Learning Semantic Traversability with Egocentric Video and Automated Annotation Strategy
2406.02989
0
0

Abstract
For reliable autonomous robot navigation in urban settings, the robot must have the ability to identify semantically traversable terrains in the image based on the semantic understanding of the scene. This reasoning ability is based on semantic traversability, which is frequently achieved using semantic segmentation models fine-tuned on the testing domain. This fine-tuning process often involves manual data collection with the target robot and annotation by human labelers which is prohibitively expensive and unscalable. In this work, we present an effective methodology for training a semantic traversability estimator using egocentric videos and an automated annotation process. Egocentric videos are collected from a camera mounted on a pedestrian's chest. The dataset for training the semantic traversability estimator is then automatically generated by extracting semantically traversable regions in each video frame using a recent foundation model in image segmentation and its prompting technique. Extensive experiments with videos taken across several countries and cities, covering diverse urban scenarios, demonstrate the high scalability and generalizability of the proposed annotation method. Furthermore, performance analysis and real-world deployment for autonomous robot navigation showcase that the trained semantic traversability estimator is highly accurate, able to handle diverse camera viewpoints, computationally light, and real-world applicable. The summary video is available at https://youtu.be/EUVoH-wA-lA.
Create account to get full access
Overview
- This paper presents a novel approach for learning semantic traversability from egocentric video data using an automated annotation strategy.
- The proposed method allows robots to understand the traversability of their environment by learning to identify traversable and non-traversable regions from first-person video footage.
- The authors demonstrate the effectiveness of their approach on both indoor and outdoor datasets, showing significant improvements over previous methods.
Plain English Explanation
The paper describes a new way for robots to understand the world around them and determine which areas are safe to travel through. Traditional methods for this task, known as
In contrast, this approach uses a deep learning model trained on egocentric (first-person) video data. The key insight is that by watching an agent (like a person or robot) move through an environment, the model can learn to identify traversable regions (areas that can be safely walked on) and non-traversable regions (obstacles, dangerous terrain, etc.). This is done through an
The authors show that their approach works well in both indoor and outdoor settings, outperforming previous methods. This could be useful for a variety of robotic applications, such as navigation, exploration, and path planning. By understanding the traversability of the environment, robots can more safely and efficiently navigate complex real-world spaces.
Technical Explanation
The paper proposes a method for learning semantic traversability from egocentric video using an automated annotation strategy. The key components are:
-
Egocentric Video Input: The model takes first-person video footage as input, which captures the agent's (e.g., a person or robot's) view of the environment as they move through it.
-
Automated Annotation: Rather than manually labeling the traversability of the environment, the authors develop an automated approach that infers traversable and non-traversable regions directly from the video data. This is done by analyzing the agent's motion and interaction with the environment.
-
Semantic Traversability Estimation: A deep learning model is trained on the automatically annotated video data to learn to predict the traversability of different regions in the environment. This allows the model to generalize to new scenes and environments.
The authors evaluate their approach on both indoor and outdoor datasets, comparing it to previous methods for traversability estimation. They demonstrate significant improvements in both accuracy and efficiency, highlighting the benefits of using egocentric video and automated annotation for this task.
Critical Analysis
The paper presents a promising approach for addressing the challenge of traversability estimation, a critical capability for autonomous navigation and exploration. The use of egocentric video and automated annotation is a clever way to overcome the limitations of traditional methods that rely on costly manual labeling.
However, the paper could have provided more details on the specific techniques used for the automated annotation process and the training of the deep learning model. Additionally, the authors could have discussed potential limitations or edge cases of their approach, such as how it might perform in highly unstructured or dynamic environments.
It would also be valuable to see how this method compares to other recent advances in the field, such as the use of weakly supervised learning (W-RIZZ) or the integration of semantic understanding (VIPLanner).
Overall, the paper presents an interesting and potentially impactful contribution to the field of vision-based navigation and semantic scene understanding. Further research and development in this area could lead to significant improvements in the ability of robots to safely and effectively navigate complex environments.
Conclusion
This paper introduces a novel approach for learning semantic traversability from egocentric video data using an automated annotation strategy. By leveraging first-person video and avoiding the need for costly manual labeling, the proposed method can effectively train deep learning models to understand the traversability of different regions in an environment.
The authors demonstrate the effectiveness of their approach on both indoor and outdoor datasets, showing significant improvements over previous traversability estimation techniques. This could have important implications for a wide range of robotic applications, such as navigation, exploration, and path planning, by enabling robots to more safely and efficiently navigate complex real-world spaces.
While the paper could have provided additional details and comparisons to related work, it presents a promising step forward in the field of vision-based navigation and semantic scene understanding. Further research in this area has the potential to unlock new capabilities for autonomous systems and enhance their ability to interact with and understand the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
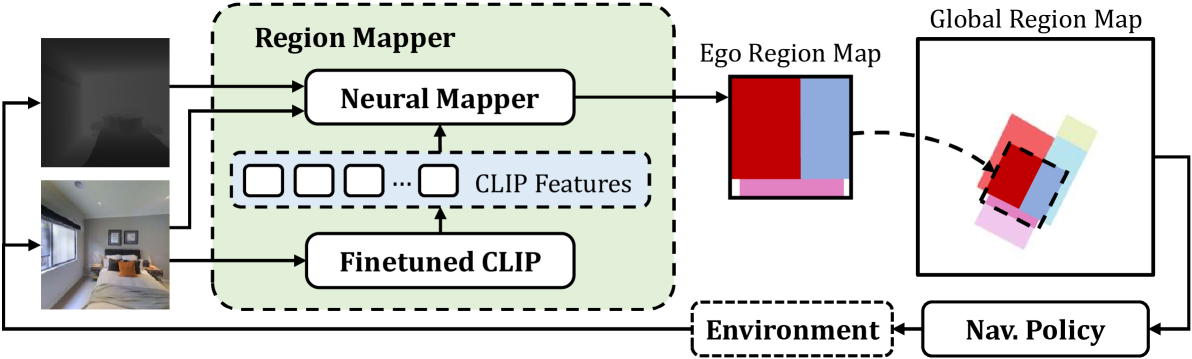
Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
Roberto Bigazzi, Lorenzo Baraldi, Shreyas Kousik, Rita Cucchiara, Marco Pavone
0
0
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
4/16/2024

W-RIZZ: A Weakly-Supervised Framework for Relative Traversability Estimation in Mobile Robotics
Andre Schreiber, Arun N. Sivakumar, Peter Du, Mateus V. Gasparino, Girish Chowdhary, Katherine Driggs-Campbell
0
0
Successful deployment of mobile robots in unstructured domains requires an understanding of the environment and terrain to avoid hazardous areas, getting stuck, and colliding with obstacles. Traversability estimation--which predicts where in the environment a robot can travel--is one prominent approach that tackles this problem. Existing geometric methods may ignore important semantic considerations, while semantic segmentation approaches involve a tedious labeling process. Recent self-supervised methods reduce labeling tedium, but require additional data or models and tend to struggle to explicitly label untraversable areas. To address these limitations, we introduce a weakly-supervised method for relative traversability estimation. Our method involves manually annotating the relative traversability of a small number of point pairs, which significantly reduces labeling effort compared to traditional segmentation-based methods and avoids the limitations of self-supervised methods. We further improve the performance of our method through a novel cross-image labeling strategy and loss function. We demonstrate the viability and performance of our method through deployment on a mobile robot in outdoor environments.
6/6/2024

Monocular Localization with Semantics Map for Autonomous Vehicles
Jixiang Wan, Xudong Zhang, Shuzhou Dong, Yuwei Zhang, Yuchen Yang, Ruoxi Wu, Ye Jiang, Jijunnan Li, Jinquan Lin, Ming Yang
0
0
Accurate and robust localization remains a significant challenge for autonomous vehicles. The cost of sensors and limitations in local computational efficiency make it difficult to scale to large commercial applications. Traditional vision-based approaches focus on texture features that are susceptible to changes in lighting, season, perspective, and appearance. Additionally, the large storage size of maps with descriptors and complex optimization processes hinder system performance. To balance efficiency and accuracy, we propose a novel lightweight visual semantic localization algorithm that employs stable semantic features instead of low-level texture features. First, semantic maps are constructed offline by detecting semantic objects, such as ground markers, lane lines, and poles, using cameras or LiDAR sensors. Then, online visual localization is performed through data association of semantic features and map objects. We evaluated our proposed localization framework in the publicly available KAIST Urban dataset and in scenarios recorded by ourselves. The experimental results demonstrate that our method is a reliable and practical localization solution in various autonomous driving localization tasks.
6/7/2024
⛏️
ViPlanner: Visual Semantic Imperative Learning for Local Navigation
Pascal Roth, Julian Nubert, Fan Yang, Mayank Mittal, Marco Hutter
0
0
Real-time path planning in outdoor environments still challenges modern robotic systems due to differences in terrain traversability, diverse obstacles, and the necessity for fast decision-making. Established approaches have primarily focused on geometric navigation solutions, which work well for structured geometric obstacles but have limitations regarding the semantic interpretation of different terrain types and their affordances. Moreover, these methods fail to identify traversable geometric occurrences, such as stairs. To overcome these issues, we introduce ViPlanner, a learned local path planning approach that generates local plans based on geometric and semantic information. The system is trained using the Imperative Learning paradigm, for which the network weights are optimized end-to-end based on the planning task objective. This optimization uses a differentiable formulation of a semantic costmap, which enables the planner to distinguish between the traversability of different terrains and accurately identify obstacles. The semantic information is represented in 30 classes using an RGB colorspace that can effectively encode the multiple levels of traversability. We show that the planner can adapt to diverse real-world environments without requiring any real-world training. In fact, the planner is trained purely in simulation, enabling a highly scalable training data generation. Experimental results demonstrate resistance to noise, zero-shot sim-to-real transfer, and a decrease of 38.02% in terms of traversability cost compared to purely geometric-based approaches. Code and models are made publicly available: https://github.com/leggedrobotics/viplanner.
5/24/2024