Learning Unsupervised Gaze Representation via Eye Mask Driven Information Bottleneck

0

Sign in to get full access
Overview
- This paper proposes a self-supervised method for learning a robust and informative gaze representation from unlabeled eye images.
- The key idea is to use an "eye mask" to selectively hide parts of the eye image during training, forcing the model to learn a compressed representation that captures the most relevant information for gaze estimation.
- This "eye mask driven information bottleneck" approach is inspired by the success of masked image modeling techniques, such as Masked Image Modeling as a Framework for Self-Supervised Learning.
Plain English Explanation
The paper tackles the challenge of learning how to estimate a person's gaze direction (where they are looking) without having access to labeled training data. This is an important problem for applications like virtual/augmented reality, human-computer interaction, and driver monitoring systems.
The researchers developed a clever technique that forces a neural network to learn a compressed representation of the eye region that is still informative for predicting gaze direction. They do this by randomly "masking out" or hiding parts of the eye image during training, so the network has to focus on the most important visual cues to solve the task.
This is inspired by the recent success of "masked image modeling" techniques, where neural networks are trained to reconstruct images from partially occluded inputs. The key insight is that this forces the network to learn a compact, meaningful representation of the image content.
Similarly, in this case, the "eye mask" encourages the network to extract the most relevant information for gaze estimation, without relying on superficial cues that might not generalize well. The resulting gaze representation can then be used for downstream tasks like gaze tracking or attention modeling, without the need for expensive labeled training data.
Technical Explanation
The paper introduces a self-supervised learning framework for extracting robust and informative gaze representations from unlabeled eye images. The core idea is to leverage an "eye mask" that randomly occludes parts of the input eye image during training, forcing the model to learn a compressed representation that captures the most relevant visual cues for gaze estimation.
This "eye mask driven information bottleneck" approach is inspired by the success of masked image modeling techniques, such as Masked Image Modeling as a Framework for Self-Supervised Learning. The authors hypothesize that by selectively hiding parts of the eye, the model will be encouraged to learn a more compact and generalized representation of gaze-related information, rather than relying on superficial or idiosyncratic visual features.
The proposed architecture consists of an encoder network that takes the masked eye image as input and outputs a gaze representation, and a decoder network that attempts to reconstruct the original unmasked eye image from this compressed representation. This reconstruction objective, combined with the masking process, forces the encoder to learn a meaningful and informative gaze encoding.
The authors demonstrate the effectiveness of their approach through experiments on several gaze estimation benchmarks, showing that the learned gaze representations can be used to achieve state-of-the-art performance on downstream tasks, even without access to labeled gaze data during training. This highlights the potential of self-supervised learning techniques, like the one proposed in this paper, to reduce the burden of expensive data collection and annotation for gaze-related applications.
Critical Analysis
The paper presents a well-designed and compelling approach to learning gaze representations in a self-supervised manner. The use of the "eye mask" to selectively occlude parts of the input image is a clever technique that builds on the success of masked image modeling, as seen in papers like Masked Image Modeling as a Framework for Self-Supervised Learning.
One potential limitation of the approach is that it may struggle with highly occluded or low-quality eye images, as the model is trained to reconstruct the full eye region from the masked input. This could be a concern for real-world applications, where eye images may be obstructed by factors like glasses, hair, or poor lighting conditions.
Additionally, the paper does not explore the model's robustness to domain shift, i.e., how well the learned representations generalize to eye images captured in different environments or with different camera setups. This is an important consideration for the practical deployment of such systems.
It would also be interesting to see how the proposed method compares to other self-supervised approaches for gaze representation learning, such as Eyes Wide Unshut: Unsupervised Mistake Detection for Egocentric Videos or A Generative Framework for Self-Supervised Facial Representation Learning. A more thorough comparative analysis could help establish the relative strengths and weaknesses of the proposed method.
Conclusion
This paper presents a novel self-supervised approach for learning robust and informative gaze representations from unlabeled eye images. By leveraging an "eye mask" to selectively occlude parts of the input during training, the model is forced to learn a compressed representation that captures the most relevant visual cues for gaze estimation.
The proposed method builds on the success of masked image modeling techniques and demonstrates state-of-the-art performance on gaze estimation benchmarks, without the need for costly labeled training data. This suggests that self-supervised learning can be a powerful tool for reducing the burden of data collection and annotation in gaze-related applications, such as virtual/augmented reality, human-computer interaction, and driver monitoring systems.
While the paper presents a strong technical contribution, future work could explore the model's robustness to real-world challenges, such as occlusions and domain shift, as well as compare its performance to other self-supervised gaze representation learning approaches. Overall, this research represents an important step forward in the development of more accessible and practical gaze estimation technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Unsupervised Gaze Representation via Eye Mask Driven Information Bottleneck
Yangzhou Jiang, Yinxin Lin, Yaoming Wang, Teng Li, Bilian Ke, Bingbing Ni
Appearance-based supervised methods with full-face image input have made tremendous advances in recent gaze estimation tasks. However, intensive human annotation requirement inhibits current methods from achieving industrial level accuracy and robustness. Although current unsupervised pre-training frameworks have achieved success in many image recognition tasks, due to the deep coupling between facial and eye features, such frameworks are still deficient in extracting useful gaze features from full-face. To alleviate above limitations, this work proposes a novel unsupervised/self-supervised gaze pre-training framework, which forces the full-face branch to learn a low dimensional gaze embedding without gaze annotations, through collaborative feature contrast and squeeze modules. In the heart of this framework is an alternating eye-attended/unattended masking training scheme, which squeezes gaze-related information from full-face branch into an eye-masked auto-encoder through an injection bottleneck design that successfully encourages the model to pays more attention to gaze direction rather than facial textures only, while still adopting the eye self-reconstruction objective. In the same time, a novel eye/gaze-related information contrastive loss has been designed to further boost the learned representation by forcing the model to focus on eye-centered regions. Extensive experimental results on several gaze benchmarks demonstrate that the proposed scheme achieves superior performances over unsupervised state-of-the-art.
Read more7/2/2024
✨
0
Domain-Adaptive Full-Face Gaze Estimation via Novel-View-Synthesis and Feature Disentanglement
Jiawei Qin, Takuru Shimoyama, Xucong Zhang, Yusuke Sugano
Along with the recent development of deep neural networks, appearance-based gaze estimation has succeeded considerably when training and testing within the same domain. Compared to the within-domain task, the variance of different domains makes the cross-domain performance drop severely, preventing gaze estimation deployment in real-world applications. Among all the factors, ranges of head pose and gaze are believed to play significant roles in the final performance of gaze estimation, while collecting large ranges of data is expensive. This work proposes an effective model training pipeline consisting of a training data synthesis and a gaze estimation model for unsupervised domain adaptation. The proposed data synthesis leverages the single-image 3D reconstruction to expand the range of the head poses from the source domain without requiring a 3D facial shape dataset. To bridge the inevitable gap between synthetic and real images, we further propose an unsupervised domain adaptation method suitable for synthetic full-face data. We propose a disentangling autoencoder network to separate gaze-related features and introduce background augmentation consistency loss to utilize the characteristics of the synthetic source domain. Through comprehensive experiments, it shows that the model using only our synthetic training data can perform comparably to real data extended with a large label range. Our proposed domain adaptation approach further improves the performance on multiple target domains. The code and data will be available at https://github.com/ut-vision/AdaptiveGaze.
Read more7/9/2024
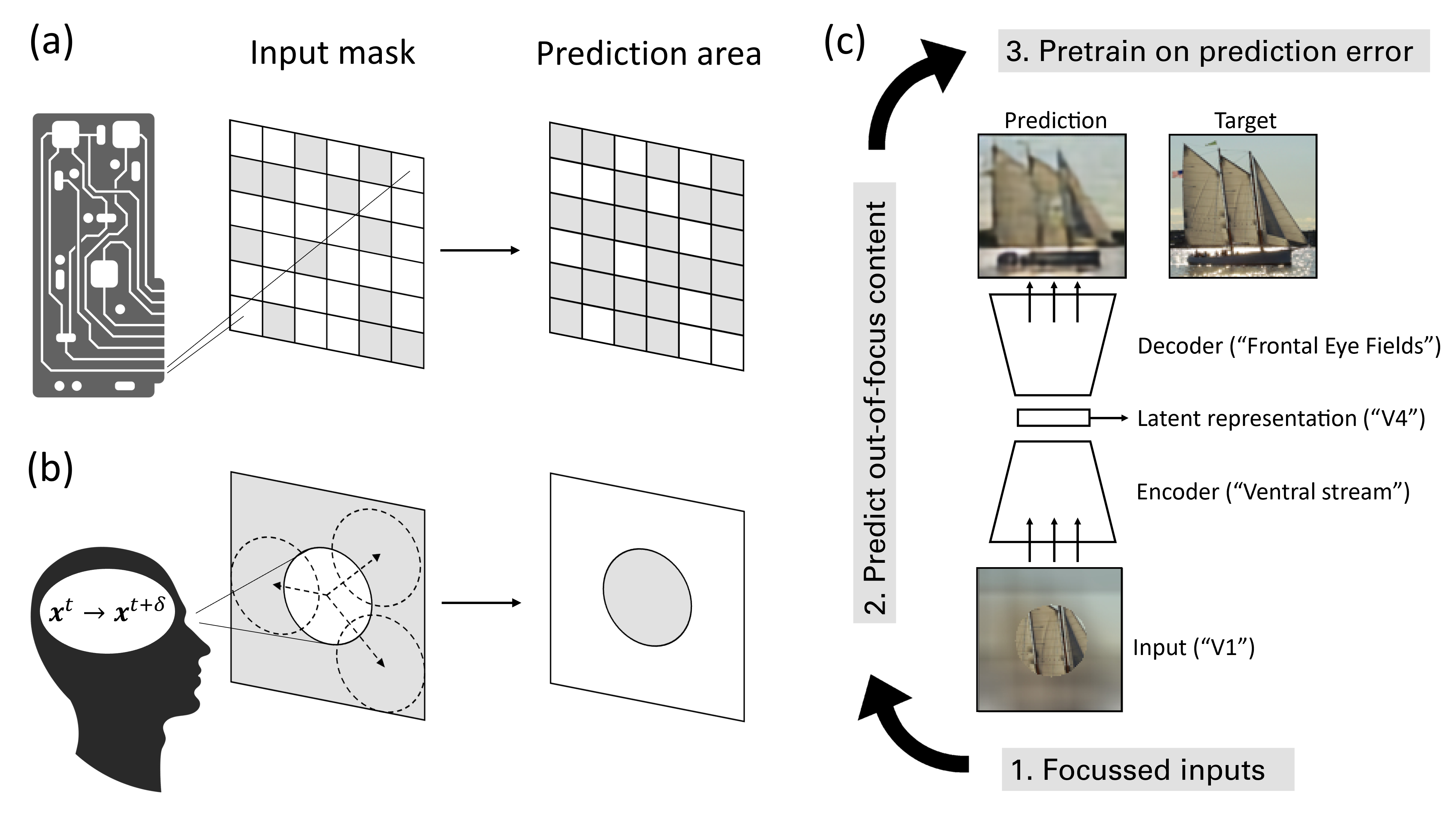
0
Masked Image Modeling as a Framework for Self-Supervised Learning across Eye Movements
Robin Weiler, Matthias Brucklacher, Cyriel M. A. Pennartz, Sander M. Boht'e
To make sense of their surroundings, intelligent systems must transform complex sensory inputs to structured codes that are reduced to task-relevant information such as object category. Biological agents achieve this in a largely autonomous manner, presumably via self-supervised learning. Whereas previous attempts to model the underlying mechanisms were largely discriminative in nature, there is ample evidence that the brain employs a generative model of the world. Here, we propose that eye movements, in combination with the focused nature of primate vision, constitute a generative, self-supervised task of predicting and revealing visual information. We construct a proof-of-principle model starting from the framework of masked image modeling (MIM), a common approach in deep representation learning. To do so, we analyze how core components of MIM such as masking technique and data augmentation influence the formation of category-specific representations. This allows us not only to better understand the principles behind MIM, but to then reassemble a MIM more in line with the focused nature of biological perception. We find that MIM disentangles neurons in latent space without explicit regularization, a property that has been suggested to structure visual representations in primates. Together with previous findings of invariance learning, this highlights an interesting connection of MIM to latent regularization approaches for self-supervised learning. The source code is available under https://github.com/RobinWeiler/FocusMIM
Read more7/9/2024

0
Eyes Wide Unshut: Unsupervised Mistake Detection in Egocentric Video by Detecting Unpredictable Gaze
Michele Mazzamuto, Antonino Furnari, Giovanni Maria Farinella
In this paper, we address the challenge of unsupervised mistake detection in egocentric procedural video through the analysis of gaze signals. Traditional supervised mistake detection methods rely on manually labeled mistakes, and hence suffer from domain-dependence and scalability issues. We introduce an unsupervised method for detecting mistakes in videos of human activities, overcoming the challenges of domain-specific requirements and the need for annotated data. We postulate that, when a subject is making a mistake in the execution of a procedure, their attention patterns will deviate from normality. We hence propose to detect mistakes by comparing gaze trajectories predicted from input video with ground truth gaze signals collected through a gaze tracker. Since predicting gaze in video is characterized by high uncertainty, we propose a novel textit{gaze completion task}, which aims to predict gaze from visual observations and partial gaze trajectories. We further contribute a textit{gaze completion approach} based on a Gaze-Frame Correlation module to explicitly model the correlation between gaze information and each local visual token. Inconsistencies between the predicted and observed gaze trajectories act as an indicator for identifying mistakes. Experiments on the EPIC-Tent, HoloAssist and IndustReal datasets showcase the effectiveness of the proposed approach as compared to unsupervised and one-class techniques. Our method is ranked first on the HoloAssist Mistake Detection challenge.
Read more7/31/2024