Learning the Target Network in Function Space

0

Sign in to get full access
Overview
- The paper discusses learning the target network in function space for deep reinforcement learning (RL) algorithms.
- It proposes a novel approach to train the target network that aims to stabilize and improve the performance of off-policy RL algorithms.
- The key ideas include: (1) learning the target network in function space instead of parameter space, and (2) leveraging over-parameterization to stabilize the learning process.
Plain English Explanation
In deep reinforcement learning, the target network is a copy of the main neural network that is used to calculate the target values for the learning updates. Typically, the target network is updated periodically by copying the parameters from the main network. However, this can lead to instability and poor performance, especially in off-policy settings.
The researchers in this paper propose a new way to learn the target network in function space rather than parameter space. This means that instead of directly copying the network parameters, they train the target network to mimic the function represented by the main network. Importantly, they do this by over-parameterizing the target network, which means giving it more parameters than needed to represent the function.
The key insight is that over-parameterization can stabilize the learning process of the target network. This is because the extra parameters provide the target network with more flexibility to adapt and closely match the function of the main network, without getting stuck in poor local optima.
By learning the target network in function space and leveraging over-parameterization, the researchers show that they can improve the performance of off-policy deep RL algorithms compared to the standard approach of periodically copying parameters.
Technical Explanation
The paper starts by revisiting the target network in deep reinforcement learning. In off-policy RL algorithms like DQN and TD3, the target network is used to compute the target values for the Q-function or value function updates. Traditionally, the target network is updated by periodically copying the parameters from the main network.
However, the authors argue that this parameter-space update can lead to instability and poor performance, especially in off-policy settings. To address this, they propose to learn the target network in function space instead of parameter space.
The key idea is to over-parameterize the target network, giving it more parameters than needed to represent the same function as the main network. This over-parameterization allows the target network to more closely match the function of the main network, without getting stuck in poor local optima.
Mathematically, the authors formulate the target network learning as an optimization problem, where the goal is to find the target network parameters that minimize the distance between the target network function and the main network function in function space.
They show that this function-space learning of the target network can stabilize the learning process and improve the performance of off-policy RL algorithms compared to the standard parameter-space update.
Critical Analysis
The paper presents a novel and interesting approach to learning the target network in deep reinforcement learning. The key idea of learning the target network in function space rather than parameter space, and leveraging over-parameterization to stabilize the learning process, is a promising direction.
One potential limitation is that the over-parameterization of the target network may increase the computational complexity and memory requirements of the algorithm, especially for larger networks. The authors do not provide a detailed analysis of the computational overhead or memory usage of their approach compared to the standard target network update.
Additionally, the theoretical analysis in the paper focuses on the convergence of the target network learning, but does not provide a comprehensive empirical evaluation across a wide range of RL tasks and environments. Further experimental validation would help to better understand the practical benefits and limitations of the proposed approach.
It would also be interesting to explore the connection between this function-space target network learning and other related concepts in deep learning, such as neural tangent kernels and lazy training, which also leverage over-parameterization to facilitate learning.
Conclusion
This paper presents a novel approach to learning the target network in function space for deep reinforcement learning. By over-parameterizing the target network and optimizing it to match the function of the main network, the authors show that they can stabilize the learning process and improve the performance of off-policy RL algorithms.
The key insights and technical contributions of this work have the potential to advance the state of the art in deep RL and inspire further research in this direction. While there are some potential limitations to consider, the function-space target network learning is a promising direction that warrants further investigation and empirical validation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning the Target Network in Function Space
Kavosh Asadi, Yao Liu, Shoham Sabach, Ming Yin, Rasool Fakoor
We focus on the task of learning the value function in the reinforcement learning (RL) setting. This task is often solved by updating a pair of online and target networks while ensuring that the parameters of these two networks are equivalent. We propose Lookahead-Replicate (LR), a new value-function approximation algorithm that is agnostic to this parameter-space equivalence. Instead, the LR algorithm is designed to maintain an equivalence between the two networks in the function space. This value-based equivalence is obtained by employing a new target-network update. We show that LR leads to a convergent behavior in learning the value function. We also present empirical results demonstrating that LR-based target-network updates significantly improve deep RL on the Atari benchmark.
Read more9/24/2024
0
Target Networks and Over-parameterization Stabilize Off-policy Bootstrapping with Function Approximation
Fengdi Che, Chenjun Xiao, Jincheng Mei, Bo Dai, Ramki Gummadi, Oscar A Ramirez, Christopher K Harris, A. Rupam Mahmood, Dale Schuurmans
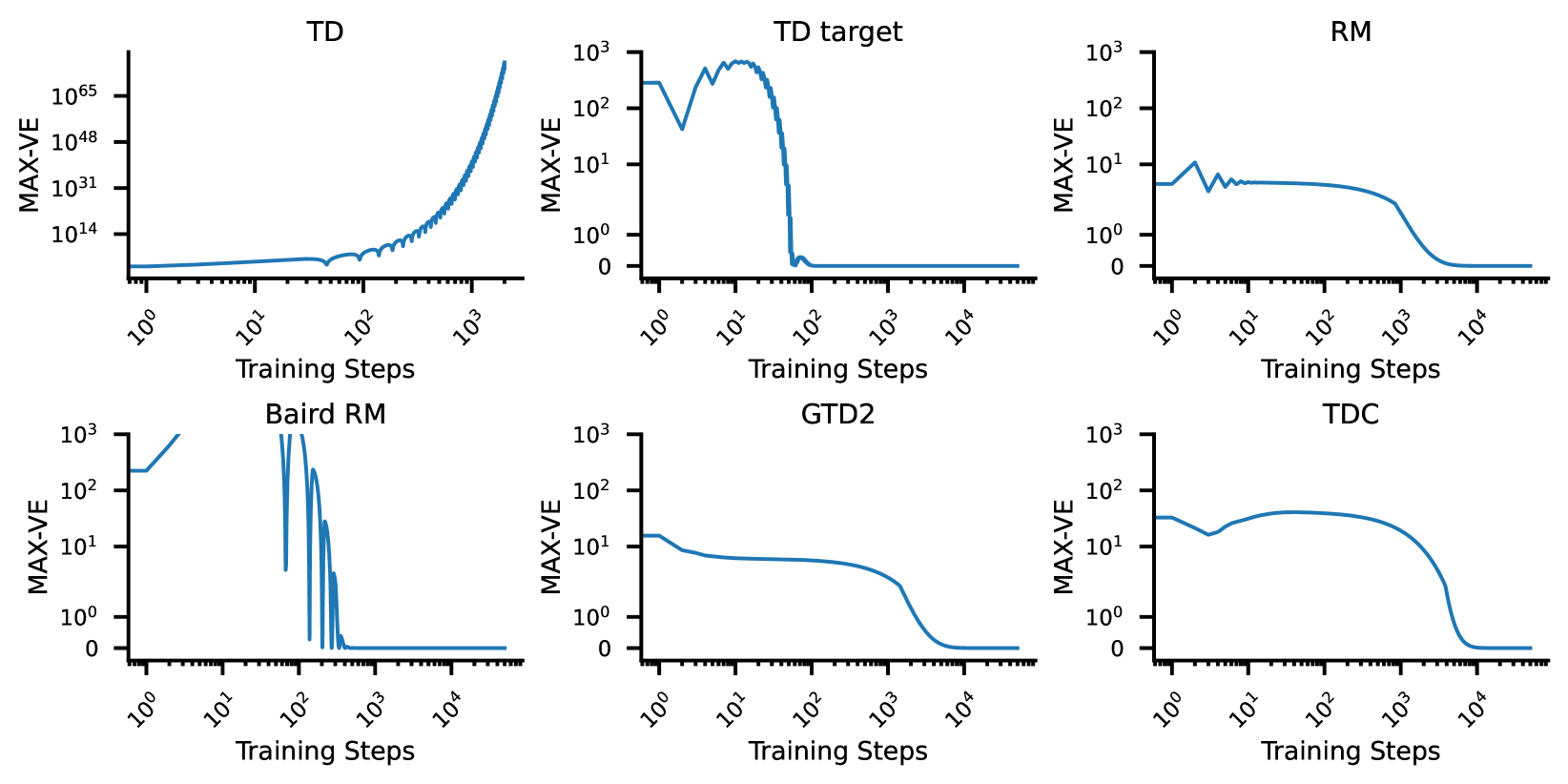
We prove that the combination of a target network and over-parameterized linear function approximation establishes a weaker convergence condition for bootstrapped value estimation in certain cases, even with off-policy data. Our condition is naturally satisfied for expected updates over the entire state-action space or learning with a batch of complete trajectories from episodic Markov decision processes. Notably, using only a target network or an over-parameterized model does not provide such a convergence guarantee. Additionally, we extend our results to learning with truncated trajectories, showing that convergence is achievable for all tasks with minor modifications, akin to value truncation for the final states in trajectories. Our primary result focuses on temporal difference estimation for prediction, providing high-probability value estimation error bounds and empirical analysis on Baird's counterexample and a Four-room task. Furthermore, we explore the control setting, demonstrating that similar convergence conditions apply to Q-learning.
Read more6/3/2024
🏷️
0
Is Value Functions Estimation with Classification Plug-and-play for Offline Reinforcement Learning?
Denis Tarasov, Kirill Brilliantov, Dmitrii Kharlapenko
In deep Reinforcement Learning (RL), value functions are typically approximated using deep neural networks and trained via mean squared error regression objectives to fit the true value functions. Recent research has proposed an alternative approach, utilizing the cross-entropy classification objective, which has demonstrated improved performance and scalability of RL algorithms. However, existing study have not extensively benchmarked the effects of this replacement across various domains, as the primary objective was to demonstrate the efficacy of the concept across a broad spectrum of tasks, without delving into in-depth analysis. Our work seeks to empirically investigate the impact of such a replacement in an offline RL setup and analyze the effects of different aspects on performance. Through large-scale experiments conducted across a diverse range of tasks using different algorithms, we aim to gain deeper insights into the implications of this approach. Our results reveal that incorporating this change can lead to superior performance over state-of-the-art solutions for some algorithms in certain tasks, while maintaining comparable performance levels in other tasks, however for other algorithms this modification might lead to the dramatic performance drop. This findings are crucial for further application of classification approach in research and practical tasks.
Read more6/11/2024

0
Dissecting Deep RL with High Update Ratios: Combatting Value Divergence
Marcel Hussing, Claas Voelcker, Igor Gilitschenski, Amir-massoud Farahmand, Eric Eaton
We show that deep reinforcement learning algorithms can retain their ability to learn without resetting network parameters in settings where the number of gradient updates greatly exceeds the number of environment samples by combatting value function divergence. Under large update-to-data ratios, a recent study by Nikishin et al. (2022) suggested the emergence of a primacy bias, in which agents overfit early interactions and downplay later experience, impairing their ability to learn. In this work, we investigate the phenomena leading to the primacy bias. We inspect the early stages of training that were conjectured to cause the failure to learn and find that one fundamental challenge is a long-standing acquaintance: value function divergence. Overinflated Q-values are found not only on out-of-distribution but also in-distribution data and can be linked to overestimation on unseen action prediction propelled by optimizer momentum. We employ a simple unit-ball normalization that enables learning under large update ratios, show its efficacy on the widely used dm_control suite, and obtain strong performance on the challenging dog tasks, competitive with model-based approaches. Our results question, in parts, the prior explanation for sub-optimal learning due to overfitting early data.
Read more7/16/2024