Learning Rules from KGs Guided by Language Models

0

Sign in to get full access
Overview
- This paper presents a system that learns rules from knowledge graphs (KGs) guided by language models.
- The system leverages pre-trained language models to generate rule candidates, which are then ranked and filtered to obtain high-quality rules.
- Experiments show the system can learn interpretable and accurate rules, outperforming previous rule learning approaches.
Plain English Explanation
The paper describes a method for learning rules from knowledge graphs. Knowledge graphs are structured databases that store information about entities (like people, places, or things) and the relationships between them. The researchers developed a system that uses large language models - powerful AI models trained on massive amounts of text data - to automatically generate potential rules that capture patterns in the knowledge graph.
These rule candidates are then evaluated and filtered to keep only the most accurate and interpretable ones. This allows the system to discover meaningful insights and regularities in the knowledge graph data, which could be useful for tasks like question answering, recommendation systems, or knowledge base completion.
Compared to previous approaches, the language model-guided system was able to learn higher-quality rules that better reflect the underlying structure and semantics of the knowledge graph. The researchers demonstrate the effectiveness of their approach through experiments on several benchmark datasets.
Technical Explanation
The key components of the system are:
-
Rule Candidate Generation: A pre-trained language model is used to generate candidate rules by prompting it with templates like "X <relation> Y if Z". The model completes the templates to produce rule candidates.
-
Rule Ranking: The generated rule candidates are scored based on their logical coherence, specificity, and coverage of the knowledge graph. This ranking process filters out low-quality rules.
-
Rule Refinement: The top-ranked rules are further refined by considering alternative formulations and removing redundant or overly specific rules.
The researchers evaluate their system on several standard knowledge graph benchmarks, comparing it to prior rule learning approaches. They find that their language model-guided system outperforms these baselines in terms of the accuracy, interpretability, and logical consistency of the learned rules.
Critical Analysis
The paper presents a novel and promising approach for learning rules from knowledge graphs. A key strength is its use of language models, which allows the system to generate rule candidates that are grounded in natural language understanding rather than relying solely on structural patterns in the graph.
However, the paper does not fully address potential limitations or caveats of the approach. For example, the performance of the system may depend heavily on the choice of pre-trained language model and the quality of the knowledge graph data. Applying the method to real-world, noisy KGs could present additional challenges.
Additionally, the paper does not explore the generalizability of the learned rules or how they might be applied to downstream tasks beyond the evaluation benchmarks. Further research is needed to understand the broader implications and practical applications of this rule learning approach.
Conclusion
This paper introduces an innovative system that can learn interpretable rules from knowledge graphs by leveraging the power of large language models. The results demonstrate the potential of this approach to uncover meaningful patterns and insights from structured knowledge data.
As research on the interplay between large language models and knowledge graphs continues to evolve, this work represents an important step forward in bridging the gap between symbolic and statistical AI. Further development and real-world application of such techniques could lead to significant advancements in areas like commonsense reasoning, knowledge-powered language understanding, and knowledge base completion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Rules from KGs Guided by Language Models
Zihang Peng, Daria Stepanova, Vinh Thinh Ho, Heike Adel, Alessandra Russo, Simon Ott
Advances in information extraction have enabled the automatic construction of large knowledge graphs (e.g., Yago, Wikidata or Google KG), which are widely used in many applications like semantic search or data analytics. However, due to their semi-automatic construction, KGs are often incomplete. Rule learning methods, concerned with the extraction of frequent patterns from KGs and casting them into rules, can be applied to predict potentially missing facts. A crucial step in this process is rule ranking. Ranking of rules is especially challenging over highly incomplete or biased KGs (e.g., KGs predominantly storing facts about famous people), as in this case biased rules might fit the data best and be ranked at the top based on standard statistical metrics like rule confidence. To address this issue, prior works proposed to rank rules not only relying on the original KG but also facts predicted by a KG embedding model. At the same time, with the recent rise of Language Models (LMs), several works have claimed that LMs can be used as alternative means for KG completion. In this work, our goal is to verify to which extent the exploitation of LMs is helpful for improving the quality of rule learning systems.
Read more9/14/2024
💬
0
Combining Knowledge Graphs and Large Language Models
Amanda Kau, Xuzeng He, Aishwarya Nambissan, Aland Astudillo, Hui Yin, Amir Aryani
In recent years, Natural Language Processing (NLP) has played a significant role in various Artificial Intelligence (AI) applications such as chatbots, text generation, and language translation. The emergence of large language models (LLMs) has greatly improved the performance of these applications, showing astonishing results in language understanding and generation. However, they still show some disadvantages, such as hallucinations and lack of domain-specific knowledge, that affect their performance in real-world tasks. These issues can be effectively mitigated by incorporating knowledge graphs (KGs), which organise information in structured formats that capture relationships between entities in a versatile and interpretable fashion. Likewise, the construction and validation of KGs present challenges that LLMs can help resolve. The complementary relationship between LLMs and KGs has led to a trend that combines these technologies to achieve trustworthy results. This work collected 28 papers outlining methods for KG-powered LLMs, LLM-based KGs, and LLM-KG hybrid approaches. We systematically analysed and compared these approaches to provide a comprehensive overview highlighting key trends, innovative techniques, and common challenges. This synthesis will benefit researchers new to the field and those seeking to deepen their understanding of how KGs and LLMs can be effectively combined to enhance AI applications capabilities.
Read more7/10/2024
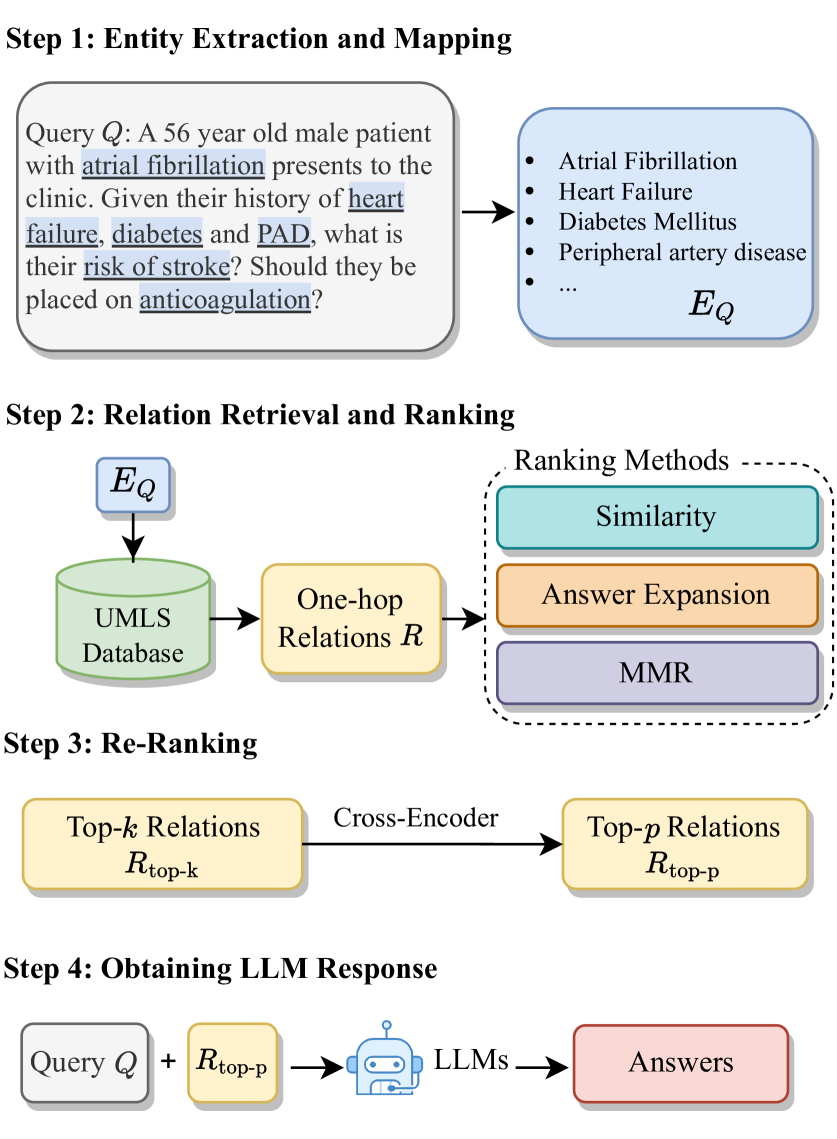
0
KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques
Rui Yang, Haoran Liu, Edison Marrese-Taylor, Qingcheng Zeng, Yu He Ke, Wanxin Li, Lechao Cheng, Qingyu Chen, James Caverlee, Yutaka Matsuo, Irene Li
Large language models (LLMs) have demonstrated impressive generative capabilities with the potential to innovate in medicine. However, the application of LLMs in real clinical settings remains challenging due to the lack of factual consistency in the generated content. In this work, we develop an augmented LLM framework, KG-Rank, which leverages a medical knowledge graph (KG) along with ranking and re-ranking techniques, to improve the factuality of long-form question answering (QA) in the medical domain. Specifically, when receiving a question, KG-Rank automatically identifies medical entities within the question and retrieves the related triples from the medical KG to gather factual information. Subsequently, KG-Rank innovatively applies multiple ranking techniques to refine the ordering of these triples, providing more relevant and precise information for LLM inference. To the best of our knowledge, KG-Rank is the first application of KG combined with ranking models in medical QA specifically for generating long answers. Evaluation on four selected medical QA datasets demonstrates that KG-Rank achieves an improvement of over 18% in ROUGE-L score. Additionally, we extend KG-Rank to open domains, including law, business, music, and history, where it realizes a 14% improvement in ROUGE-L score, indicating the effectiveness and great potential of KG-Rank.
Read more7/8/2024

0
Knowledge Graph-Enhanced Large Language Models via Path Selection
Haochen Liu, Song Wang, Yaochen Zhu, Yushun Dong, Jundong Li
Large Language Models (LLMs) have shown unprecedented performance in various real-world applications. However, they are known to generate factually inaccurate outputs, a.k.a. the hallucination problem. In recent years, incorporating external knowledge extracted from Knowledge Graphs (KGs) has become a promising strategy to improve the factual accuracy of LLM-generated outputs. Nevertheless, most existing explorations rely on LLMs themselves to perform KG knowledge extraction, which is highly inflexible as LLMs can only provide binary judgment on whether a certain knowledge (e.g., a knowledge path in KG) should be used. In addition, LLMs tend to pick only knowledge with direct semantic relationship with the input text, while potentially useful knowledge with indirect semantics can be ignored. In this work, we propose a principled framework KELP with three stages to handle the above problems. Specifically, KELP is able to achieve finer granularity of flexible knowledge extraction by generating scores for knowledge paths with input texts via latent semantic matching. Meanwhile, knowledge paths with indirect semantic relationships with the input text can also be considered via trained encoding between the selected paths in KG and the input text. Experiments on real-world datasets validate the effectiveness of KELP.
Read more6/21/2024