Learning Noise-Robust Joint Representation for Multimodal Emotion Recognition under Incomplete Data Scenarios
2311.16114
0
0
👁️
Abstract
Multimodal emotion recognition (MER) in practical scenarios is significantly challenged by the presence of missing or incomplete data across different modalities. To overcome these challenges, researchers have aimed to simulate incomplete conditions during the training phase to enhance the system's overall robustness. Traditional methods have often involved discarding data or substituting data segments with zero vectors to approximate these incompletenesses. However, such approaches neither accurately represent real-world conditions nor adequately address the issue of noisy data availability. For instance, a blurry image cannot be simply replaced with zero vectors, and still retain information. To tackle this issue and develop a more precise MER system, we introduce a novel noise-robust MER model that effectively learns robust multimodal joint representations from noisy data. This approach includes two pivotal components: firstly, a noise scheduler that adjusts the type and level of noise in the data to emulate various realistic incomplete situations. Secondly, a Variational AutoEncoder (VAE)-based module is employed to reconstruct these robust multimodal joint representations from the noisy inputs. Notably, the introduction of the noise scheduler enables the exploration of an entirely new type of incomplete data condition, which is impossible with existing methods. Extensive experimental evaluations on the benchmark datasets IEMOCAP and CMU-MOSEI demonstrate the effectiveness of the noise scheduler and the excellent performance of our proposed model.
Create account to get full access
Overview
- This paper introduces a novel noise-robust multimodal emotion recognition (MER) model that can effectively learn robust multimodal representations from noisy data.
- The approach includes a noise scheduler that adjusts the type and level of noise in the data to emulate various realistic incomplete situations, and a Variational AutoEncoder (VAE)-based module to reconstruct the robust multimodal joint representations from the noisy inputs.
- Extensive experiments on benchmark datasets demonstrate the effectiveness of the noise scheduler and the excellent performance of the proposed model.
Plain English Explanation
Multimodal emotion recognition (MER) is the process of identifying a person's emotional state by analyzing data from multiple sources, such as facial expressions, speech, and body language. However, in real-world scenarios, this data is often incomplete or noisy, which can significantly challenge the accuracy of MER systems.
To address this issue, the researchers developed a new MER model that is designed to be more robust to noisy and incomplete data. The key components of their approach are:
-
Noise Scheduler: This component introduces different types and levels of noise into the training data, simulating the kinds of incomplete or noisy data that the model might encounter in the real world. For example, it could add blurriness to images or introduce static to audio recordings.
-
Variational Autoencoder (VAE): This machine learning module is used to reconstruct the underlying "clean" multimodal representations from the noisy input data. By learning to remove the noise and recover the original information, the model becomes more robust to these types of imperfections.
By training the model with this noise-aware approach, the researchers were able to significantly improve its performance on benchmark MER datasets, even when the test data contained missing or low-quality information. This suggests that their noise-robust MER model could be more effective in real-world applications, where incomplete and noisy data is often a challenge.
Technical Explanation
The researchers recognized that traditional MER methods, which often discard data or substitute missing segments with zeros, do not accurately represent real-world conditions or adequately address the issue of noisy data availability. To tackle this problem, they introduced a novel noise-robust MER model that learns robust multimodal joint representations from noisy data.
The key components of their approach are:
-
Noise Scheduler: This module adjusts the type and level of noise in the training data to emulate various realistic incomplete situations, such as blurry images or static in audio recordings. This allows the model to explore a new type of incomplete data condition that is not possible with existing methods.
-
Variational Autoencoder (VAE): The researchers employ a VAE-based module to reconstruct the robust multimodal joint representations from the noisy inputs. By learning to remove the noise and recover the original information, the model becomes more resilient to imperfections in the data.
The researchers conducted extensive experiments on the IEMOCAP and CMU-MOSEI benchmark datasets, which demonstrated the effectiveness of the noise scheduler and the excellent performance of their proposed model, even in the presence of missing or incomplete data.
Critical Analysis
The researchers have addressed a significant challenge in MER by developing a noise-robust model that can effectively learn from noisy and incomplete data. Their approach of simulating these realistic conditions during training is a clever way to improve the model's performance in real-world scenarios.
One potential limitation of the study is that it focuses solely on simulated noise and incomplete conditions, rather than evaluating the model's performance on actual noisy or missing data from real-world sources. It would be valuable to see how the model fares in more realistic settings, where the nature and distribution of the noise may be more complex.
Additionally, the researchers could explore the interpretability of the noise scheduler and the VAE-based reconstruction module. Understanding how these components work and what types of noises or imperfections they are most effective at handling could provide valuable insights for further improving the model.
Overall, this research represents a significant step forward in addressing a critical challenge in MER, and the noise-robust approach could have important implications for the development of more reliable and practical emotion recognition systems.
Conclusion
This paper presents a novel noise-robust multimodal emotion recognition (MER) model that can effectively learn robust multimodal representations from noisy and incomplete data. By introducing a noise scheduler to simulate realistic incomplete conditions during training and employing a Variational Autoencoder (VAE) to reconstruct the underlying "clean" multimodal representations, the researchers have developed a more resilient MER system that outperforms traditional methods on benchmark datasets.
The noise-aware training approach and the VAE-based reconstruction module are key innovations that could have broader applications in other areas of multimodal learning and representation learning. As MER systems become increasingly important in areas like human-computer interaction, healthcare, and mental health monitoring, the ability to handle noisy and incomplete data will be crucial for their real-world deployment and effectiveness.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
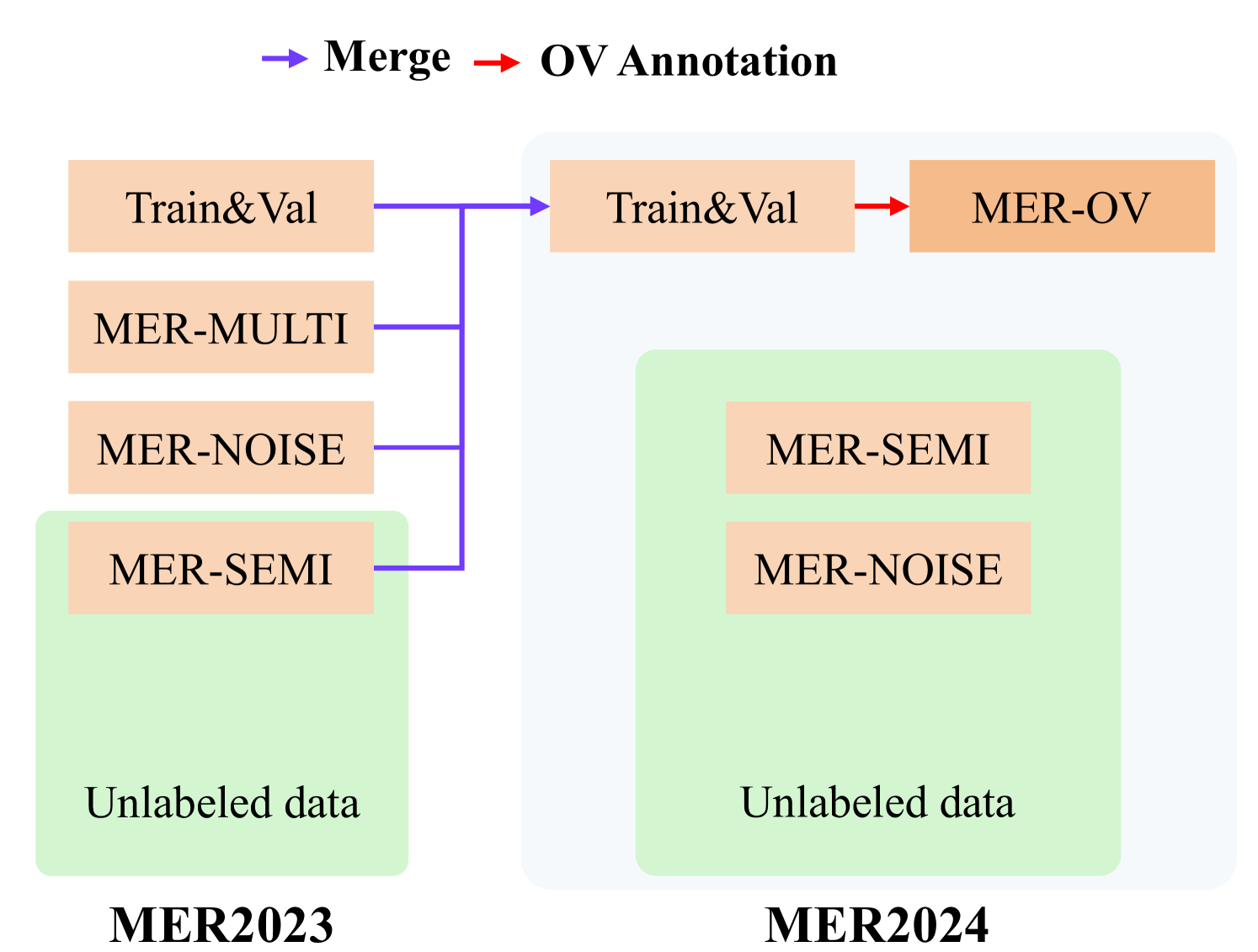
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Zheng Lian, Haiyang Sun, Licai Sun, Zhuofan Wen, Siyuan Zhang, Shun Chen, Hao Gu, Jinming Zhao, Ziyang Ma, Xie Chen, Jiangyan Yi, Rui Liu, Kele Xu, Bin Liu, Erik Cambria, Guoying Zhao, Bjorn W. Schuller, Jianhua Tao
0
0
Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing dataset size and building more effective architectures. However, due to various reasons (such as complex environments and inaccurate annotations), current systems are hard to meet the demands of practical applications. Therefore, we organize a series of challenges around emotion recognition to further promote the development of this area. Last year, we launched MER2023, focusing on three topics: multi-label learning, noise robustness, and semi-supervised learning. This year, we continue to organize MER2024. In addition to expanding the dataset size, we introduce a new track around open-vocabulary emotion recognition. The main consideration for this track is that existing datasets often fix the label space and use majority voting to enhance annotator consistency, but this process may limit the model's ability to describe subtle emotions. In this track, we encourage participants to generate any number of labels in any category, aiming to describe the emotional state as accurately as possible. Our baseline is based on MERTools and the code is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
5/24/2024

Joint Multimodal Transformer for Emotion Recognition in the Wild
Paul Waligora, Haseeb Aslam, Osama Zeeshan, Soufiane Belharbi, Alessandro Lameiras Koerich, Marco Pedersoli, Simon Bacon, Eric Granger
0
0
Multimodal emotion recognition (MMER) systems typically outperform unimodal systems by leveraging the inter- and intra-modal relationships between, e.g., visual, textual, physiological, and auditory modalities. This paper proposes an MMER method that relies on a joint multimodal transformer (JMT) for fusion with key-based cross-attention. This framework can exploit the complementary nature of diverse modalities to improve predictive accuracy. Separate backbones capture intra-modal spatiotemporal dependencies within each modality over video sequences. Subsequently, our JMT fusion architecture integrates the individual modality embeddings, allowing the model to effectively capture inter- and intra-modal relationships. Extensive experiments on two challenging expression recognition tasks -- (1) dimensional emotion recognition on the Affwild2 dataset (with face and voice) and (2) pain estimation on the Biovid dataset (with face and biosensors) -- indicate that our JMT fusion can provide a cost-effective solution for MMER. Empirical results show that MMER systems with our proposed fusion allow us to outperform relevant baseline and state-of-the-art methods.
4/23/2024

Unity by Diversity: Improved Representation Learning in Multimodal VAEs
Thomas M. Sutter, Yang Meng, Andrea Agostini, Daphn'e Chopard, Norbert Fortin, Julia E. Vogt, Bahbak Shahbaba, Stephan Mandt
0
0
Variational Autoencoders for multimodal data hold promise for many tasks in data analysis, such as representation learning, conditional generation, and imputation. Current architectures either share the encoder output, decoder input, or both across modalities to learn a shared representation. Such architectures impose hard constraints on the model. In this work, we show that a better latent representation can be obtained by replacing these hard constraints with a soft constraint. We propose a new mixture-of-experts prior, softly guiding each modality's latent representation towards a shared aggregate posterior. This approach results in a superior latent representation and allows each encoding to preserve information better from its uncompressed original features. In extensive experiments on multiple benchmark datasets and two challenging real-world datasets, we show improved learned latent representations and imputation of missing data modalities compared to existing methods.
6/3/2024
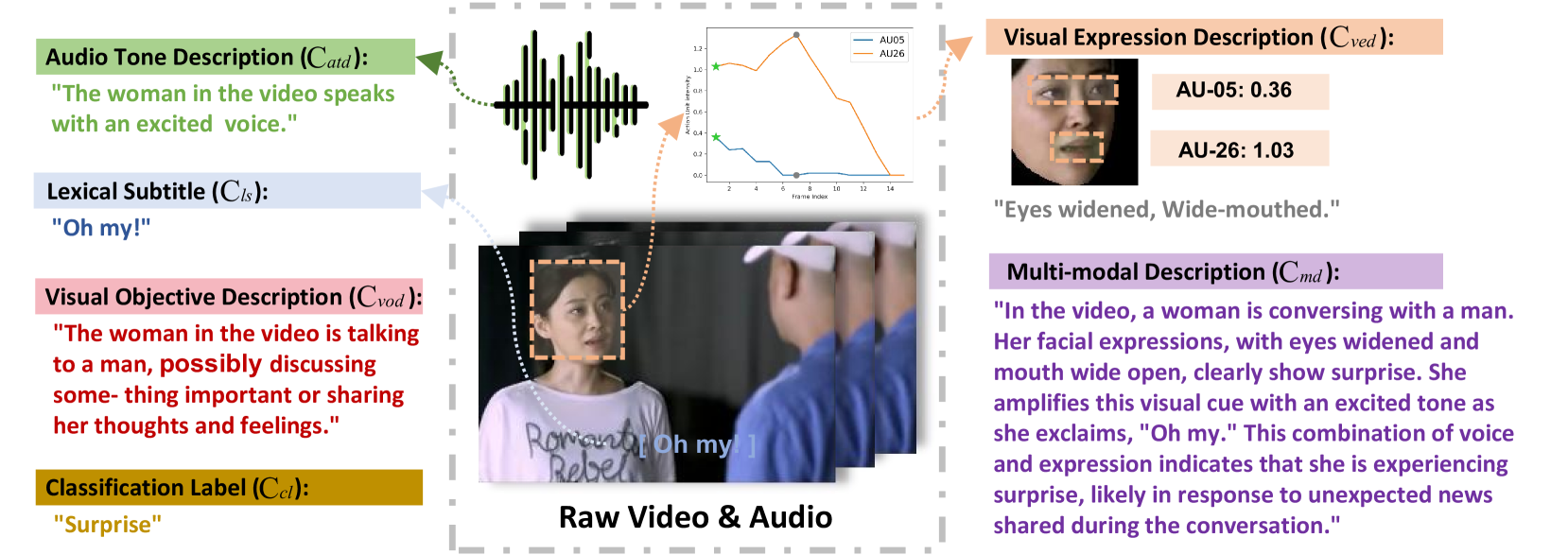
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
0
0
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
6/18/2024