Learning Visual Grounding from Generative Vision and Language Model

0

Sign in to get full access
Overview
- Explores how generative vision and language models can be used for learning visual grounding
- Proposes a novel training approach that leverages the capabilities of these large-scale models
- Demonstrates improvements in visual grounding performance on various benchmark datasets
Plain English Explanation
The paper investigates how powerful generative models that can produce both images and text can be used to improve a computer's ability to link visual objects to the words that describe them. This "visual grounding" task is an important step in getting AI systems to truly understand the world in the way humans do.
The researchers developed a new training approach that takes advantage of the rich representations learned by large-scale generative models for both images and language. By having the model learn to generate captions for images and then match those captions to the correct visual elements, it can build strong connections between words and the visual concepts they represent.
The paper shows that this approach leads to better performance on standard visual grounding benchmarks compared to prior methods. This suggests that tapping into the power of generative models is a promising direction for advancing visual understanding in AI systems.
Technical Explanation
The paper proposes a novel training approach for learning visual grounding that leverages the capabilities of large-scale generative vision and language models. Specifically, the authors use a pretrained generative adversarial network (GAN) to generate realistic images and a large language model to generate captions for those images.
The key idea is to train the model to match the generated captions to the corresponding visual elements in the generated images. This allows the model to learn strong associations between language and visual concepts, which can then be applied to real-world images and text during evaluation.
The authors evaluate their approach on several standard visual grounding benchmarks, including RefCOCO, RefCOCO+, and RefCOCOg. They show that their method outperforms prior state-of-the-art approaches, demonstrating the benefits of leveraging powerful generative models for this task.
Critical Analysis
The paper makes a compelling case for the value of using generative vision and language models to learn effective visual grounding. By tapping into the rich representations learned by these large-scale models, the proposed approach is able to achieve strong performance on standard benchmarks.
However, the paper does not address some potential limitations or areas for future work. For example, it is unclear how well the approach would generalize to more complex or open-ended language, or how it would perform in real-world applications with more diverse visual and linguistic inputs.
Additionally, the paper does not provide a deep analysis of the model's internal workings or the specific mechanisms by which the generative pretraining leads to improved grounding performance. Further investigating these aspects could yield valuable insights for the field.
Conclusion
Overall, this paper makes an important contribution by demonstrating the potential of leveraging generative vision and language models for the task of visual grounding. The proposed approach shows promising results and suggests that this is a fruitful direction for advancing the state of the art in multimodal machine learning and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Visual Grounding from Generative Vision and Language Model
Shijie Wang, Dahun Kim, Ali Taalimi, Chen Sun, Weicheng Kuo
Visual grounding tasks aim to localize image regions based on natural language references. In this work, we explore whether generative VLMs predominantly trained on image-text data could be leveraged to scale up the text annotation of visual grounding data. We find that grounding knowledge already exists in generative VLM and can be elicited by proper prompting. We thus prompt a VLM to generate object-level descriptions by feeding it object regions from existing object detection datasets. We further propose attribute modeling to explicitly capture the important object attributes, and spatial relation modeling to capture inter-object relationship, both of which are common linguistic pattern in referring expression. Our constructed dataset (500K images, 1M objects, 16M referring expressions) is one of the largest grounding datasets to date, and the first grounding dataset with purely model-generated queries and human-annotated objects. To verify the quality of this data, we conduct zero-shot transfer experiments to the popular RefCOCO benchmarks for both referring expression comprehension (REC) and segmentation (RES) tasks. On both tasks, our model significantly outperform the state-of-the-art approaches without using human annotated visual grounding data. Our results demonstrate the promise of generative VLM to scale up visual grounding in the real world. Code and models will be released.
Read more7/23/2024
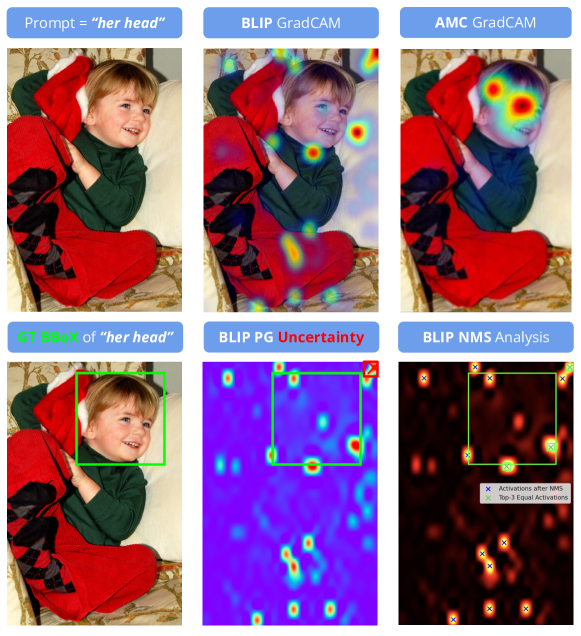
0
Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM
Navid Rajabi, Jana Kosecka
Vision and Language Models (VLMs) continue to demonstrate remarkable zero-shot (ZS) performance across various tasks. However, many probing studies have revealed that even the best-performing VLMs struggle to capture aspects of compositional scene understanding, lacking the ability to properly ground and localize linguistic phrases in images. Recent VLM advancements include scaling up both model and dataset sizes, additional training objectives and levels of supervision, and variations in the model architectures. To characterize the grounding ability of VLMs, such as phrase grounding, referring expressions comprehension, and relationship understanding, Pointing Game has been used as an evaluation metric for datasets with bounding box annotations. In this paper, we introduce a novel suite of quantitative metrics that utilize GradCAM activations to rigorously evaluate the grounding capabilities of pre-trained VLMs like CLIP, BLIP, and ALBEF. These metrics offer an explainable and quantifiable approach for a more detailed comparison of the zero-shot capabilities of VLMs and enable measuring models' grounding uncertainty. This characterization reveals interesting tradeoffs between the size of the model, the dataset size, and their performance.
Read more5/1/2024
🏋️
0
Enhancing Visual Grounding and Generalization: A Multi-Task Cycle Training Approach for Vision-Language Models
Xiaoyu Yang, Lijian Xu, Hao Sun, Hongsheng Li, Shaoting Zhang
Visual grounding (VG) occupies a pivotal position in multi-modality vision-language models. In this study, we propose ViLaM, a large multi-modality model, that supports multi-tasks of VG using the cycle training strategy, with abundant interaction instructions. The cycle training between referring expression generation (REG) and referring expression comprehension (REC) is introduced. It enhances the consistency between visual location and referring expressions, and addresses the need for high-quality, multi-tasks VG datasets. Moreover, multi-tasks of VG are promoted in our model, contributed by the cycle training strategy. The multi-tasks in REC encompass a range of granularities, from region-level to pixel-level, which include referring bbox detection, referring keypoints detection, and referring image segmentation. In REG, referring region classification determines the fine-grained category of the target, while referring region captioning generates a comprehensive description. Meanwhile, all tasks participate in the joint training, synergistically enhancing one another and collectively improving the overall performance of the model. Furthermore, leveraging the capabilities of large language models, ViLaM extends a wide range of instructions, thereby significantly enhancing its generalization and interaction potentials. Extensive public datasets corroborate the superior capabilities of our model in VG with muti-tasks. Additionally, validating its robust generalization, ViLaM is validated under open-set and few-shot scenarios. Especially in the medical field, our model demonstrates cross-domain robust generalization capabilities. Furthermore, we contribute a VG dataset, especially with multi-tasks. To support and encourage the community focused on VG, we have made both the dataset and our code public: https://github.com/AnonymGiant/ViLaM.
Read more4/29/2024

0
Does Object Grounding Really Reduce Hallucination of Large Vision-Language Models?
Gregor Geigle, Radu Timofte, Goran Glavav{s}
Large vision-language models (LVLMs) have recently dramatically pushed the state of the art in image captioning and many image understanding tasks (e.g., visual question answering). LVLMs, however, often textit{hallucinate} and produce captions that mention concepts that cannot be found in the image. These hallucinations erode the trustworthiness of LVLMs and are arguably among the main obstacles to their ubiquitous adoption. Recent work suggests that addition of grounding objectives -- those that explicitly align image regions or objects to text spans -- reduces the amount of LVLM hallucination. Although intuitive, this claim is not empirically justified as the reduction effects have been established, we argue, with flawed evaluation protocols that (i) rely on data (i.e., MSCOCO) that has been extensively used in LVLM training and (ii) measure hallucination via question answering rather than open-ended caption generation. In this work, in contrast, we offer the first systematic analysis of the effect of fine-grained object grounding on LVLM hallucination under an evaluation protocol that more realistically captures LVLM hallucination in open generation. Our extensive experiments over three backbone LLMs reveal that grounding objectives have little to no effect on object hallucination in open caption generation.
Read more6/21/2024