, and the first grounding dataset with purely model-generated queries and human-annotated objects. To verify the quality of this data, we conduct zero-shot transfer experiments to the popular RefCOCO benchmarks for both referring expression comprehension (REC) and segmentation (RES) tasks. On both tasks, our model significantly outperform the state-of-the-art approaches without using human annotated visual grounding data. Our results demonstrate the promise of generative VLM to scale up visual grounding in the real world. Code and models will be released.
Read more7/23/2024