Unveiling the Pitfalls of Knowledge Editing for Large Language Models
2310.02129
0
0
Abstract
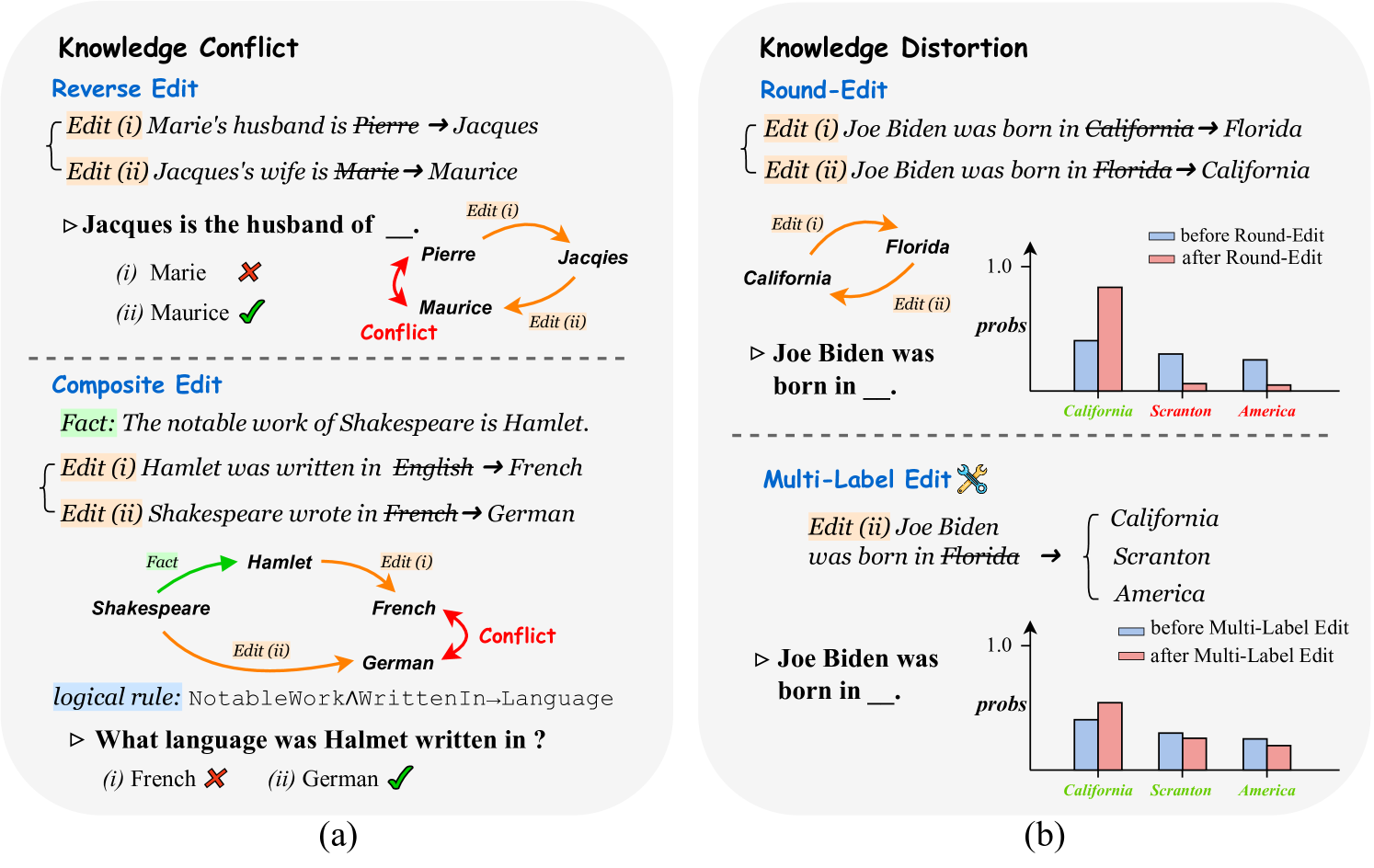
As the cost associated with fine-tuning Large Language Models (LLMs) continues to rise, recent research efforts have pivoted towards developing methodologies to edit implicit knowledge embedded within LLMs. Yet, there's still a dark cloud lingering overhead -- will knowledge editing trigger butterfly effect? since it is still unclear whether knowledge editing might introduce side effects that pose potential risks or not. This paper pioneers the investigation into the potential pitfalls associated with knowledge editing for LLMs. To achieve this, we introduce new benchmark datasets and propose innovative evaluation metrics. Our results underline two pivotal concerns: (1) Knowledge Conflict: Editing groups of facts that logically clash can magnify the inherent inconsistencies in LLMs-a facet neglected by previous methods. (2) Knowledge Distortion: Altering parameters with the aim of editing factual knowledge can irrevocably warp the innate knowledge structure of LLMs. Experimental results vividly demonstrate that knowledge editing might inadvertently cast a shadow of unintended consequences on LLMs, which warrant attention and efforts for future works. Code and data are available at https://github.com/zjunlp/PitfallsKnowledgeEditing.
Create account to get full access
Overview
- Examines the challenges and pitfalls of editing the knowledge in large language models (LLMs)
- Highlights the difficulties in controlling and modifying the information and behaviors of these complex AI systems
- Discusses the potential risks and unintended consequences that can arise from knowledge editing efforts
Plain English Explanation
Large language models (LLMs) like GPT-3 and InstructEdit have become incredibly powerful and versatile AI systems, capable of generating human-like text, answering questions, and even completing complex tasks. However, these models are essentially "black boxes" - their inner workings and the knowledge they've absorbed from their training data are not fully understood or controllable.
Attempts to edit or "detoxify" the knowledge in these LLMs, as explored in studies like MLake and Detoxifying Large Language Models, have revealed significant challenges. Modifying the knowledge base of an LLM can lead to unintended consequences, such as introducing new biases, inconsistencies, or even completely breaking the model's capabilities.
Furthermore, as shown in Detecting Edited Knowledge in Language Models, it can be difficult to reliably detect when an LLM's knowledge has been edited, raising concerns about the transparency and trustworthiness of these systems.
Technical Explanation
The paper explores the inherent difficulties in editing the knowledge embedded within large language models (LLMs). These models are trained on massive amounts of data, absorbing a vast and complex web of information, relationships, and behaviors. Attempting to selectively modify or "detoxify" this knowledge can be an extremely challenging task.
The authors examine several key pitfalls of knowledge editing for LLMs:
-
Fragility and Unpredictability: Modifying the parameters or knowledge base of an LLM can lead to unintended and unpredictable changes in the model's behavior, potentially breaking its capabilities or introducing new biases and inconsistencies.
-
Lack of Transparency: Due to the opaque nature of LLMs, it can be difficult to reliably detect when a model's knowledge has been edited, as shown in the Detecting Edited Knowledge in Language Models study. This raises concerns about the trustworthiness and interpretability of these systems.
-
Scalability Challenges: Scaling knowledge editing efforts to large, complex LLMs is an immense technical challenge, as the models' knowledge bases are vast and interconnected, making targeted modifications extremely difficult.
The paper also discusses the potential risks and societal implications of knowledge editing, such as the possibility of malicious actors exploiting these techniques to spread disinformation or manipulate the behavior of LLMs.
Critical Analysis
The paper provides a valuable and thought-provoking examination of the challenges inherent in editing the knowledge embedded within large language models. The authors clearly highlight the fragility and unpredictability of these complex systems, as well as the lack of transparency that makes it difficult to reliably detect and verify knowledge edits.
However, the paper could have delved deeper into the potential consequences and risks of knowledge editing, particularly with regard to issues of fairness, bias, and societal impact. While the authors briefly mention the possibility of malicious actors exploiting these techniques, a more extensive discussion of these concerns would have strengthened the analysis.
Additionally, the paper could have explored potential avenues for addressing these challenges, such as the development of more transparent and interpretable LLM architectures, or the use of novel techniques like prompt engineering to indirectly influence model behavior.
Overall, the paper provides a valuable contribution to the ongoing discussion around the responsible development and deployment of large language models, and the need for greater understanding and control of their inner workings.
Conclusion
This paper sheds light on the significant challenges and pitfalls inherent in editing the knowledge embedded within large language models (LLMs). It highlights the fragility and unpredictability of these complex systems, as well as the lack of transparency that makes it difficult to reliably detect and verify knowledge edits.
The insights provided in this paper are crucial as researchers and developers continue to push the boundaries of language AI, and grapple with the ethical and societal implications of these powerful technologies. Addressing the issues raised in this paper will be essential for ensuring that LLMs can be developed and deployed in a responsible and trustworthy manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Editing the Mind of Giants: An In-Depth Exploration of Pitfalls of Knowledge Editing in Large Language Models
Cheng-Hsun Hsueh, Paul Kuo-Ming Huang, Tzu-Han Lin, Che-Wei Liao, Hung-Chieh Fang, Chao-Wei Huang, Yun-Nung Chen
0
0
Knowledge editing is a rising technique for efficiently updating factual knowledge in Large Language Models (LLMs) with minimal alteration of parameters. However, recent studies have identified concerning side effects, such as knowledge distortion and the deterioration of general abilities, that have emerged after editing. This survey presents a comprehensive study of these side effects, providing a unified view of the challenges associated with knowledge editing in LLMs. We discuss related works and summarize potential research directions to overcome these limitations. Our work highlights the limitations of current knowledge editing methods, emphasizing the need for deeper understanding of inner knowledge structures of LLMs and improved knowledge editing methods. To foster future research, we have released the complementary materials such as paper collection publicly at https://github.com/MiuLab/EditLLM-Survey
6/4/2024
📈
The Butterfly Effect of Model Editing: Few Edits Can Trigger Large Language Models Collapse
Wanli Yang, Fei Sun, Xinyu Ma, Xun Liu, Dawei Yin, Xueqi Cheng
0
0
Although model editing has shown promise in revising knowledge in Large Language Models (LLMs), its impact on the inherent capabilities of LLMs is often overlooked. In this work, we reveal a critical phenomenon: even a single edit can trigger model collapse, manifesting as significant performance degradation in various benchmark tasks. However, benchmarking LLMs after each edit, while necessary to prevent such collapses, is impractically time-consuming and resource-intensive. To mitigate this, we propose using perplexity as a surrogate metric, validated by extensive experiments demonstrating changes in an edited model's perplexity are strongly correlated with its downstream task performances. We further conduct an in-depth study on sequential editing, a practical setting for real-world scenarios, across various editing methods and LLMs, focusing on hard cases from our previous single edit studies. The results indicate that nearly all examined editing methods result in model collapse after only few edits. To facilitate further research, we have utilized GPT-3.5 to develop a new dataset, HardEdit, based on those hard cases. This dataset aims to establish the foundation for pioneering research in reliable model editing and the mechanisms underlying editing-induced model collapse. We hope this work can draw the community's attention to the potential risks inherent in model editing practices.
6/6/2024
💬
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models
Peng Wang, Ningyu Zhang, Bozhong Tian, Zekun Xi, Yunzhi Yao, Ziwen Xu, Mengru Wang, Shengyu Mao, Xiaohan Wang, Siyuan Cheng, Kangwei Liu, Yuansheng Ni, Guozhou Zheng, Huajun Chen
0
0
Large Language Models (LLMs) usually suffer from knowledge cutoff or fallacy issues, which means they are unaware of unseen events or generate text with incorrect facts owing to outdated/noisy data. To this end, many knowledge editing approaches for LLMs have emerged -- aiming to subtly inject/edit updated knowledge or adjust undesired behavior while minimizing the impact on unrelated inputs. Nevertheless, due to significant differences among various knowledge editing methods and the variations in task setups, there is no standard implementation framework available for the community, which hinders practitioners from applying knowledge editing to applications. To address these issues, we propose EasyEdit, an easy-to-use knowledge editing framework for LLMs. It supports various cutting-edge knowledge editing approaches and can be readily applied to many well-known LLMs such as T5, GPT-J, LlaMA, etc. Empirically, we report the knowledge editing results on LlaMA-2 with EasyEdit, demonstrating that knowledge editing surpasses traditional fine-tuning in terms of reliability and generalization. We have released the source code on GitHub, along with Google Colab tutorials and comprehensive documentation for beginners to get started. Besides, we present an online system for real-time knowledge editing, and a demo video.
6/26/2024
💬
Cross-Lingual Knowledge Editing in Large Language Models
Jiaan Wang, Yunlong Liang, Zengkui Sun, Yuxuan Cao, Jiarong Xu, Fandong Meng
0
0
Knowledge editing aims to change language models' performance on several special cases (i.e., editing scope) by infusing the corresponding expected knowledge into them. With the recent advancements in large language models (LLMs), knowledge editing has been shown as a promising technique to adapt LLMs to new knowledge without retraining from scratch. However, most of the previous studies neglect the multi-lingual nature of some main-stream LLMs (e.g., LLaMA, ChatGPT and GPT-4), and typically focus on monolingual scenarios, where LLMs are edited and evaluated in the same language. As a result, it is still unknown the effect of source language editing on a different target language. In this paper, we aim to figure out this cross-lingual effect in knowledge editing. Specifically, we first collect a large-scale cross-lingual synthetic dataset by translating ZsRE from English to Chinese. Then, we conduct English editing on various knowledge editing methods covering different paradigms, and evaluate their performance in Chinese, and vice versa. To give deeper analyses of the cross-lingual effect, the evaluation includes four aspects, i.e., reliability, generality, locality and portability. Furthermore, we analyze the inconsistent behaviors of the edited models and discuss their specific challenges. Data and codes are available at https://github.com/krystalan/Bi_ZsRE
5/31/2024