Target Networks and Over-parameterization Stabilize Off-policy Bootstrapping with Function Approximation
2405.21043
0
0
Abstract
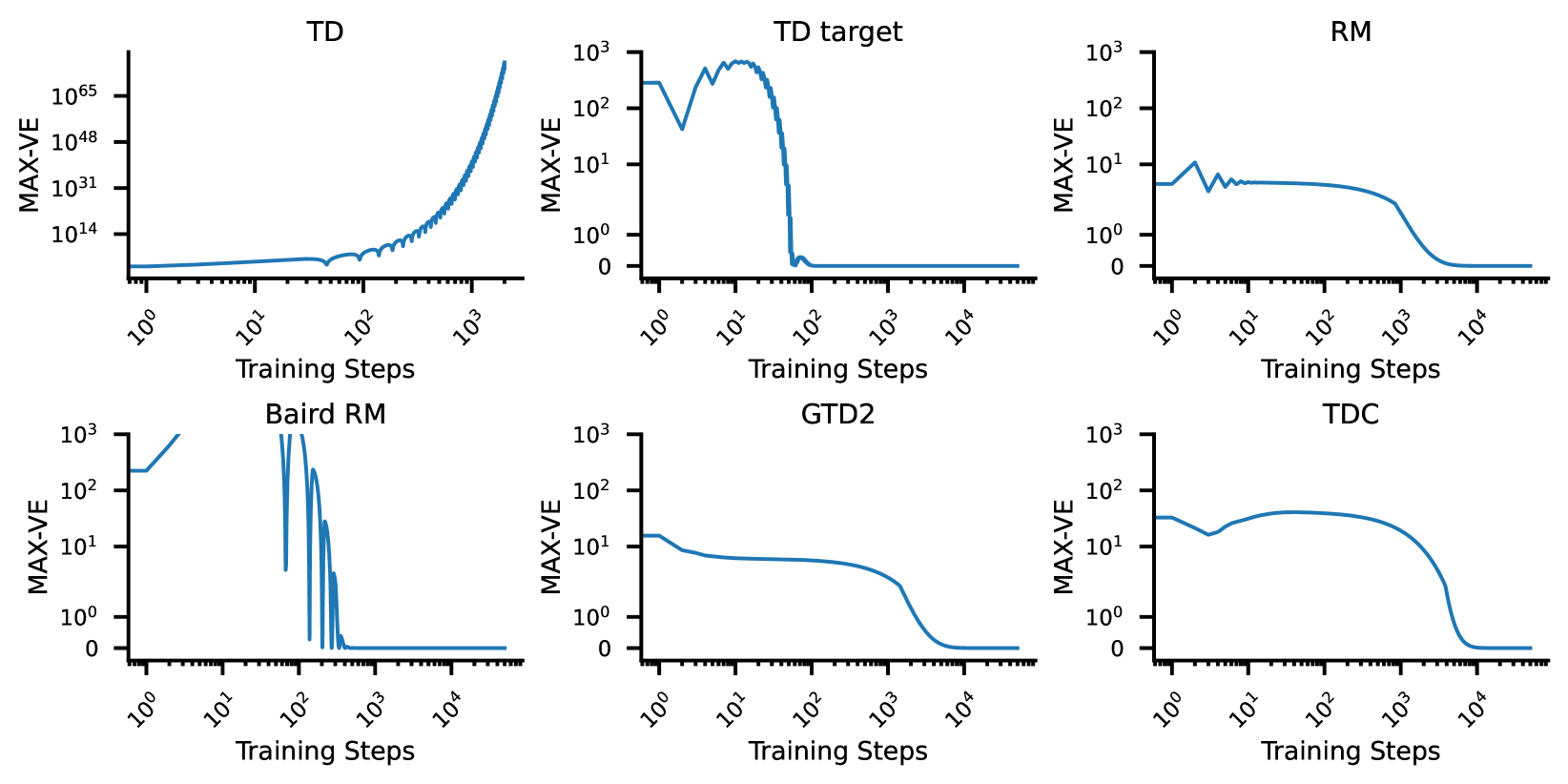
We prove that the combination of a target network and over-parameterized linear function approximation establishes a weaker convergence condition for bootstrapped value estimation in certain cases, even with off-policy data. Our condition is naturally satisfied for expected updates over the entire state-action space or learning with a batch of complete trajectories from episodic Markov decision processes. Notably, using only a target network or an over-parameterized model does not provide such a convergence guarantee. Additionally, we extend our results to learning with truncated trajectories, showing that convergence is achievable for all tasks with minor modifications, akin to value truncation for the final states in trajectories. Our primary result focuses on temporal difference estimation for prediction, providing high-probability value estimation error bounds and empirical analysis on Baird's counterexample and a Four-room task. Furthermore, we explore the control setting, demonstrating that similar convergence conditions apply to Q-learning.
Create account to get full access
Overview
- This paper explores how target networks and over-parameterization can stabilize off-policy reinforcement learning with function approximation.
- The authors analyze the convergence and sample complexity of off-policy multi-step temporal difference (TD) learning algorithms, such as Q-learning and actor-critic methods.
- They show that target networks and over-parameterization can mitigate the instability issues that arise in off-policy learning with function approximation.
Plain English Explanation
Reinforcement learning is a powerful technique for training AI systems to learn how to perform tasks by interacting with an environment and receiving rewards. In many real-world applications, the agent needs to learn based on data collected from a different policy (off-policy learning), which can lead to instability issues.
The paper discusses two techniques that can help stabilize off-policy learning with function approximation, which is common in complex environments where the agent's knowledge needs to be represented compactly.
Target networks are a way of separating the network used for predicting the target values from the network being trained, which can help break the feedback loop that can cause instability. Over-parameterization means using a more complex model with more parameters than necessary, which can also contribute to stability by providing more flexibility for the model to learn.
The authors provide theoretical analysis showing how these techniques can improve the convergence and sample complexity of off-policy reinforcement learning algorithms, such as Q-learning and actor-critic methods. This is an important result, as off-policy learning is crucial for many real-world applications where the agent needs to learn from data collected by a different policy.
Technical Explanation
The paper analyzes the convergence and sample complexity of off-policy multi-step temporal difference (TD) learning algorithms, such as Q-learning and actor-critic methods, when using function approximation. The authors show that target networks and over-parameterization can help mitigate the instability issues that arise in this setting.
Specifically, the authors derive high-probability bounds on the sample complexity required for Q-learning and actor-critic methods to converge to a near-optimal solution. They show that using target networks and over-parameterization can improve these bounds, making the algorithms more sample-efficient.
The intuition is that target networks help break the feedback loop that can cause instability in off-policy learning, while over-parameterization provides more flexibility for the function approximator to learn the true value function. The authors connect these findings to recent results on Bayesian inference in over-parameterized models and the effectiveness of gradient descent in training neural networks.
Critical Analysis
The paper provides a thorough theoretical analysis of the convergence and sample complexity of off-policy TD learning algorithms with function approximation. The authors' use of target networks and over-parameterization to stabilize these algorithms is a promising approach, and their analysis helps explain why these techniques can be effective.
However, the paper does not address some potential limitations and areas for further research. For example, the theoretical analysis assumes certain simplifying assumptions, such as linear function approximation and tabular environments, which may not hold in more complex, real-world settings. It would be valuable to see empirical evaluations of these techniques in more challenging environments.
Additionally, the paper does not discuss the computational and memory overhead associated with using target networks and over-parameterized models, which could be an important consideration in practical applications. Further research is needed to understand the trade-offs between the stability benefits and the increased computational requirements.
Overall, this paper makes an important contribution to the theoretical understanding of off-policy reinforcement learning with function approximation. The insights and techniques presented here could inform the design of more robust and sample-efficient reinforcement learning algorithms for real-world applications.
Conclusion
This paper demonstrates how target networks and over-parameterization can help stabilize off-policy reinforcement learning with function approximation. The authors provide theoretical analysis showing that these techniques can improve the convergence and sample complexity of algorithms like Q-learning and actor-critic methods.
These findings are significant because off-policy learning is crucial for many real-world applications, where an agent needs to learn from data collected by a different policy. The stability issues that can arise in this setting have been a major challenge, and the techniques presented in this paper offer a promising way to address them.
While the paper makes important theoretical contributions, further research is needed to understand the practical implications and trade-offs of these techniques, especially in more complex environments. Nevertheless, this work advances our understanding of how to build robust and efficient reinforcement learning systems, which could have far-reaching impacts across a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning the Target Network in Function Space
Kavosh Asadi, Yao Liu, Shoham Sabach, Ming Yin, Rasool Fakoor
0
0
We focus on the task of learning the value function in the reinforcement learning (RL) setting. This task is often solved by updating a pair of online and target networks while ensuring that the parameters of these two networks are equivalent. We propose Lookahead-Replicate (LR), a new value-function approximation algorithm that is agnostic to this parameter-space equivalence. Instead, the LR algorithm is designed to maintain an equivalence between the two networks in the function space. This value-based equivalence is obtained by employing a new target-network update. We show that LR leads to a convergent behavior in learning the value function. We also present empirical results demonstrating that LR-based target-network updates significantly improve deep RL on the Atari benchmark.
6/5/2024
🌐
Analysis of Off-Policy Multi-Step TD-Learning with Linear Function Approximation
Donghwan Lee
0
0
This paper analyzes multi-step TD-learning algorithms within the `deadly triad' scenario, characterized by linear function approximation, off-policy learning, and bootstrapping. In particular, we prove that n-step TD-learning algorithms converge to a solution as the sampling horizon n increases sufficiently. The paper is divided into two parts. In the first part, we comprehensively examine the fundamental properties of their model-based deterministic counterparts, including projected value iteration, gradient descent algorithms, and the control theoretic approach, which can be viewed as prototype deterministic algorithms whose analysis plays a pivotal role in understanding and developing their model-free reinforcement learning counterparts. In particular, we prove that these algorithms converge to meaningful solutions when n is sufficiently large. Based on these findings, two n-step TD-learning algorithms are proposed and analyzed, which can be seen as the model-free reinforcement learning counterparts of the gradient and control theoretic algorithms.
4/9/2024
Linear Function Approximation as a Computationally Efficient Method to Solve Classical Reinforcement Learning Challenges
Hari Srikanth
0
0
Neural Network based approximations of the Value function make up the core of leading Policy Based methods such as Trust Regional Policy Optimization (TRPO) and Proximal Policy Optimization (PPO). While this adds significant value when dealing with very complex environments, we note that in sufficiently low State and action space environments, a computationally expensive Neural Network architecture offers marginal improvement over simpler Value approximation methods. We present an implementation of Natural Actor Critic algorithms with actor updates through Natural Policy Gradient methods. This paper proposes that Natural Policy Gradient (NPG) methods with Linear Function Approximation as a paradigm for value approximation may surpass the performance and speed of Neural Network based models such as TRPO and PPO within these environments. Over Reinforcement Learning benchmarks Cart Pole and Acrobot, we observe that our algorithm trains much faster than complex neural network architectures, and obtains an equivalent or greater result. This allows us to recommend the use of NPG methods with Linear Function Approximation over TRPO and PPO for both traditional and sparse reward low dimensional problems.
6/3/2024
📶
High-probability sample complexities for policy evaluation with linear function approximation
Gen Li, Weichen Wu, Yuejie Chi, Cong Ma, Alessandro Rinaldo, Yuting Wei
0
0
This paper is concerned with the problem of policy evaluation with linear function approximation in discounted infinite horizon Markov decision processes. We investigate the sample complexities required to guarantee a predefined estimation error of the best linear coefficients for two widely-used policy evaluation algorithms: the temporal difference (TD) learning algorithm and the two-timescale linear TD with gradient correction (TDC) algorithm. In both the on-policy setting, where observations are generated from the target policy, and the off-policy setting, where samples are drawn from a behavior policy potentially different from the target policy, we establish the first sample complexity bound with high-probability convergence guarantee that attains the optimal dependence on the tolerance level. We also exhihit an explicit dependence on problem-related quantities, and show in the on-policy setting that our upper bound matches the minimax lower bound on crucial problem parameters, including the choice of the feature maps and the problem dimension.
5/3/2024