Learning Segmented 3D Gaussians via Efficient Feature Unprojection for Zero-shot Neural Scene Segmentation

0
Sign in to get full access
Overview
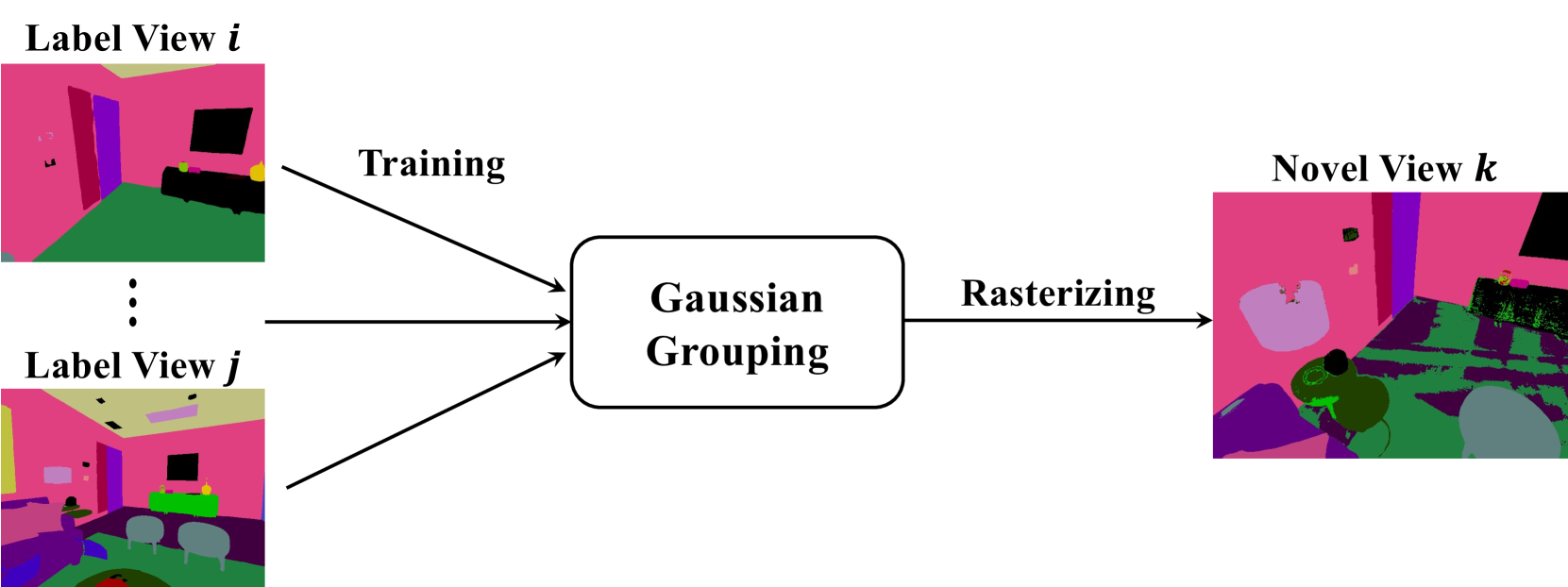
- The paper introduces CoSSegGaussians, a method for compact and swift segmentation of 3D Gaussians in real-world scenes.
- The technique models object shapes as 3D Gaussian distributions and performs efficient segmentation without relying on heavy neural networks.
- It achieves high-quality results while being more compact and faster than existing approaches.
Plain English Explanation
The paper presents a new way to efficiently segment, or divide up, the objects in a 3D scene. Instead of using large, complex neural networks, the method models the shapes of objects as simple 3D Gaussian distributions. A Gaussian distribution is a bell-shaped curve that can be described by just a few parameters.
This compact and fast approach can identify and separate the individual objects in a 3D scene, such as a room filled with furniture. It does this without needing huge neural networks that take a lot of time and computing power to run.
The key idea is to represent each object as a 3D Gaussian - just a few numbers that capture the object's size, location, and shape. This unified framework for 3D scene understanding allows the method to quickly segment the scene into the individual objects, even in complex real-world environments.
Technical Explanation
The CoSSegGaussians method models each object in a 3D scene as a 3D Gaussian distribution. This compact representation captures the object's size, position, and shape using just a few parameters.
The approach first generates an initial set of Gaussian hypotheses that potentially correspond to objects in the scene. It then performs an efficient optimization process to segment the scene into the individual 4D Gaussians that best explain the observed data.
This optimization leverages several key innovations, including a fast clustering algorithm and a novel objective function. The result is a highly efficient 3D instance segmentation that outperforms existing neural network-based approaches in terms of both accuracy and computational cost.
Critical Analysis
The paper presents a compelling alternative to the neural network-heavy approaches that dominate 3D scene segmentation today. By using a compact Gaussian representation, CoSSegGaussians achieves high-quality results while being significantly more efficient.
However, the technique does have some limitations. It assumes that object shapes can be well-approximated by Gaussians, which may not always be the case for complex real-world objects. The authors acknowledge this and suggest extensions to handle more general shape models.
Additionally, the method currently relies on good initialization of the Gaussian hypotheses. Developing more robust initialization strategies could further improve the technique's performance and applicability.
Overall, CoSSegGaussians represents an interesting and promising direction for 3D scene understanding. Its efficiency and accuracy make it a compelling alternative to existing neural network-based approaches, particularly in resource-constrained settings. With further refinements, it could become a valuable tool for a wide range of 3D perception and robotics applications.
Conclusion
The CoSSegGaussians paper introduces a novel approach to 3D scene segmentation that models objects as compact 3D Gaussian distributions. This compact and efficient representation allows the method to outperform neural network-based techniques in terms of both accuracy and computational cost.
By leveraging the power of Gaussian models, CoSSegGaussians offers a promising alternative to the resource-intensive neural network solutions that currently dominate the field of 3D scene understanding. With further refinements, this approach could become a valuable tool for a wide range of applications, from robotic perception to augmented reality.
The paper's innovative techniques and compelling results make it an important contribution to the ongoing efforts to develop more efficient and effective 3D scene segmentation methods. As the demand for real-time 3D analysis continues to grow, approaches like CoSSegGaussians will likely play an increasingly important role in powering the next generation of 3D perception systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Segmented 3D Gaussians via Efficient Feature Unprojection for Zero-shot Neural Scene Segmentation
Bin Dou, Tianyu Zhang, Zhaohui Wang, Yongjia Ma, Zejian Yuan
Zero-shot neural scene segmentation, which reconstructs 3D neural segmentation field without manual annotations, serves as an effective way for scene understanding. However, existing models, especially the efficient 3D Gaussian-based methods, struggle to produce compact segmentation results. This issue stems primarily from their redundant learnable attributes assigned on individual Gaussians, leading to a lack of robustness against the 3D-inconsistencies in zero-shot generated raw labels. To address this problem, our work, named Compact Segmented 3D Gaussians (CoSegGaussians), proposes the Feature Unprojection and Fusion module as the segmentation field, which utilizes a shallow decoder generalizable for all Gaussians based on high-level features. Specifically, leveraging the learned Gaussian geometric parameters, semantic-aware image-based features are introduced into the scene via our unprojection technique. The lifted features, together with spatial information, are fed into the multi-scale aggregation decoder to generate segmentation identities for all Gaussians. Furthermore, we design CoSeg Loss to boost model robustness against 3D-inconsistent noises. Experimental results show that our model surpasses baselines on zero-shot semantic segmentation task, improving by ~10% mIoU over the best baseline. Code and more results will be available at https://David-Dou.github.io/CoSegGaussians.
Read more7/30/2024

0
Contrastive Gaussian Clustering: Weakly Supervised 3D Scene Segmentation
Myrna C. Silva, Mahtab Dahaghin, Matteo Toso, Alessio Del Bue
We introduce Contrastive Gaussian Clustering, a novel approach capable of provide segmentation masks from any viewpoint and of enabling 3D segmentation of the scene. Recent works in novel-view synthesis have shown how to model the appearance of a scene via a cloud of 3D Gaussians, and how to generate accurate images from a given viewpoint by projecting on it the Gaussians before $alpha$ blending their color. Following this example, we train a model to include also a segmentation feature vector for each Gaussian. These can then be used for 3D scene segmentation, by clustering Gaussians according to their feature vectors; and to generate 2D segmentation masks, by projecting the Gaussians on a plane and $alpha$ blending over their segmentation features. Using a combination of contrastive learning and spatial regularization, our method can be trained on inconsistent 2D segmentation masks, and still learn to generate segmentation masks consistent across all views. Moreover, the resulting model is extremely accurate, improving the IoU accuracy of the predicted masks by $+8%$ over the state of the art. Code and trained models will be released soon.
Read more4/22/2024

0
Click-Gaussian: Interactive Segmentation to Any 3D Gaussians
Seokhun Choi, Hyeonseop Song, Jaechul Kim, Taehyeong Kim, Hoseok Do
Interactive segmentation of 3D Gaussians opens a great opportunity for real-time manipulation of 3D scenes thanks to the real-time rendering capability of 3D Gaussian Splatting. However, the current methods suffer from time-consuming post-processing to deal with noisy segmentation output. Also, they struggle to provide detailed segmentation, which is important for fine-grained manipulation of 3D scenes. In this study, we propose Click-Gaussian, which learns distinguishable feature fields of two-level granularity, facilitating segmentation without time-consuming post-processing. We delve into challenges stemming from inconsistently learned feature fields resulting from 2D segmentation obtained independently from a 3D scene. 3D segmentation accuracy deteriorates when 2D segmentation results across the views, primary cues for 3D segmentation, are in conflict. To overcome these issues, we propose Global Feature-guided Learning (GFL). GFL constructs the clusters of global feature candidates from noisy 2D segments across the views, which smooths out noises when training the features of 3D Gaussians. Our method runs in 10 ms per click, 15 to 130 times as fast as the previous methods, while also significantly improving segmentation accuracy. Our project page is available at https://seokhunchoi.github.io/Click-Gaussian
Read more7/17/2024

0
CUS3D :CLIP-based Unsupervised 3D Segmentation via Object-level Denoise
Fuyang Yu, Runze Tian, Zhen Wang, Xiaochuan Wang, Xiaohui Liang
To ease the difficulty of acquiring annotation labels in 3D data, a common method is using unsupervised and open-vocabulary semantic segmentation, which leverage 2D CLIP semantic knowledge. In this paper, unlike previous research that ignores the ``noise'' raised during feature projection from 2D to 3D, we propose a novel distillation learning framework named CUS3D. In our approach, an object-level denosing projection module is designed to screen out the ``noise'' and ensure more accurate 3D feature. Based on the obtained features, a multimodal distillation learning module is designed to align the 3D feature with CLIP semantic feature space with object-centered constrains to achieve advanced unsupervised semantic segmentation. We conduct comprehensive experiments in both unsupervised and open-vocabulary segmentation, and the results consistently showcase the superiority of our model in achieving advanced unsupervised segmentation results and its effectiveness in open-vocabulary segmentation.
Read more9/24/2024