Learning representations of learning representations
2404.08403
0
0

Abstract
The ICLR conference is unique among the top machine learning conferences in that all submitted papers are openly available. Here we present the ICLR dataset consisting of abstracts of all 24 thousand ICLR submissions from 2017-2024 with meta-data, decision scores, and custom keyword-based labels. We find that on this dataset, bag-of-words representation outperforms most dedicated sentence transformer models in terms of $k$NN classification accuracy, and the top performing language models barely outperform TF-IDF. We see this as a challenge for the NLP community. Furthermore, we use the ICLR dataset to study how the field of machine learning has changed over the last seven years, finding some improvement in gender balance. Using a 2D embedding of the abstracts' texts, we describe a shift in research topics from 2017 to 2024 and identify hedgehogs and foxes among the authors with the highest number of ICLR submissions.
Create account to get full access
Overview
- This paper explores the concept of "learning representations of learning representations" in the context of machine learning and natural language processing.
- The researchers investigate how to effectively represent and learn from the representations themselves, rather than just the initial data.
- The paper introduces a novel dataset and an "embedding challenge" to facilitate research in this area.
Plain English Explanation
The paper is about a technique called "learning representations of learning representations." This means taking the representations (or models) that are learned from data, and then learning new representations from those representations.
For example, imagine you have a machine learning model that can recognize different types of animals in images. The model has learned certain features or patterns that allow it to identify the animals. The idea behind this paper is to then take those learned features and try to learn even higher-level patterns from them.
This might allow the model to not just recognize individual animals, but to understand broader concepts like the overall structure of different animals, or how they relate to each other. The researchers create a new dataset and challenge to help drive progress in this area of research.
The core insight is that by learning from the representations themselves, rather than just the original data, we may be able to uncover deeper, more abstract knowledge. This could lead to more powerful and flexible machine learning systems that can better understand and reason about the world.
Technical Explanation
The paper introduces a novel dataset and "embedding challenge" to facilitate research on learning representations of learning representations. The dataset contains text and associated metadata, which the researchers use to create representations (embeddings) at multiple levels.
The "embedding challenge" task is to learn representations of these existing representations. In other words, the goal is to take the embeddings produced by standard techniques (e.g. BERT) and learn higher-level patterns from them.
The authors experiment with various neural network architectures and training approaches to tackle this challenge, including transfer learning and data augmentation. Their results suggest that it is indeed possible to learn meaningful representations of the learned representations, uncovering abstract concepts and relationships not present in the original data.
Critical Analysis
The paper presents a novel and promising research direction, but it also acknowledges several limitations and areas for future work. For example, the dataset and task are relatively narrow in scope, and it's unclear how well the findings would generalize to other domains or applications.
Additionally, the authors note that the specific architectures and training techniques they explore may not be the optimal approach, and there is likely room for further innovation and experimentation in this area. Scaling this type of "meta-learning" to larger and more complex datasets and models could also present significant technical challenges.
That said, the core idea of learning representations of representations is compelling and could have far-reaching implications for machine learning and artificial intelligence. If successful, such techniques could lead to more flexible, robust, and interpretable systems that can better understand and reason about the world around them.
Conclusion
This paper takes an important step towards a new frontier in machine learning: the ability to learn representations of the representations themselves. By exploring this concept, the researchers hope to uncover deeper, more abstract knowledge that can lead to more powerful and versatile AI systems.
While the current work is still exploratory, the potential benefits of this approach are significant. If successful, "learning representations of learning representations" could revolutionize how we build and deploy machine learning models, ultimately bringing us closer to artificial general intelligence (AGI) and systems that can truly understand the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Revealing Trends in Datasets from the 2022 ACL and EMNLP Conferences
Jesse Atuhurra, Hidetaka Kamigaito
0
0
Natural language processing (NLP) has grown significantly since the advent of the Transformer architecture. Transformers have given birth to pre-trained large language models (PLMs). There has been tremendous improvement in the performance of NLP systems across several tasks. NLP systems are on par or, in some cases, better than humans at accomplishing specific tasks. However, it remains the norm that emph{better quality datasets at the time of pretraining enable PLMs to achieve better performance, regardless of the task.} The need to have quality datasets has prompted NLP researchers to continue creating new datasets to satisfy particular needs. For example, the two top NLP conferences, ACL and EMNLP, accepted ninety-two papers in 2022, introducing new datasets. This work aims to uncover the trends and insights mined within these datasets. Moreover, we provide valuable suggestions to researchers interested in curating datasets in the future.
4/16/2024
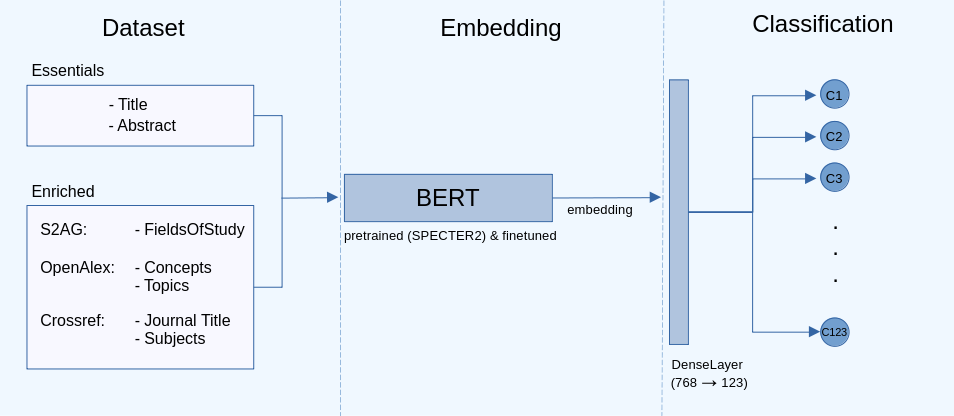
Enriched BERT Embeddings for Scholarly Publication Classification
Benjamin Wolff, Eva Seidlmayer, Konrad U. Forstner
0
0
With the rapid expansion of academic literature and the proliferation of preprints, researchers face growing challenges in manually organizing and labeling large volumes of articles. The NSLP 2024 FoRC Shared Task I addresses this challenge organized as a competition. The goal is to develop a classifier capable of predicting one of 123 predefined classes from the Open Research Knowledge Graph (ORKG) taxonomy of research fields for a given article.This paper presents our results. Initially, we enrich the dataset (containing English scholarly articles sourced from ORKG and arXiv), then leverage different pre-trained language Models (PLMs), specifically BERT, and explore their efficacy in transfer learning for this downstream task. Our experiments encompass feature-based and fine-tuned transfer learning approaches using diverse PLMs, optimized for scientific tasks, including SciBERT, SciNCL, and SPECTER2. We conduct hyperparameter tuning and investigate the impact of data augmentation from bibliographic databases such as OpenAlex, Semantic Scholar, and Crossref. Our results demonstrate that fine-tuning pre-trained models substantially enhances classification performance, with SPECTER2 emerging as the most accurate model. Moreover, enriching the dataset with additional metadata improves classification outcomes significantly, especially when integrating information from S2AG, OpenAlex and Crossref. Our best-performing approach achieves a weighted F1-score of 0.7415. Overall, our study contributes to the advancement of reliable automated systems for scholarly publication categorization, offering a potential solution to the laborious manual curation process, thereby facilitating researchers in efficiently locating relevant resources.
5/8/2024
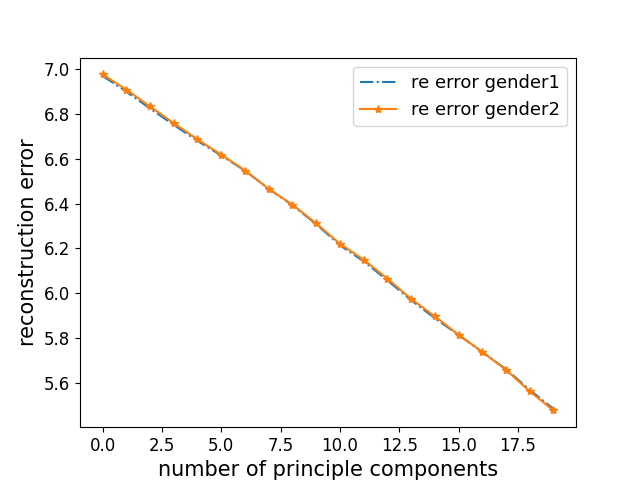
Closing the Gap in the Trade-off between Fair Representations and Accuracy
Biswajit Rout, Ananya B. Sai, Arun Rajkumar
0
0
The rapid developments of various machine learning models and their deployments in several applications has led to discussions around the importance of looking beyond the accuracies of these models. Fairness of such models is one such aspect that is deservedly gaining more attention. In this work, we analyse the natural language representations of documents and sentences (i.e., encodings) for any embedding-level bias that could potentially also affect the fairness of the downstream tasks that rely on them. We identify bias in these encodings either towards or against different sub-groups based on the difference in their reconstruction errors along various subsets of principal components. We explore and recommend ways to mitigate such bias in the encodings while also maintaining a decent accuracy in classification models that use them.
4/16/2024

ZeroDL: Zero-shot Distribution Learning for Text Clustering via Large Language Models
Hwiyeol Jo, Hyunwoo Lee, Taiwoo Park
0
0
The recent advancements in large language models (LLMs) have brought significant progress in solving NLP tasks. Notably, in-context learning (ICL) is the key enabling mechanism for LLMs to understand specific tasks and grasping nuances. In this paper, we propose a simple yet effective method to contextualize a task toward a specific LLM, by (1) observing how a given LLM describes (all or a part of) target datasets, i.e., open-ended zero-shot inference, and (2) aggregating the open-ended inference results by the LLM, and (3) finally incorporate the aggregated meta-information for the actual task. We show the effectiveness of this approach in text clustering tasks, and also highlight the importance of the contextualization through examples of the above procedure.
6/21/2024