Learning to Learn for Few-shot Continual Active Learning
2311.03732
0
0
🚀
Abstract
Continual learning strives to ensure stability in solving previously seen tasks while demonstrating plasticity in a novel domain. Recent advances in continual learning are mostly confined to a supervised learning setting, especially in NLP domain. In this work, we consider a few-shot continual active learning setting where labeled data are inadequate, and unlabeled data are abundant but with a limited annotation budget. We exploit meta-learning and propose a method, called Meta-Continual Active Learning. This method sequentially queries the most informative examples from a pool of unlabeled data for annotation to enhance task-specific performance and tackle continual learning problems through meta-objective. Specifically, we employ meta-learning and experience replay to address inter-task confusion and catastrophic forgetting. We further incorporate textual augmentations to avoid memory over-fitting caused by experience replay and sample queries, thereby ensuring generalization. We conduct extensive experiments on benchmark text classification datasets from diverse domains to validate the feasibility and effectiveness of meta-continual active learning. We also analyze the impact of different active learning strategies on various meta continual learning models. The experimental results demonstrate that introducing randomness into sample selection is the best default strategy for maintaining generalization in meta-continual learning framework.
Create account to get full access
Overview
- Continual learning (CL) aims to help AI systems learn new tasks without forgetting previous ones
- Recent CL research has focused on supervised learning, especially in natural language processing (NLP)
- This paper explores a few-shot continual active learning (CAL) setting, where labeled data is scarce but unlabeled data is abundant
Plain English Explanation
Continual learning is an important goal in AI, as it allows systems to continuously expand their knowledge and capabilities without forgetting what they've learned before. Recent advances in continual learning have mostly been in the context of supervised learning, particularly in the field of natural language processing.
This paper explores a more challenging setting called few-shot continual active learning (CAL). In this scenario, the system has access to plenty of unlabeled data, but only a limited budget to get those data points labeled. The goal is to select the most informative examples to label, in order to maximize performance on both new and previously seen tasks.
To address this, the researchers propose a method called Meta-Continual Active Learning. This approach uses meta-learning and experience replay to help the system learn new tasks while avoiding forgetting old ones. It also incorporates text augmentation techniques to improve generalization.
The key idea is to intelligently select which unlabeled examples to get labeled, in order to enhance the system's performance on both new and old tasks, despite the limited annotation budget. This can be thought of as an efficient way to "fill in the gaps" in the system's knowledge.
Technical Explanation
The researchers propose a method called Meta-Continual Active Learning (MCAL) to address the few-shot CAL setting. MCAL sequentially selects the most informative examples from a pool of unlabeled data and requests labels for them, in order to enhance the model's performance.
Specifically, MCAL employs two key techniques:
-
Meta-learning: This allows the model to quickly adapt to new tasks by learning a good initialization point and update strategy from previous experience.
-
Experience replay: The model stores a subset of past data and revisits it during training, helping to mitigate catastrophic forgetting of old tasks.
Additionally, the researchers incorporate textual data augmentation techniques to improve the model's ability to generalize.
The researchers conduct extensive experiments on benchmark text classification datasets to evaluate the effectiveness of MCAL. They analyze different active learning strategies, such as random sampling and memory-based sample selection, in the few-shot CAL setting.
Critical Analysis
The paper makes a valuable contribution by exploring the challenging few-shot continual active learning setting, which has real-world relevance but has received less attention than other CL scenarios. The use of meta-learning and experience replay to address inter-task confusion and catastrophic forgetting is a sensible approach.
However, the paper does not address some potential limitations of the proposed method. For example, the reliance on textual augmentation techniques may not be as effective for other data modalities, such as images or audio. Additionally, the experiments are limited to text classification tasks, and it's unclear how well the method would generalize to more complex NLP problems or other domains.
Further research could explore the performance of MCAL in more diverse settings, such as continual learning in the presence of repetition, or investigate ways to make the active learning strategy more sophisticated and adaptive to the specific task and data characteristics.
Conclusion
This paper presents a novel approach called Meta-Continual Active Learning (MCAL) to address the few-shot continual active learning setting in natural language processing. By leveraging meta-learning and experience replay, MCAL can effectively select informative examples to label and learn new tasks while mitigating forgetting of old ones.
The experimental results demonstrate the effectiveness of MCAL, particularly in highlighting the importance of simple random sampling as a robust active learning strategy in the few-shot CAL scenario. This work provides a valuable foundation for further research into continual learning methods that can operate efficiently with limited labeled data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
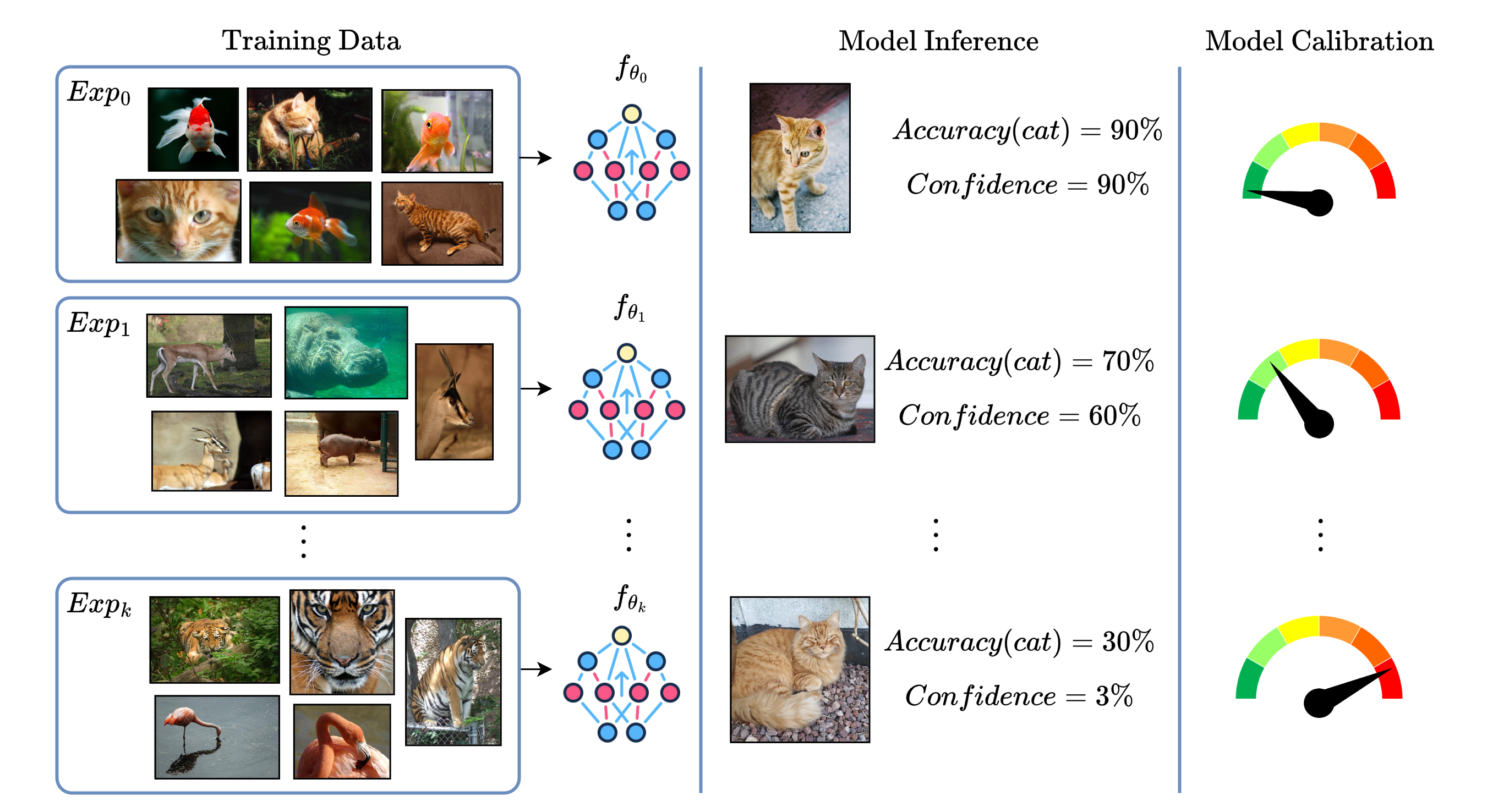
Calibration of Continual Learning Models
Lanpei Li, Elia Piccoli, Andrea Cossu, Davide Bacciu, Vincenzo Lomonaco
0
0
Continual Learning (CL) focuses on maximizing the predictive performance of a model across a non-stationary stream of data. Unfortunately, CL models tend to forget previous knowledge, thus often underperforming when compared with an offline model trained jointly on the entire data stream. Given that any CL model will eventually make mistakes, it is of crucial importance to build calibrated CL models: models that can reliably tell their confidence when making a prediction. Model calibration is an active research topic in machine learning, yet to be properly investigated in CL. We provide the first empirical study of the behavior of calibration approaches in CL, showing that CL strategies do not inherently learn calibrated models. To mitigate this issue, we design a continual calibration approach that improves the performance of post-processing calibration methods over a wide range of different benchmarks and CL strategies. CL does not necessarily need perfect predictive models, but rather it can benefit from reliable predictive models. We believe our study on continual calibration represents a first step towards this direction.
4/15/2024

Adaptive Memory Replay for Continual Learning
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vyshnavi Gutta, Rogerio Feris, Zsolt Kira, Leonid Karlinsky
0
0
Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
4/22/2024
💬
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, Hao Wang
0
0
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
7/2/2024

Continual Learning in the Presence of Repetition
Hamed Hemati, Lorenzo Pellegrini, Xiaotian Duan, Zixuan Zhao, Fangfang Xia, Marc Masana, Benedikt Tscheschner, Eduardo Veas, Yuxiang Zheng, Shiji Zhao, Shao-Yuan Li, Sheng-Jun Huang, Vincenzo Lomonaco, Gido M. van de Ven
0
0
Continual learning (CL) provides a framework for training models in ever-evolving environments. Although re-occurrence of previously seen objects or tasks is common in real-world problems, the concept of repetition in the data stream is not often considered in standard benchmarks for CL. Unlike with the rehearsal mechanism in buffer-based strategies, where sample repetition is controlled by the strategy, repetition in the data stream naturally stems from the environment. This report provides a summary of the CLVision challenge at CVPR 2023, which focused on the topic of repetition in class-incremental learning. The report initially outlines the challenge objective and then describes three solutions proposed by finalist teams that aim to effectively exploit the repetition in the stream to learn continually. The experimental results from the challenge highlight the effectiveness of ensemble-based solutions that employ multiple versions of similar modules, each trained on different but overlapping subsets of classes. This report underscores the transformative potential of taking a different perspective in CL by employing repetition in the data stream to foster innovative strategy design.
5/8/2024