Learning to Edit: Aligning LLMs with Knowledge Editing
2402.11905
0
0
🔄
Abstract
Knowledge editing techniques, aiming to efficiently modify a minor proportion of knowledge in large language models (LLMs) without negatively impacting performance across other inputs, have garnered widespread attention. However, existing methods predominantly rely on memorizing the updated knowledge, impeding LLMs from effectively combining the new knowledge with their inherent knowledge when answering questions. To this end, we propose a Learning to Edit (LTE) framework, focusing on teaching LLMs to apply updated knowledge into input questions, inspired by the philosophy of Teach a man to fish. LTE features a two-phase process: (i) the Alignment Phase, which fine-tunes LLMs on a meticulously curated parallel dataset to make reliable, in-scope edits while preserving out-of-scope information and linguistic proficiency; and (ii) the Inference Phase, which employs a retrieval-based mechanism for real-time and mass knowledge editing. By comparing our approach with seven advanced baselines across four popular knowledge editing benchmarks and two LLM architectures, we demonstrate LTE's superiority in knowledge editing performance, robustness in both batch and sequential editing, minimal interference on general tasks, and rapid editing speeds. The data and code are available at https://github.com/YJiangcm/LTE.
Create account to get full access
Overview
- This paper proposes a new framework called Learning to Edit (LTE) for efficiently modifying a small portion of knowledge in large language models (LLMs) without negatively impacting their overall performance.
- Existing methods for knowledge editing in LLMs tend to simply memorize the updated knowledge, which limits the models' ability to effectively combine the new knowledge with their inherent knowledge when answering questions.
- LTE aims to teach LLMs to apply the updated knowledge directly into the input questions, inspired by the philosophy of "teach a man to fish."
Plain English Explanation
Large language models (LLMs) like GPT-3 have a vast amount of knowledge, but sometimes that knowledge needs to be updated or corrected. Existing methods for editing the knowledge in LLMs often just memorize the new information, which can make it hard for the models to use that knowledge effectively when answering questions.
The researchers behind this paper wanted to find a better way to update the knowledge in LLMs. Their idea, inspired by the saying "teach a man to fish," was to create a framework that would teach the LLMs to apply the new knowledge directly into the questions they're asked, rather than just memorizing it.
This framework, called Learning to Edit (LTE), has two main steps:
- Alignment Phase: The researchers fine-tune the LLM on a carefully curated dataset to help it make reliable, relevant edits to the knowledge, while still preserving the model's broader understanding and linguistic skills.
- Inference Phase: The model then uses a retrieval-based mechanism to quickly and efficiently apply the updated knowledge when answering questions in real-time.
By testing LTE against other state-of-the-art knowledge editing methods, the researchers showed that their approach outperforms the competition in terms of knowledge editing performance, robustness to both batch and sequential editing, minimal interference on general tasks, and fast editing speeds.
Technical Explanation
The proposed LTE framework consists of two key phases:
-
Alignment Phase: In this phase, the LLM is fine-tuned on a carefully curated parallel dataset to learn how to make reliable, in-scope edits to its knowledge while preserving its broader understanding and linguistic proficiency. This ensures the model can apply the updated knowledge effectively when answering questions, rather than simply memorizing it.
-
Inference Phase: During this phase, LTE employs a retrieval-based mechanism to quickly and efficiently apply the updated knowledge in real-time. This allows for rapid, mass knowledge editing without negatively impacting the model's performance on general tasks.
The researchers evaluated LTE against seven advanced baseline methods across four popular knowledge editing benchmarks and two LLM architectures (GPT-2 and GPT-3). Their results demonstrate the superiority of the LTE framework in terms of knowledge editing performance, robustness to both batch and sequential editing, minimal interference on general tasks, and rapid editing speeds.
Critical Analysis
The paper provides a compelling and well-designed solution to the challenge of efficiently modifying knowledge in large language models without compromising their overall performance. The researchers have thoughtfully addressed the limitations of existing knowledge editing approaches, which tend to focus on memorization rather than the effective application of updated knowledge.
One potential area for further research could be exploring the scalability and generalization of the LTE framework. While the results are promising, it would be valuable to understand how LTE performs on larger, more diverse datasets and a wider range of LLM architectures. Additionally, the paper does not delve into the computational or memory requirements of the framework, which could be an important consideration for real-world deployment.
Another aspect that could be investigated is the interpretability and transparency of the LTE system. Understanding how the model selects and applies the updated knowledge could provide valuable insights and build trust in the technology. Approaches like InstructEdit that focus on instruction-based editing may offer relevant lessons in this area.
Overall, the LTE framework represents an important step forward in the field of knowledge editing for large language models. By shifting the focus to teaching LLMs how to effectively apply new knowledge, rather than simply memorizing it, the researchers have opened up new avenues for enhancing the capabilities and robustness of these powerful AI systems.
Conclusion
The Learning to Edit (LTE) framework proposed in this paper offers a novel approach to efficiently modifying the knowledge in large language models without compromising their overall performance. By fine-tuning the models to directly apply updated knowledge into input questions, rather than just memorizing it, LTE demonstrates superior results in terms of knowledge editing, robustness, and speed compared to existing methods.
This research highlights the importance of rethinking traditional knowledge editing techniques and exploring new ways to seamlessly integrate updated information into the powerful, yet complex, LLMs that are increasingly shaping our digital landscape. As the field of AI continues to evolve, frameworks like LTE will be crucial for ensuring these models can adapt and grow their knowledge in a reliable and efficient manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models
Peng Wang, Ningyu Zhang, Bozhong Tian, Zekun Xi, Yunzhi Yao, Ziwen Xu, Mengru Wang, Shengyu Mao, Xiaohan Wang, Siyuan Cheng, Kangwei Liu, Yuansheng Ni, Guozhou Zheng, Huajun Chen
0
0
Large Language Models (LLMs) usually suffer from knowledge cutoff or fallacy issues, which means they are unaware of unseen events or generate text with incorrect facts owing to outdated/noisy data. To this end, many knowledge editing approaches for LLMs have emerged -- aiming to subtly inject/edit updated knowledge or adjust undesired behavior while minimizing the impact on unrelated inputs. Nevertheless, due to significant differences among various knowledge editing methods and the variations in task setups, there is no standard implementation framework available for the community, which hinders practitioners from applying knowledge editing to applications. To address these issues, we propose EasyEdit, an easy-to-use knowledge editing framework for LLMs. It supports various cutting-edge knowledge editing approaches and can be readily applied to many well-known LLMs such as T5, GPT-J, LlaMA, etc. Empirically, we report the knowledge editing results on LlaMA-2 with EasyEdit, demonstrating that knowledge editing surpasses traditional fine-tuning in terms of reliability and generalization. We have released the source code on GitHub, along with Google Colab tutorials and comprehensive documentation for beginners to get started. Besides, we present an online system for real-time knowledge editing, and a demo video.
6/26/2024

Time Sensitive Knowledge Editing through Efficient Finetuning
Xiou Ge, Ali Mousavi, Edouard Grave, Armand Joulin, Kun Qian, Benjamin Han, Mostafa Arefiyan, Yunyao Li
0
0
Large Language Models (LLMs) have demonstrated impressive capability in different tasks and are bringing transformative changes to many domains. However, keeping the knowledge in LLMs up-to-date remains a challenge once pretraining is complete. It is thus essential to design effective methods to both update obsolete knowledge and induce new knowledge into LLMs. Existing locate-and-edit knowledge editing (KE) method suffers from two limitations. First, the post-edit LLMs by such methods generally have poor capability in answering complex queries that require multi-hop reasoning. Second, the long run-time of such locate-and-edit methods to perform knowledge edits make it infeasible for large scale KE in practice. In this paper, we explore Parameter-Efficient Fine-Tuning (PEFT) techniques as an alternative for KE. We curate a more comprehensive temporal KE dataset with both knowledge update and knowledge injection examples for KE performance benchmarking. We further probe the effect of fine-tuning on a range of layers in an LLM for the multi-hop QA task. We find that PEFT performs better than locate-and-edit techniques for time-sensitive knowledge edits.
6/10/2024
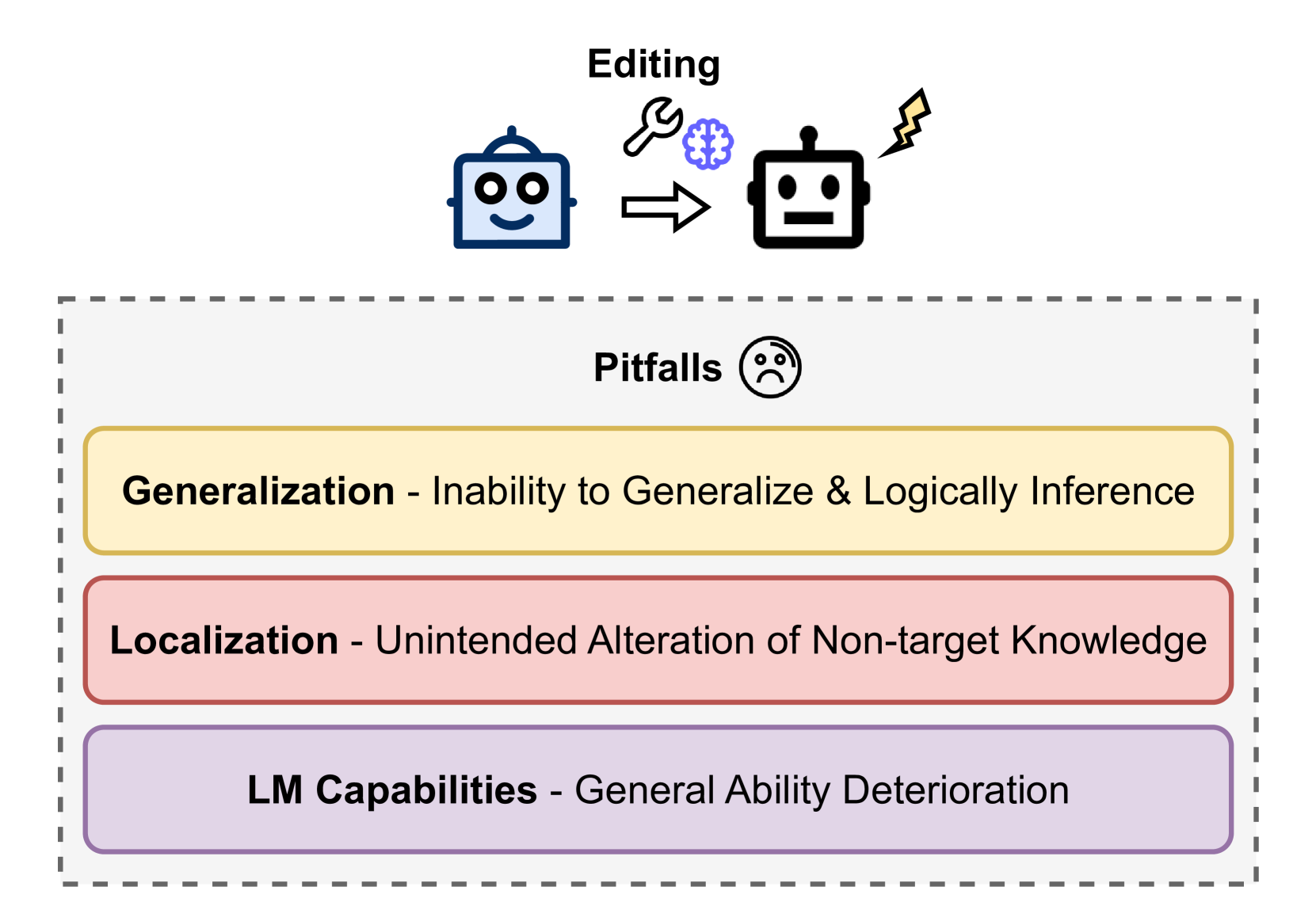
Editing the Mind of Giants: An In-Depth Exploration of Pitfalls of Knowledge Editing in Large Language Models
Cheng-Hsun Hsueh, Paul Kuo-Ming Huang, Tzu-Han Lin, Che-Wei Liao, Hung-Chieh Fang, Chao-Wei Huang, Yun-Nung Chen
0
0
Knowledge editing is a rising technique for efficiently updating factual knowledge in Large Language Models (LLMs) with minimal alteration of parameters. However, recent studies have identified concerning side effects, such as knowledge distortion and the deterioration of general abilities, that have emerged after editing. This survey presents a comprehensive study of these side effects, providing a unified view of the challenges associated with knowledge editing in LLMs. We discuss related works and summarize potential research directions to overcome these limitations. Our work highlights the limitations of current knowledge editing methods, emphasizing the need for deeper understanding of inner knowledge structures of LLMs and improved knowledge editing methods. To foster future research, we have released the complementary materials such as paper collection publicly at https://github.com/MiuLab/EditLLM-Survey
6/4/2024
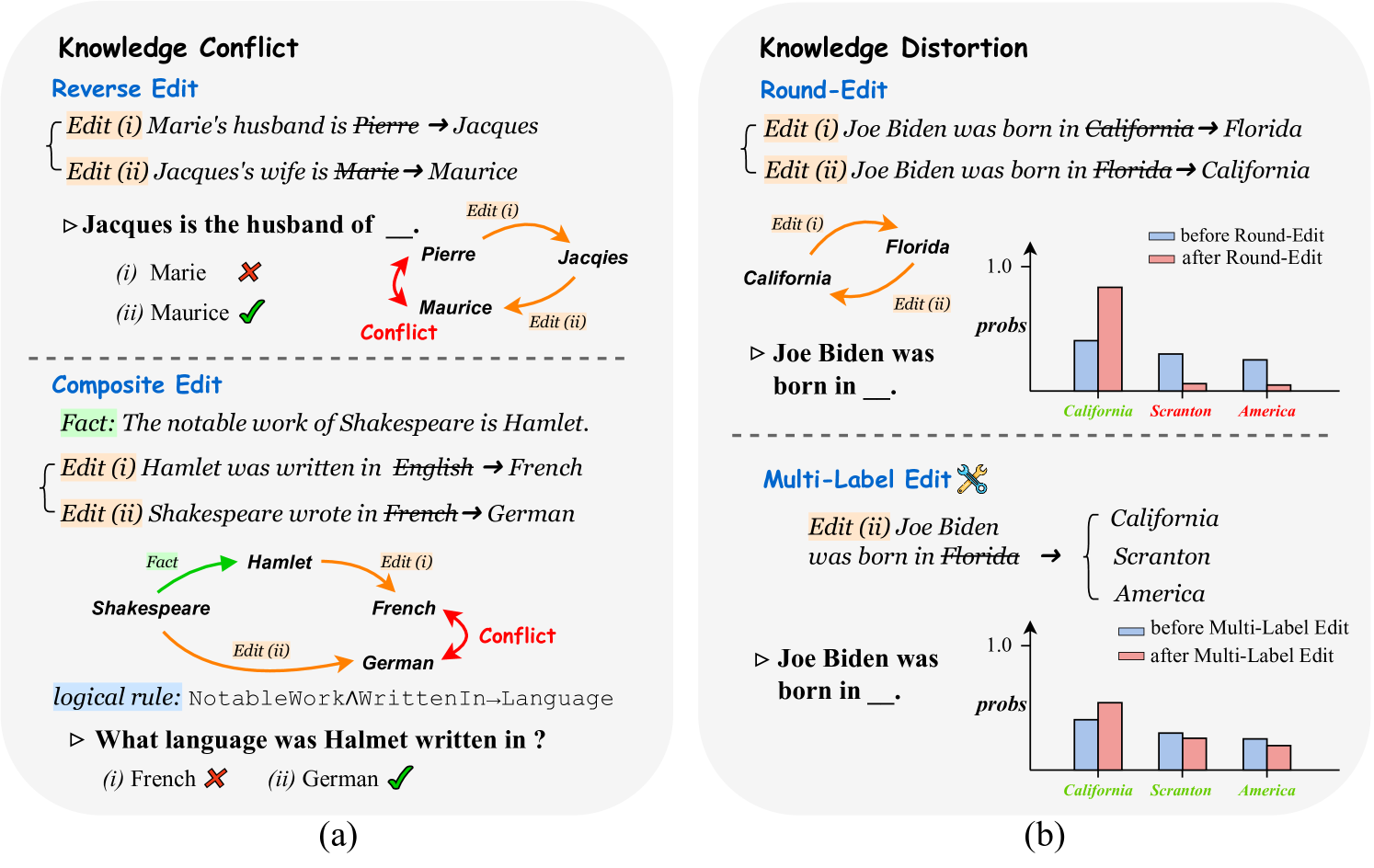
Unveiling the Pitfalls of Knowledge Editing for Large Language Models
Zhoubo Li, Ningyu Zhang, Yunzhi Yao, Mengru Wang, Xi Chen, Huajun Chen
0
0
As the cost associated with fine-tuning Large Language Models (LLMs) continues to rise, recent research efforts have pivoted towards developing methodologies to edit implicit knowledge embedded within LLMs. Yet, there's still a dark cloud lingering overhead -- will knowledge editing trigger butterfly effect? since it is still unclear whether knowledge editing might introduce side effects that pose potential risks or not. This paper pioneers the investigation into the potential pitfalls associated with knowledge editing for LLMs. To achieve this, we introduce new benchmark datasets and propose innovative evaluation metrics. Our results underline two pivotal concerns: (1) Knowledge Conflict: Editing groups of facts that logically clash can magnify the inherent inconsistencies in LLMs-a facet neglected by previous methods. (2) Knowledge Distortion: Altering parameters with the aim of editing factual knowledge can irrevocably warp the innate knowledge structure of LLMs. Experimental results vividly demonstrate that knowledge editing might inadvertently cast a shadow of unintended consequences on LLMs, which warrant attention and efforts for future works. Code and data are available at https://github.com/zjunlp/PitfallsKnowledgeEditing.
5/14/2024