Learning to Stabilize Unknown LTI Systems on a Single Trajectory under Stochastic Noise
2406.00234
0
0

Abstract
We study the problem of learning to stabilize unknown noisy Linear Time-Invariant (LTI) systems on a single trajectory. It is well known in the literature that the learn-to-stabilize problem suffers from exponential blow-up in which the state norm blows up in the order of $Theta(2^n)$ where $n$ is the state space dimension. This blow-up is due to the open-loop instability when exploring the $n$-dimensional state space. To address this issue, we develop a novel algorithm that decouples the unstable subspace of the LTI system from the stable subspace, based on which the algorithm only explores and stabilizes the unstable subspace, the dimension of which can be much smaller than $n$. With a new singular-value-decomposition(SVD)-based analytical framework, we prove that the system is stabilized before the state norm reaches $2^{O(k log n)}$, where $k$ is the dimension of the unstable subspace. Critically, this bound avoids exponential blow-up in state dimension in the order of $Theta(2^n)$ as in the previous works, and to the best of our knowledge, this is the first paper to avoid exponential blow-up in dimension for stabilizing LTI systems with noise.
Create account to get full access
Overview
- This paper presents a novel approach to learning how to stabilize the behavior of unknown linear time-invariant (LTI) systems, even when the system is subject to stochastic noise.
- The authors develop a reinforcement learning-based method that can learn a stabilizing control policy from a single system trajectory, without any prior knowledge about the system dynamics.
- The proposed technique is demonstrated to be effective on a range of LTI systems, including those with unstable open-loop dynamics.
Plain English Explanation
The paper focuses on the challenge of controlling linear time-invariant (LTI) systems - systems whose behavior can be described by a set of linear equations that do not change over time. These systems are commonly used to model physical processes, but their behavior can be difficult to predict, especially when they are subject to random disturbances or "noise."
The authors present a new machine learning approach that can learn how to stabilize the behavior of an unknown LTI system, even in the presence of stochastic noise. Their key insight is that they can use reinforcement learning - a type of machine learning where an agent learns how to take actions that maximize a reward signal - to train a control policy that can stabilize the system.
Importantly, their method only requires observing a single trajectory of the system's behavior, rather than needing a detailed mathematical model of the system dynamics. This makes it much more practical to apply in real-world scenarios where the underlying system may not be fully known.
The authors demonstrate the effectiveness of their approach on a range of different LTI systems, including some with inherently unstable open-loop dynamics (meaning the system will naturally drift away from a desired state without any control intervention). By learning a stabilizing control policy, their method can keep these systems operating within a desired range, even in the face of random disturbances.
Technical Explanation
The paper proposes a reinforcement learning-based approach for learning to stabilize the behavior of unknown linear time-invariant (LTI) systems. The key innovation is that the method can learn an effective control policy from observing just a single trajectory of the system's behavior, without requiring any prior knowledge of the system dynamics.
The authors formulate the problem as a Markov Decision Process (MDP), where the agent's goal is to learn a policy that maps the current state of the system to an appropriate control action. They use a deep neural network to represent the policy, and train it using proximal policy optimization (PPO), a popular reinforcement learning algorithm.
Importantly, the authors show that their method can effectively stabilize a wide range of LTI systems, including those with unstable open-loop dynamics. This is achieved by incorporating a stability-based reward function that encourages the agent to learn a policy that keeps the system within a desired region of the state space.
Through extensive numerical experiments, the authors demonstrate the effectiveness of their approach on a variety of LTI benchmark problems. They show that their method can outperform both model-based control techniques and other reinforcement learning approaches, particularly in the presence of significant stochastic noise.
Critical Analysis
The paper presents a compelling approach to the challenging problem of learning to stabilize unknown linear systems, with several notable strengths:
- The ability to learn effective control policies from a single system trajectory is a significant practical advantage, as it avoids the need for detailed system identification or modeling.
- The incorporation of a stability-based reward function is a clever way to encourage the agent to learn behaviors that keep the system within a desired operating regime, even for inherently unstable systems.
- The empirical results demonstrate the method's effectiveness on a range of benchmark problems, suggesting it could be broadly applicable.
However, the paper also has some limitations that could be addressed in future work:
- The analysis is primarily focused on LTI systems, which may limit the applicability of the method to more complex, nonlinear dynamics. Extending the approach to handle nonlinear systems would be an important next step.
- The paper does not provide much insight into the interpretability or "explainability" of the learned control policies. Understanding how the agent arrives at its decisions could be helpful for building trust and practical application.
- The authors do not explore the sample efficiency of their method, which could be an important factor in real-world deployment scenarios with limited data.
Overall, the paper presents a valuable contribution to the field of learning-based control and stability-aware reinforcement learning. With further development and extension to more complex systems, the proposed approach could have significant practical impact in a range of applications.
Conclusion
This paper introduces a novel reinforcement learning-based method for learning to stabilize the behavior of unknown linear time-invariant (LTI) systems, even in the presence of stochastic noise. By formulating the problem as a Markov Decision Process and training a deep neural network policy using proximal policy optimization, the authors demonstrate the ability to learn effective control strategies from a single system trajectory, without requiring any prior knowledge of the system dynamics.
The key advantages of this approach are its practical applicability (due to the lack of modeling requirements) and its effectiveness in stabilizing inherently unstable LTI systems. While the current focus is on linear systems, extending the method to handle more complex, nonlinear dynamics would be an important area for future research. Additionally, improving the interpretability of the learned control policies and exploring sample efficiency could further enhance the real-world impact of this work.
Overall, the paper represents an important contribution to the field of learning-based control and stability-aware reinforcement learning, with the potential to enable more robust and adaptive control systems across a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning Low-dimensional Latent Dynamics from High-dimensional Observations: Non-asymptotics and Lower Bounds
Yuyang Zhang, Shahriar Talebi, Na Li
0
0
In this paper, we focus on learning a linear time-invariant (LTI) model with low-dimensional latent variables but high-dimensional observations. We provide an algorithm that recovers the high-dimensional features, i.e. column space of the observer, embeds the data into low dimensions and learns the low-dimensional model parameters. Our algorithm enjoys a sample complexity guarantee of order $tilde{mathcal{O}}(n/epsilon^2)$, where $n$ is the observation dimension. We further establish a fundamental lower bound indicating this complexity bound is optimal up to logarithmic factors and dimension-independent constants. We show that this inevitable linear factor of $n$ is due to the learning error of the observer's column space in the presence of high-dimensional noises. Extending our results, we consider a meta-learning problem inspired by various real-world applications, where the observer column space can be collectively learned from datasets of multiple LTI systems. An end-to-end algorithm is then proposed, facilitating learning LTI systems from a meta-dataset which breaks the sample complexity lower bound in certain scenarios.
6/27/2024
📈
Safely Learning Dynamical Systems
Amir Ali Ahmadi, Abraar Chaudhry, Vikas Sindhwani, Stephen Tu
0
0
A fundamental challenge in learning an unknown dynamical system is to reduce model uncertainty by making measurements while maintaining safety. We formulate a mathematical definition of what it means to safely learn a dynamical system by sequentially deciding where to initialize trajectories. The state of the system must stay within a safety region for a horizon of $T$ time steps under the action of all dynamical systems that (i) belong to a given initial uncertainty set, and (ii) are consistent with information gathered so far. First, we consider safely learning a linear dynamical system involving $n$ states. For the case $T=1$, we present an LP-based algorithm that either safely recovers the true dynamics from at most $n$ trajectories, or certifies that safe learning is impossible. For $T=2$, we give an SDP representation of the set of safe initial conditions and show that $lceil n/2 rceil$ trajectories generically suffice for safe learning. For $T = infty$, we provide SDP-representable inner approximations of the set of safe initial conditions and show that one trajectory generically suffices for safe learning. We extend a number of our results to the cases where the initial uncertainty set contains sparse, low-rank, or permutation matrices, or when the system has a control input. Second, we consider safely learning a general class of nonlinear dynamical systems. For the case $T=1$, we give an SOCP-based representation of the set of safe initial conditions. For $T=infty$, we provide semidefinite representable inner approximations to the set of safe initial conditions. We show how one can safely collect trajectories and fit a polynomial model of the nonlinear dynamics that is consistent with the initial uncertainty set and best agrees with the observations. We also present some extensions to cases where the measurements are noisy or the dynamical system involves disturbances.
6/11/2024
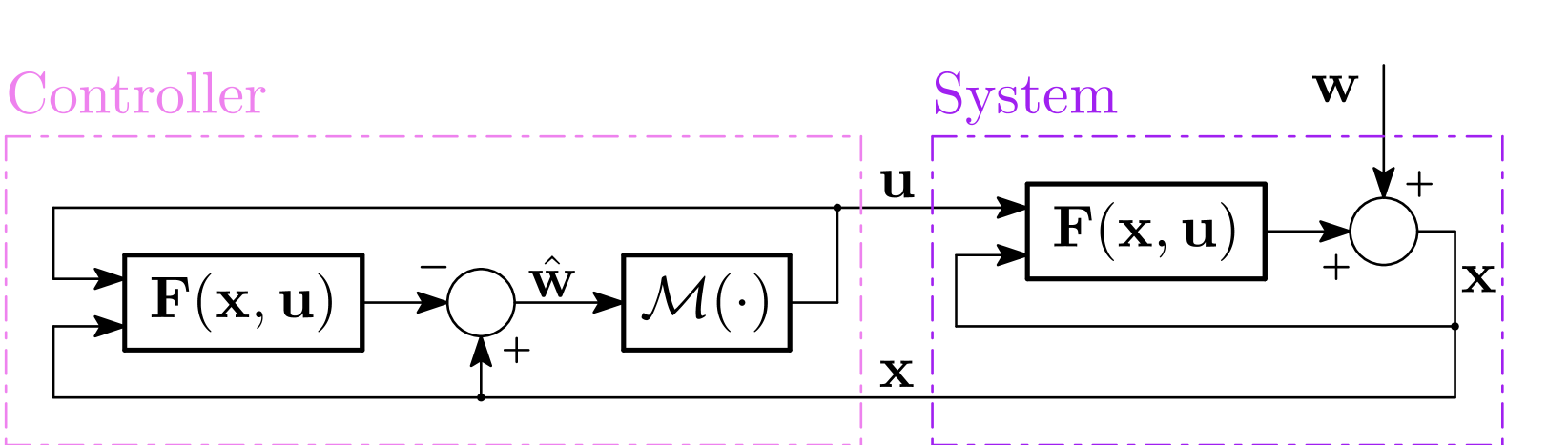
Learning to Boost the Performance of Stable Nonlinear Systems
Luca Furieri, Clara Luc'ia Galimberti, Giancarlo Ferrari-Trecate
0
0
The growing scale and complexity of safety-critical control systems underscore the need to evolve current control architectures aiming for the unparalleled performances achievable through state-of-the-art optimization and machine learning algorithms. However, maintaining closed-loop stability while boosting the performance of nonlinear control systems using data-driven and deep-learning approaches stands as an important unsolved challenge. In this paper, we tackle the performance-boosting problem with closed-loop stability guarantees. Specifically, we establish a synergy between the Internal Model Control (IMC) principle for nonlinear systems and state-of-the-art unconstrained optimization approaches for learning stable dynamics. Our methods enable learning over arbitrarily deep neural network classes of performance-boosting controllers for stable nonlinear systems; crucially, we guarantee Lp closed-loop stability even if optimization is halted prematurely, and even when the ground-truth dynamics are unknown, with vanishing conservatism in the class of stabilizing policies as the model uncertainty is reduced to zero. We discuss the implementation details of the proposed control schemes, including distributed ones, along with the corresponding optimization procedures, demonstrating the potential of freely shaping the cost functions through several numerical experiments.
5/3/2024

DySLIM: Dynamics Stable Learning by Invariant Measure for Chaotic Systems
Yair Schiff, Zhong Yi Wan, Jeffrey B. Parker, Stephan Hoyer, Volodymyr Kuleshov, Fei Sha, Leonardo Zepeda-N'u~nez
0
0
Learning dynamics from dissipative chaotic systems is notoriously difficult due to their inherent instability, as formalized by their positive Lyapunov exponents, which exponentially amplify errors in the learned dynamics. However, many of these systems exhibit ergodicity and an attractor: a compact and highly complex manifold, to which trajectories converge in finite-time, that supports an invariant measure, i.e., a probability distribution that is invariant under the action of the dynamics, which dictates the long-term statistical behavior of the system. In this work, we leverage this structure to propose a new framework that targets learning the invariant measure as well as the dynamics, in contrast with typical methods that only target the misfit between trajectories, which often leads to divergence as the trajectories' length increases. We use our framework to propose a tractable and sample efficient objective that can be used with any existing learning objectives. Our Dynamics Stable Learning by Invariant Measure (DySLIM) objective enables model training that achieves better point-wise tracking and long-term statistical accuracy relative to other learning objectives. By targeting the distribution with a scalable regularization term, we hope that this approach can be extended to more complex systems exhibiting slowly-variant distributions, such as weather and climate models.
6/7/2024