Unity by Diversity: Improved Representation Learning in Multimodal VAEs
2403.05300
0
0

Abstract
Variational Autoencoders for multimodal data hold promise for many tasks in data analysis, such as representation learning, conditional generation, and imputation. Current architectures either share the encoder output, decoder input, or both across modalities to learn a shared representation. Such architectures impose hard constraints on the model. In this work, we show that a better latent representation can be obtained by replacing these hard constraints with a soft constraint. We propose a new mixture-of-experts prior, softly guiding each modality's latent representation towards a shared aggregate posterior. This approach results in a superior latent representation and allows each encoding to preserve information better from its uncompressed original features. In extensive experiments on multiple benchmark datasets and two challenging real-world datasets, we show improved learned latent representations and imputation of missing data modalities compared to existing methods.
Create account to get full access
Overview
- This paper proposes a new approach to improve representation learning in multimodal Variational Autoencoders (VAEs), which are models that can learn efficient encodings of data from multiple modalities (e.g., images and text).
- The key idea is to encourage the model to learn diverse and complementary representations from different modalities, rather than relying on a single shared representation.
- The authors demonstrate that this "unity by diversity" approach leads to better performance on a range of multimodal tasks compared to standard multimodal VAE models.
Plain English Explanation
Multimodal VAEs are machine learning models that can work with data from different sources, like images and text. These models try to find efficient ways to represent the information in this data. Learning Multi-Modal Generative Models with Permutation-Invariant Attention and Bridging Language, Vision, and Action in Multimodal VAEs for Robotic Manipulation are examples of previous work on multimodal VAEs.
The key idea in this paper is to encourage the model to learn diverse and complementary representations from the different data modalities, rather than relying on a single shared representation. The authors hypothesize that this "unity by diversity" approach will lead to better performance on multimodal tasks.
For example, when working with images and text, the model might learn one representation that captures the visual features of the image, and another representation that captures the semantic meaning of the accompanying text. By having these distinct but related representations, the model can make better use of the information in both modalities.
The paper demonstrates that this approach outperforms standard multimodal VAE models on a variety of tasks, showing the benefits of encouraging diverse representations in multimodal learning.
Technical Explanation
The paper proposes a new approach to learning multimodal representations in VAEs, called "Unity by Diversity" (UbD). The key idea is to encourage the model to learn diverse and complementary representations from different modalities, rather than relying on a single shared representation.
To achieve this, the authors introduce two key modifications to the standard multimodal VAE objective:
-
Modality-specific latent spaces: Instead of a single shared latent space, the model learns separate latent spaces for each modality. This allows the model to capture distinct representations for each data source.
-
Diversity-promoting regularization: The authors add a regularization term to the objective function that encourages the latent representations from different modalities to be as diverse (i.e., uncorrelated) as possible. This helps ensure the model learns complementary representations.
The authors evaluate the UbD approach on several multimodal tasks, including Learning Noise-Robust Joint Representation for Multimodal Emotion Recognition, Explaining Latent Representations of Generative Models for Large Multimodal Datasets, and Data-Efficient Multimodal Fusion on a Single GPU. They show that UbD outperforms standard multimodal VAE models, demonstrating the benefits of encouraging diverse representations in multimodal learning.
Critical Analysis
The paper presents a compelling approach to improving representation learning in multimodal VAEs. The key strength is the intuition that encouraging diverse and complementary representations from different modalities can lead to better performance, which the authors demonstrate empirically.
However, the paper could be strengthened by a more thorough analysis of the limitations and potential drawbacks of the UbD approach. For example, it's not clear how the method would scale to a large number of modalities, or how sensitive the performance is to the specific choice of hyperparameters for the diversity regularization.
Additionally, the paper does not explore the interpretability or explainability of the learned representations. Understanding how the modality-specific latent spaces capture and disentangle the underlying factors of the data could be an interesting area for further research.
Overall, the "unity by diversity" concept is a promising direction for multimodal representation learning, but more work is needed to fully understand the strengths, weaknesses, and broader implications of this approach.
Conclusion
This paper presents a new approach called "Unity by Diversity" (UbD) that improves representation learning in multimodal Variational Autoencoders (VAEs). The key idea is to encourage the model to learn diverse and complementary representations from different data modalities, rather than relying on a single shared representation.
The authors demonstrate that this approach outperforms standard multimodal VAE models on a range of tasks, highlighting the benefits of promoting diverse representations in multimodal learning. This work contributes to the broader effort to develop more effective and interpretable multimodal machine learning models, with potential applications in areas like multimedia analysis, robotics, and multimodal human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
Learning multi-modal generative models with permutation-invariant encoders and tighter variational bounds
Marcel Hirt, Domenico Campolo, Victoria Leong, Juan-Pablo Ortega
0
0
Devising deep latent variable models for multi-modal data has been a long-standing theme in machine learning research. Multi-modal Variational Autoencoders (VAEs) have been a popular generative model class that learns latent representations that jointly explain multiple modalities. Various objective functions for such models have been suggested, often motivated as lower bounds on the multi-modal data log-likelihood or from information-theoretic considerations. To encode latent variables from different modality subsets, Product-of-Experts (PoE) or Mixture-of-Experts (MoE) aggregation schemes have been routinely used and shown to yield different trade-offs, for instance, regarding their generative quality or consistency across multiple modalities. In this work, we consider a variational bound that can tightly approximate the data log-likelihood. We develop more flexible aggregation schemes that generalize PoE or MoE approaches by combining encoded features from different modalities based on permutation-invariant neural networks. Our numerical experiments illustrate trade-offs for multi-modal variational bounds and various aggregation schemes. We show that tighter variational bounds and more flexible aggregation models can become beneficial when one wants to approximate the true joint distribution over observed modalities and latent variables in identifiable models.
4/22/2024
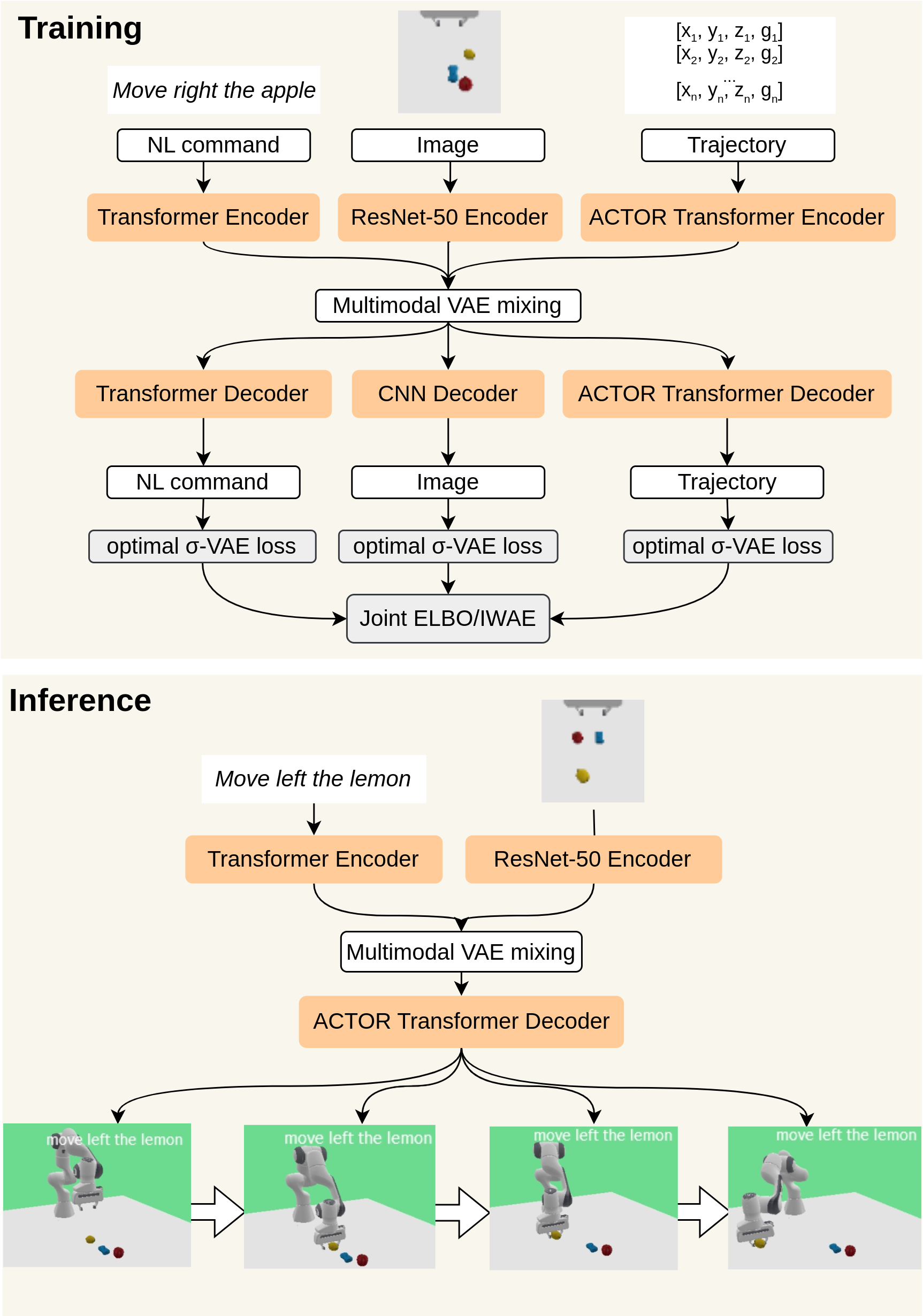
Bridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
Gabriela Sejnova, Michal Vavrecka, Karla Stepanova
0
0
In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.
4/3/2024
👁️
Learning Noise-Robust Joint Representation for Multimodal Emotion Recognition under Incomplete Data Scenarios
Qi Fan (Inner Mongolia University, Hohhot, China), Haolin Zuo (Inner Mongolia University, Hohhot, China), Rui Liu (Inner Mongolia University, Hohhot, China), Zheng Lian (Institute of Automation, Chinese Academy of Sciences, Beijing, China), Guanglai Gao (Inner Mongolia University, Hohhot, China)
0
0
Multimodal emotion recognition (MER) in practical scenarios is significantly challenged by the presence of missing or incomplete data across different modalities. To overcome these challenges, researchers have aimed to simulate incomplete conditions during the training phase to enhance the system's overall robustness. Traditional methods have often involved discarding data or substituting data segments with zero vectors to approximate these incompletenesses. However, such approaches neither accurately represent real-world conditions nor adequately address the issue of noisy data availability. For instance, a blurry image cannot be simply replaced with zero vectors, and still retain information. To tackle this issue and develop a more precise MER system, we introduce a novel noise-robust MER model that effectively learns robust multimodal joint representations from noisy data. This approach includes two pivotal components: firstly, a noise scheduler that adjusts the type and level of noise in the data to emulate various realistic incomplete situations. Secondly, a Variational AutoEncoder (VAE)-based module is employed to reconstruct these robust multimodal joint representations from the noisy inputs. Notably, the introduction of the noise scheduler enables the exploration of an entirely new type of incomplete data condition, which is impossible with existing methods. Extensive experimental evaluations on the benchmark datasets IEMOCAP and CMU-MOSEI demonstrate the effectiveness of the noise scheduler and the excellent performance of our proposed model.
5/8/2024

Explaining latent representations of generative models with large multimodal models
Mengdan Zhu, Zhenke Liu, Bo Pan, Abhinav Angirekula, Liang Zhao
0
0
Learning interpretable representations of data generative latent factors is an important topic for the development of artificial intelligence. With the rise of the large multimodal model, it can align images with text to generate answers. In this work, we propose a framework to comprehensively explain each latent variable in the generative models using a large multimodal model. We further measure the uncertainty of our generated explanations, quantitatively evaluate the performance of explanation generation among multiple large multimodal models, and qualitatively visualize the variations of each latent variable to learn the disentanglement effects of different generative models on explanations. Finally, we discuss the explanatory capabilities and limitations of state-of-the-art large multimodal models.
4/19/2024