Learning Retrieval Augmentation for Personalized Dialogue Generation

0

Sign in to get full access
Overview
- This paper introduces a new approach for personalizing dialogue generation models using retrieval augmentation.
- The proposed method leverages user profiles and contextual information to retrieve relevant knowledge from a large corpus, which is then used to enhance the language model's responses.
- Experiments on multiple dialogue datasets show that the retrieval-augmented model outperforms strong baselines in terms of both automatic and human evaluation metrics.
Plain English Explanation
The researchers in this paper developed a new way to make dialogue generation models more personalized and relevant to individual users. Dialogue generation models are AI systems that can produce human-like responses in conversations.
The key idea is to supplement these models with additional information about the user, such as their interests, preferences, and past conversations. This supplementary information is retrieved from a large database or corpus and used to enhance the model's responses, making them more tailored to the individual.
For example, if the user is known to be interested in gardening, the model can retrieve relevant information about gardening from the database and incorporate that into its response, making the conversation more personalized and engaging for that particular user.
The researchers tested this approach on multiple dialogue datasets and found that the retrieval-augmented model outperformed other methods in terms of both automatic metrics (e.g., coherence, informativeness) and human evaluation (e.g., how natural and relevant the responses were).
Technical Explanation
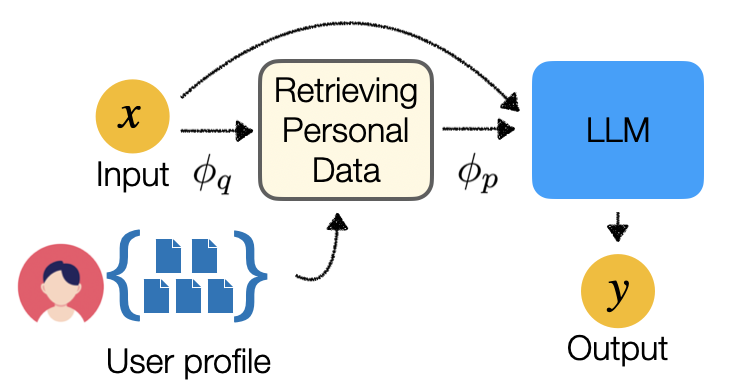
The core of the proposed approach is a retrieval-augmented generation framework, where the dialogue model is enhanced by retrieving relevant information from a large corpus based on the user's profile and the current conversation context.
Specifically, the system first encodes the user profile and the current conversation context into vector representations. It then uses these representations to retrieve the most relevant passages from a large corpus, such as Persona-DB. These retrieved passages are then concatenated with the original dialogue input and fed into the language model, which generates the final response.
The researchers experiment with different strategies for encoding the user profile and conversation context, as well as different methods for retrieving the relevant passages. They also explore ways to effectively incorporate the retrieved information into the language model, such as through attention mechanisms or prompting techniques.
The results show that the retrieval-augmented model consistently outperforms strong baseline dialogue models that do not use the additional personalized information. This demonstrates the value of leveraging user-specific knowledge to improve the relevance and quality of generated responses in personalized dialogue systems.
Critical Analysis
One potential limitation of the approach is the reliance on a pre-existing corpus of user profiles and relevant information. In real-world applications, building and maintaining such a comprehensive database may be challenging, especially for dynamic user profiles and rapidly evolving conversational contexts.
Additionally, the paper does not explore the potential biases or privacy concerns that may arise from using personal user data to guide the dialogue generation process. Careful consideration of ethical implications and data governance practices would be necessary for deploying such a system in production environments.
Further research could investigate ways to learn the retrieval and augmentation components in an end-to-end fashion, potentially reducing the reliance on pre-built knowledge bases. Exploring the tradeoffs between personalization and user privacy would also be an important direction for future work in this area.
Conclusion
This paper presents a novel approach for enhancing dialogue generation models by leveraging user-specific information through a retrieval-augmentation framework. The results demonstrate the potential of this method to improve the relevance and quality of generated responses, making dialogue systems more personalized and engaging for individual users.
While the approach shows promising results, there are important practical and ethical considerations that warrant further exploration. Addressing these challenges could lead to more robust and trustworthy personalized dialogue systems that can better serve the needs of diverse users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Retrieval Augmentation for Personalized Dialogue Generation
Qiushi Huang, Shuai Fu, Xubo Liu, Wenwu Wang, Tom Ko, Yu Zhang, Lilian Tang
Personalized dialogue generation, focusing on generating highly tailored responses by leveraging persona profiles and dialogue context, has gained significant attention in conversational AI applications. However, persona profiles, a prevalent setting in current personalized dialogue datasets, typically composed of merely four to five sentences, may not offer comprehensive descriptions of the persona about the agent, posing a challenge to generate truly personalized dialogues. To handle this problem, we propose $textbf{L}$earning Retrieval $textbf{A}$ugmentation for $textbf{P}$ersonalized $textbf{D}$ial$textbf{O}$gue $textbf{G}$eneration ($textbf{LAPDOG}$), which studies the potential of leveraging external knowledge for persona dialogue generation. Specifically, the proposed LAPDOG model consists of a story retriever and a dialogue generator. The story retriever uses a given persona profile as queries to retrieve relevant information from the story document, which serves as a supplementary context to augment the persona profile. The dialogue generator utilizes both the dialogue history and the augmented persona profile to generate personalized responses. For optimization, we adopt a joint training framework that collaboratively learns the story retriever and dialogue generator, where the story retriever is optimized towards desired ultimate metrics (e.g., BLEU) to retrieve content for the dialogue generator to generate personalized responses. Experiments conducted on the CONVAI2 dataset with ROCStory as a supplementary data source show that the proposed LAPDOG method substantially outperforms the baselines, indicating the effectiveness of the proposed method. The LAPDOG model code is publicly available for further exploration. https://github.com/hqsiswiliam/LAPDOG
Read more6/28/2024
0
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Alireza Salemi, Surya Kallumadi, Hamed Zamani
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
Read more4/10/2024
📉
0
Doing Personal LAPS: LLM-Augmented Dialogue Construction for Personalized Multi-Session Conversational Search
Hideaki Joko, Shubham Chatterjee, Andrew Ramsay, Arjen P. de Vries, Jeff Dalton, Faegheh Hasibi
The future of conversational agents will provide users with personalized information responses. However, a significant challenge in developing models is the lack of large-scale dialogue datasets that span multiple sessions and reflect real-world user preferences. Previous approaches rely on experts in a wizard-of-oz setup that is difficult to scale, particularly for personalized tasks. Our method, LAPS, addresses this by using large language models (LLMs) to guide a single human worker in generating personalized dialogues. This method has proven to speed up the creation process and improve quality. LAPS can collect large-scale, human-written, multi-session, and multi-domain conversations, including extracting user preferences. When compared to existing datasets, LAPS-produced conversations are as natural and diverse as expert-created ones, which stays in contrast with fully synthetic methods. The collected dataset is suited to train preference extraction and personalized response generation. Our results show that responses generated explicitly using extracted preferences better match user's actual preferences, highlighting the value of using extracted preferences over simple dialogue history. Overall, LAPS introduces a new method to leverage LLMs to create realistic personalized conversational data more efficiently and effectively than previous methods.
Read more5/7/2024
🛸
0
PersonaRAG: Enhancing Retrieval-Augmented Generation Systems with User-Centric Agents
Saber Zerhoudi, Michael Granitzer
Large Language Models (LLMs) struggle with generating reliable outputs due to outdated knowledge and hallucinations. Retrieval-Augmented Generation (RAG) models address this by enhancing LLMs with external knowledge, but often fail to personalize the retrieval process. This paper introduces PersonaRAG, a novel framework incorporating user-centric agents to adapt retrieval and generation based on real-time user data and interactions. Evaluated across various question answering datasets, PersonaRAG demonstrates superiority over baseline models, providing tailored answers to user needs. The results suggest promising directions for user-adapted information retrieval systems.
Read more7/15/2024