Improve Mathematical Reasoning in Language Models by Automated Process Supervision

2
Sign in to get full access
Overview
- This paper proposes a method to improve the mathematical reasoning capabilities of language models by incorporating automated process supervision during training.
- The authors argue that current language models struggle with tasks requiring step-by-step reasoning, and that their approach can address this limitation.
- The proposed method involves training the language model to generate not just the final answer, but also the intermediate steps and reasoning process.
- This is achieved through a novel training setup that provides the model with feedback on the correctness of its generated reasoning process.
Plain English Explanation
The paper discusses a way to make language models better at mathematical reasoning and problem-solving. Current language models, like the ones used in chatbots and virtual assistants, often struggle with tasks that require step-by-step logical thinking, such as solving complex math problems.
The key idea behind this research is to train the language model not just to provide the final answer, but also to generate the complete step-by-step reasoning process. This is done by giving the model feedback on whether its generated reasoning is correct or not, in an automated way. By learning to produce the full reasoning process, the model can better understand the underlying logic and improve its mathematical problem-solving abilities.
The authors argue that this approach, which they call "automated process supervision," can help language models become more adept at tasks that require deep, structured reasoning, rather than just pattern matching or surface-level understanding.
Technical Explanation
The paper proposes a novel training setup for language models to improve their mathematical reasoning capabilities. The authors argue that current language models struggle with tasks that require step-by-step logical reasoning, such as solving complex math problems.
To address this, the authors introduce a training approach called "automated process supervision." During training, the language model is not only tasked with generating the final answer, but also the complete step-by-step reasoning process. The model's generated reasoning process is then automatically evaluated for correctness, and this feedback is used to further train the model.
This setup encourages the language model to learn not just the final output, but also the underlying logic and reasoning required to arrive at the solution. The authors hypothesize that this will lead to better mathematical reasoning abilities, as the model will develop a deeper understanding of the problem-solving process.
The authors evaluate their approach on a range of mathematical reasoning tasks and find that it outperforms traditional language model training approaches. They also provide insights into the model's learned reasoning strategies and discuss the implications of this work for the development of more capable and trustworthy AI systems.
Critical Analysis
The paper presents a promising approach to improving the mathematical reasoning capabilities of language models, an important and challenging problem in AI. The authors' key insight of incorporating automated process supervision during training is well-motivated and the experimental results are encouraging.
However, the paper does not fully address potential limitations and areas for further research. For example, the authors do not explore how their approach scales to more complex mathematical reasoning tasks, nor do they investigate the generalization of the learned reasoning strategies to novel problem types.
Additionally, the paper would benefit from a more thorough discussion of the potential pitfalls and failure modes of the proposed method. While the authors acknowledge that language models may still struggle with certain types of reasoning, a more in-depth analysis of these limitations would help readers understand the scope and applicability of the technique.
Despite these minor shortcomings, the paper makes a valuable contribution to the field of language model development and presents an intriguing direction for enhancing the mathematical reasoning abilities of AI systems. Further research along these lines could lead to significant advancements in the quest for more capable and trustworthy artificial intelligence.
Conclusion
This paper introduces a novel training approach called "automated process supervision" to improve the mathematical reasoning capabilities of language models. By training the models to generate not just the final answer, but also the complete step-by-step reasoning process, the authors show that language models can develop a deeper understanding of logical problem-solving.
The proposed method represents a promising step towards more capable and transparent AI systems, as it encourages models to learn robust reasoning strategies rather than relying solely on pattern matching or surface-level understanding. While the paper identifies some limitations that warrant further research, the authors' work highlights the value of incorporating structured reasoning into language model training, with potential applications in fields ranging from education to scientific discovery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
2
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, Abhinav Rastogi
Complex multi-step reasoning tasks, such as solving mathematical problems or generating code, remain a significant hurdle for even the most advanced large language models (LLMs). Verifying LLM outputs with an Outcome Reward Model (ORM) is a standard inference-time technique aimed at enhancing the reasoning performance of LLMs. However, this still proves insufficient for reasoning tasks with a lengthy or multi-hop reasoning chain, where the intermediate outcomes are neither properly rewarded nor penalized. Process supervision addresses this limitation by assigning intermediate rewards during the reasoning process. To date, the methods used to collect process supervision data have relied on either human annotation or per-step Monte Carlo estimation, both prohibitively expensive to scale, thus hindering the broad application of this technique. In response to this challenge, we propose a novel divide-and-conquer style Monte Carlo Tree Search (MCTS) algorithm named textit{OmegaPRM} for the efficient collection of high-quality process supervision data. This algorithm swiftly identifies the first error in the Chain of Thought (CoT) with binary search and balances the positive and negative examples, thereby ensuring both efficiency and quality. As a result, we are able to collect over 1.5 million process supervision annotations to train a Process Reward Model (PRM). Utilizing this fully automated process supervision alongside the weighted self-consistency algorithm, we have enhanced the instruction tuned Gemini Pro model's math reasoning performance, achieving a 69.4% success rate on the MATH benchmark, a 36% relative improvement from the 51% base model performance. Additionally, the entire process operates without any human intervention, making our method both financially and computationally cost-effective compared to existing methods.
Read more6/12/2024
13
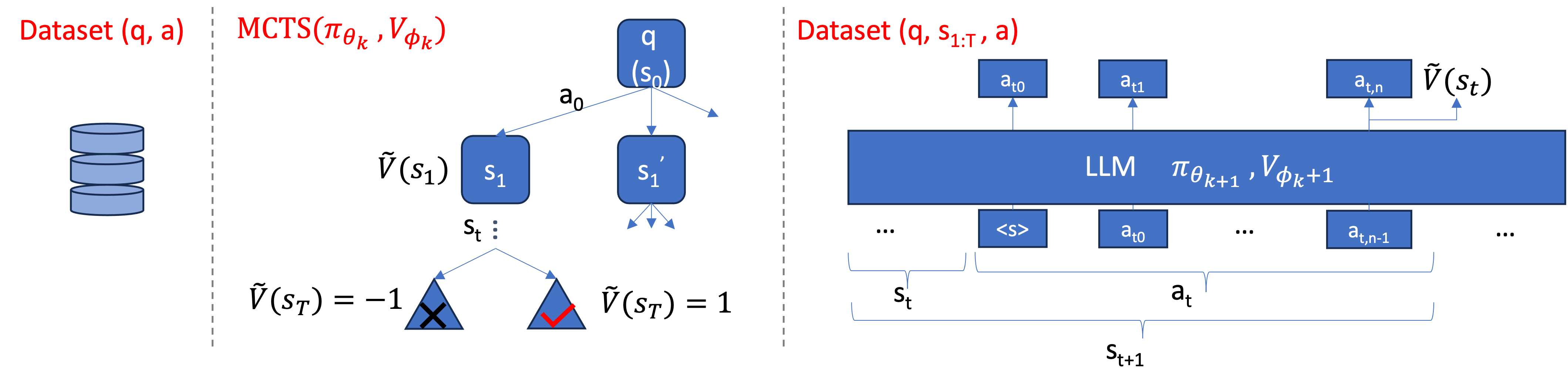
AlphaMath Almost Zero: process Supervision without process
Guoxin Chen, Minpeng Liao, Chengxi Li, Kai Fan
Recent advancements in large language models (LLMs) have substantially enhanced their mathematical reasoning abilities. However, these models still struggle with complex problems that require multiple reasoning steps, frequently leading to logical or numerical errors. While numerical mistakes can be largely addressed by integrating a code interpreter, identifying logical errors within intermediate steps is more challenging. Moreover, manually annotating these steps for training is not only expensive but also labor-intensive, requiring the expertise of professional annotators. In our study, we introduce an innovative approach that bypasses the need for process annotations (from human or GPTs) by utilizing the Monte Carlo Tree Search (MCTS) framework. This technique automatically generates both the process supervision and the step-level evaluation signals. Our method iteratively trains the policy and value models, leveraging the capabilities of a well-pretrained LLM to progressively enhance its mathematical reasoning skills. Furthermore, we propose an efficient inference strategy-step-level beam search, where the value model is crafted to assist the policy model (i.e., LLM) in navigating more effective reasoning paths, rather than solely relying on prior probabilities. The experimental results on both in-domain and out-of-domain datasets demonstrate that even without GPT-4 or human-annotated process supervision, our AlphaMath framework achieves comparable or superior results to previous state-of-the-art methods.
Read more5/24/2024
✅
0
Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing
Fangkai Jiao, Chengwei Qin, Zhengyuan Liu, Nancy F. Chen, Shafiq Joty
Large Language Models (LLMs) have demonstrated significant potential in handling complex reasoning tasks through step-by-step rationale generation. However, recent studies have raised concerns regarding the hallucination and flaws in their reasoning process. Substantial efforts are being made to improve the reliability and faithfulness of the generated rationales. Some approaches model reasoning as planning, while others focus on annotating for process supervision. Nevertheless, the planning-based search process often results in high latency due to the frequent assessment of intermediate reasoning states and the extensive exploration space. Additionally, supervising the reasoning process with human annotation is costly and challenging to scale for LLM training. To address these issues, in this paper, we propose a framework to learn planning-based reasoning through Direct Preference Optimization (DPO) on collected trajectories, which are ranked according to synthesized process rewards. Our results on challenging logical reasoning benchmarks demonstrate the effectiveness of our learning framework, showing that our 7B model can surpass the strong counterparts like GPT-3.5-Turbo.
Read more4/16/2024
0
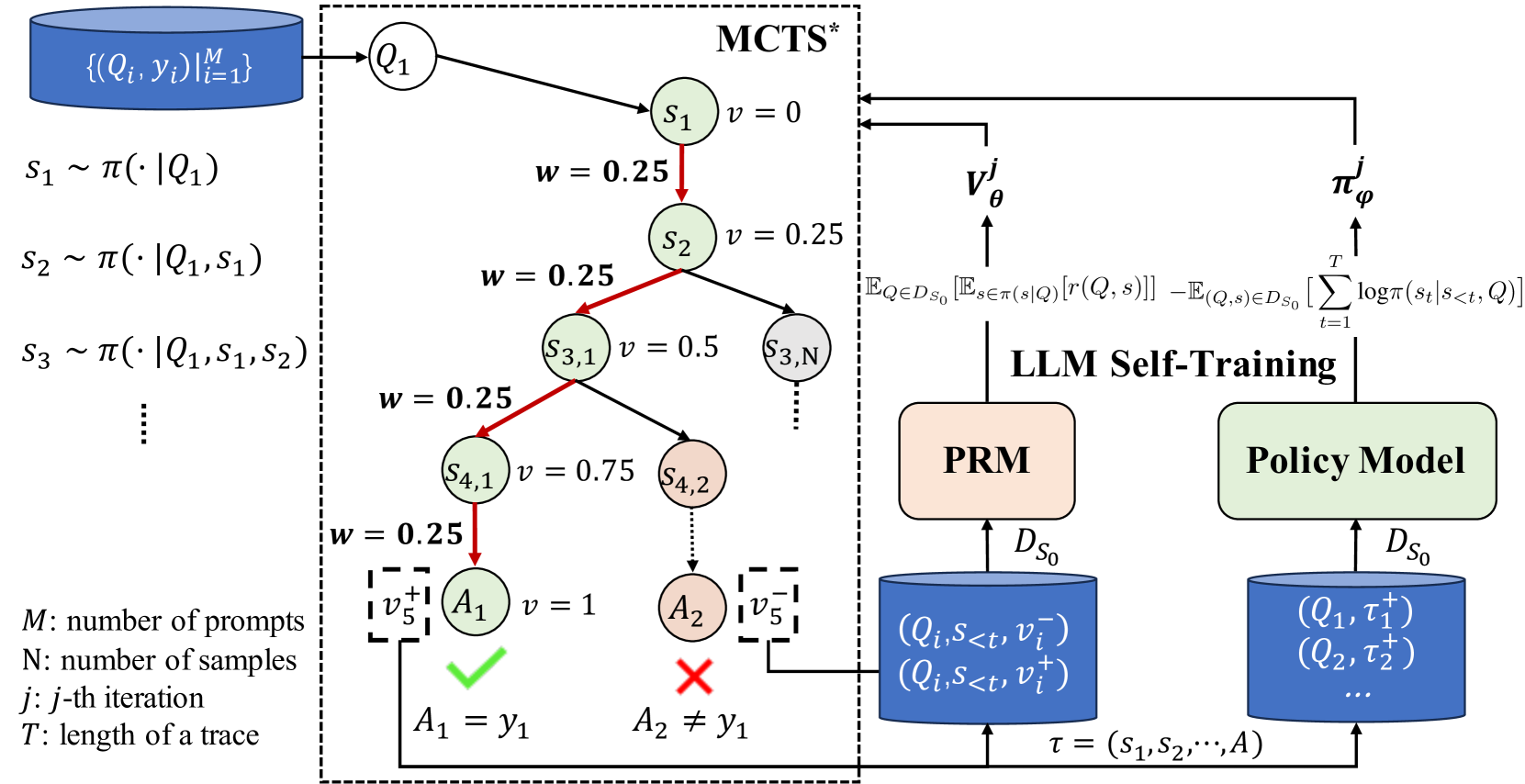
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, Jie Tang
Recent methodologies in LLM self-training mostly rely on LLM generating responses and filtering those with correct output answers as training data. This approach often yields a low-quality fine-tuning training set (e.g., incorrect plans or intermediate reasoning). In this paper, we develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training. We first show that the tree-search policy in ReST-MCTS* achieves higher accuracy compared with prior LLM reasoning baselines such as Best-of-N and Tree-of-Thought, within the same search budget. We then show that by using traces searched by this tree-search policy as training data, we can continuously enhance the three language models for multiple iterations, and outperform other self-training algorithms such as ReST$^text{EM}$ and Self-Rewarding LM.
Read more9/4/2024