Revealing Trends in Datasets from the 2022 ACL and EMNLP Conferences
2404.08666
0
0
Abstract
Natural language processing (NLP) has grown significantly since the advent of the Transformer architecture. Transformers have given birth to pre-trained large language models (PLMs). There has been tremendous improvement in the performance of NLP systems across several tasks. NLP systems are on par or, in some cases, better than humans at accomplishing specific tasks. However, it remains the norm that emph{better quality datasets at the time of pretraining enable PLMs to achieve better performance, regardless of the task.} The need to have quality datasets has prompted NLP researchers to continue creating new datasets to satisfy particular needs. For example, the two top NLP conferences, ACL and EMNLP, accepted ninety-two papers in 2022, introducing new datasets. This work aims to uncover the trends and insights mined within these datasets. Moreover, we provide valuable suggestions to researchers interested in curating datasets in the future.
Create account to get full access
Overview
- This paper analyzes trends in datasets from the 2022 ACL and EMNLP conferences, two of the leading natural language processing (NLP) conferences.
- The researchers collected and categorized datasets presented at these conferences to identify emerging patterns and themes in the NLP research community.
- The study provides insights into the types of tasks, domains, and data sources that are capturing the attention of NLP researchers.
Plain English Explanation
The paper examines the datasets that were used in research presented at two major NLP conferences in 2022. The researchers gathered information about these datasets, such as the types of tasks they were designed for, the subject areas they covered, and where the data came from. By analyzing this information, the researchers were able to identify trends and patterns in the kinds of data and problems that NLP researchers are currently focused on.
This can provide useful insights for the broader NLP community. It helps us understand what kinds of datasets and tasks are of greatest interest and importance to researchers right now. This knowledge can inform the development of new datasets, models, and applications to advance the field of NLP. For example, the analysis may reveal underexplored domains or data sources that could benefit from more research attention.
Technical Explanation
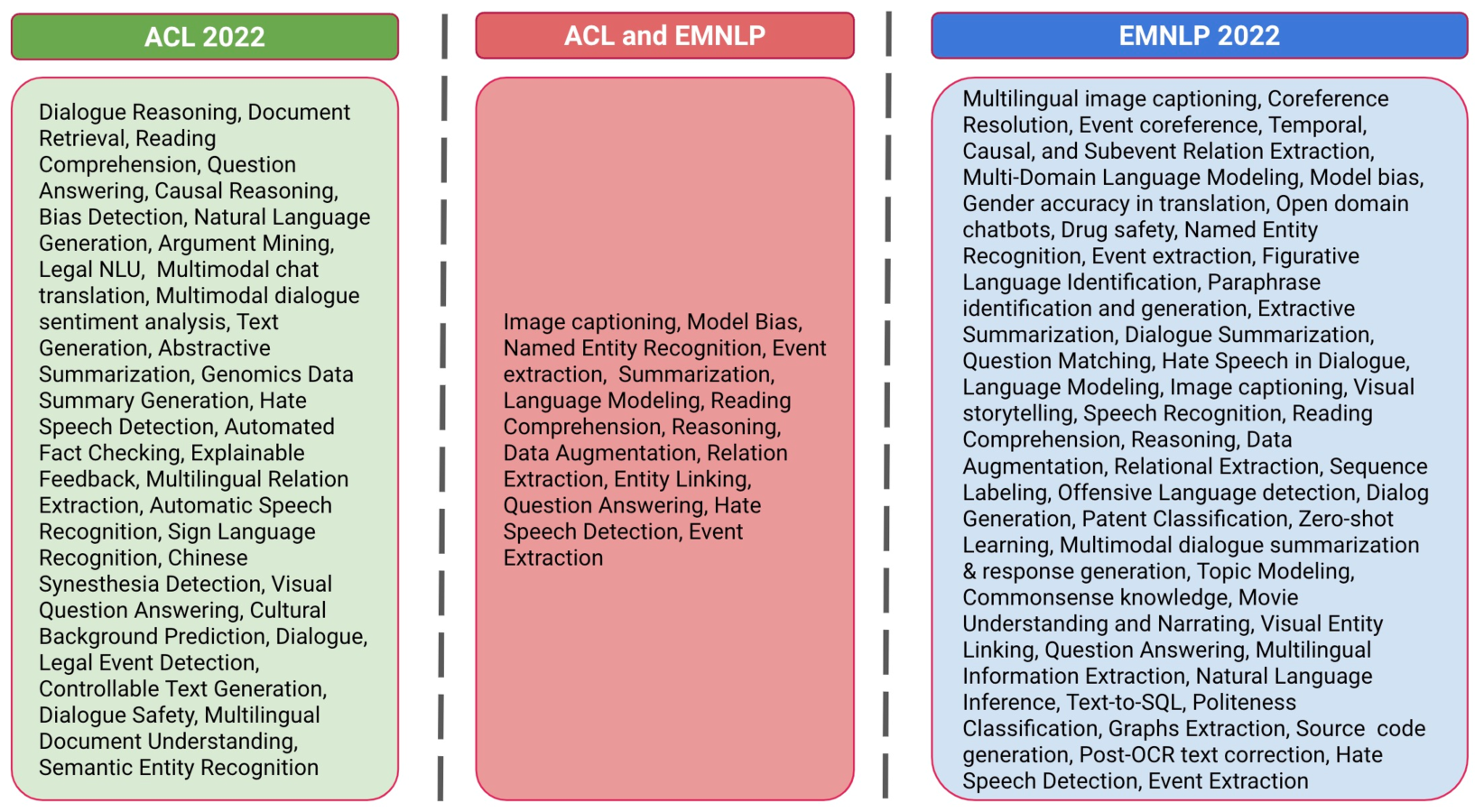
The researchers collected dataset descriptions from papers presented at the 2022 ACL and EMNLP conferences. They manually categorized these datasets along several dimensions, including task type, domain, and data source. This allowed them to identify patterns and trends in the types of datasets being used in cutting-edge NLP research.
The analysis revealed several key insights, such as:
- A strong focus on tasks related to language generation and understanding
- An emphasis on datasets covering social and cultural domains, in addition to more technical subject areas
- An increasing reliance on web-scraped and crowdsourced data, rather than more curated corpus
These findings provide valuable context for understanding the current priorities and directions of the NLP research community.
Critical Analysis
The paper offers a comprehensive look at the datasets being used in recent NLP research, but it acknowledges some limitations. For example, the analysis is limited to datasets described in conference papers, which may not capture the full breadth of datasets being used in the field.
Additionally, the categorization of datasets was done manually, which introduces the potential for subjective biases or inconsistencies. An automated approach to dataset classification could help validate and extend the findings.
The paper also does not delve deeply into the potential implications or drawbacks of the observed trends, such as the reliance on web-scraped data, which can introduce issues around privacy, bias, and data quality. Further research in this area could provide important context and caveats to the high-level trends reported in this study.
Conclusion
This paper offers a valuable snapshot of the datasets and research priorities in the NLP community, as reflected in the papers presented at two of the field's top conferences in 2022. The analysis reveals emerging themes and patterns that can help guide the development of new datasets, models, and applications to advance the state of the art in natural language processing. While the findings are informative, there is scope for further research to explore the nuances and potential implications of these trends more deeply.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
Natural Language Processing for Dialects of a Language: A Survey
Aditya Joshi, Raj Dabre, Diptesh Kanojia, Zhuang Li, Haolan Zhan, Gholamreza Haffari, Doris Dippold
0
0
State-of-the-art natural language processing (NLP) models are trained on massive training corpora, and report a superlative performance on evaluation datasets. This survey delves into an important attribute of these datasets: the dialect of a language. Motivated by the performance degradation of NLP models for dialectic datasets and its implications for the equity of language technologies, we survey past research in NLP for dialects in terms of datasets, and approaches. We describe a wide range of NLP tasks in terms of two categories: natural language understanding (NLU) (for tasks such as dialect classification, sentiment analysis, parsing, and NLU benchmarks) and natural language generation (NLG) (for summarisation, machine translation, and dialogue systems). The survey is also broad in its coverage of languages which include English, Arabic, German among others. We observe that past work in NLP concerning dialects goes deeper than mere dialect classification, and . This includes early approaches that used sentence transduction that lead to the recent approaches that integrate hypernetworks into LoRA. We expect that this survey will be useful to NLP researchers interested in building equitable language technologies by rethinking LLM benchmarks and model architectures.
4/1/2024
A Survey on Large Language Models from Concept to Implementation
Chen Wang, Jin Zhao, Jiaqi Gong
0
0
Recent advancements in Large Language Models (LLMs), particularly those built on Transformer architectures, have significantly broadened the scope of natural language processing (NLP) applications, transcending their initial use in chatbot technology. This paper investigates the multifaceted applications of these models, with an emphasis on the GPT series. This exploration focuses on the transformative impact of artificial intelligence (AI) driven tools in revolutionizing traditional tasks like coding and problem-solving, while also paving new paths in research and development across diverse industries. From code interpretation and image captioning to facilitating the construction of interactive systems and advancing computational domains, Transformer models exemplify a synergy of deep learning, data analysis, and neural network design. This survey provides an in-depth look at the latest research in Transformer models, highlighting their versatility and the potential they hold for transforming diverse application sectors, thereby offering readers a comprehensive understanding of the current and future landscape of Transformer-based LLMs in practical applications.
5/29/2024

Learning representations of learning representations
Rita Gonz'alez-M'arquez, Dmitry Kobak
0
0
The ICLR conference is unique among the top machine learning conferences in that all submitted papers are openly available. Here we present the ICLR dataset consisting of abstracts of all 24 thousand ICLR submissions from 2017-2024 with meta-data, decision scores, and custom keyword-based labels. We find that on this dataset, bag-of-words representation outperforms most dedicated sentence transformer models in terms of $k$NN classification accuracy, and the top performing language models barely outperform TF-IDF. We see this as a challenge for the NLP community. Furthermore, we use the ICLR dataset to study how the field of machine learning has changed over the last seven years, finding some improvement in gender balance. Using a 2D embedding of the abstracts' texts, we describe a shift in research topics from 2017 to 2024 and identify hedgehogs and foxes among the authors with the highest number of ICLR submissions.
4/15/2024
Using Large Language Models to Enrich the Documentation of Datasets for Machine Learning
Joan Giner-Miguelez, Abel G'omez, Jordi Cabot
0
0
Recent regulatory initiatives like the European AI Act and relevant voices in the Machine Learning (ML) community stress the need to describe datasets along several key dimensions for trustworthy AI, such as the provenance processes and social concerns. However, this information is typically presented as unstructured text in accompanying documentation, hampering their automated analysis and processing. In this work, we explore using large language models (LLM) and a set of prompting strategies to automatically extract these dimensions from documents and enrich the dataset description with them. Our approach could aid data publishers and practitioners in creating machine-readable documentation to improve the discoverability of their datasets, assess their compliance with current AI regulations, and improve the overall quality of ML models trained on them. In this paper, we evaluate the approach on 12 scientific dataset papers published in two scientific journals (Nature's Scientific Data and Elsevier's Data in Brief) using two different LLMs (GPT3.5 and Flan-UL2). Results show good accuracy with our prompt extraction strategies. Concrete results vary depending on the dimensions, but overall, GPT3.5 shows slightly better accuracy (81,21%) than FLAN-UL2 (69,13%) although it is more prone to hallucinations. We have released an open-source tool implementing our approach and a replication package, including the experiments' code and results, in an open-source repository.
5/27/2024