Lectures on Parallel Computing

0
🤷
Sign in to get full access
Overview
- The lecture notes are designed for an undergraduate course on Fundamentals of Parallel Computing and as background for graduate courses on High-Performance Computing, parallel algorithms, and shared-memory multiprocessor programming.
- They introduce theoretical concepts and tools for expressing, analyzing, and evaluating parallel algorithms, and cover the popular frameworks OpenMP and MPI, as well as the pthreads threading interface.
- The examples are presented in a C-like style, and the notes deliberately do not cover GPU architectures and programming.
- The focus is on deterministic algorithms, and the student is encouraged to understand concepts and algorithms visually.
- The exercises can be used for self-study and as inspiration for small implementation projects in OpenMP and MPI.
Plain English Explanation
The provided lecture notes are designed to teach the fundamentals of parallel computing to undergraduate students, as well as provide background information for graduate-level courses on high-performance computing and related topics. The notes cover the key theoretical concepts and tools needed to express, analyze, and evaluate parallel algorithms, with a focus on the two most widely used parallel programming frameworks: OpenMP and MPI. They also include information on the pthreads threading interface, which can be used to write parallel programs for either shared or distributed memory parallel computers.
The examples provided in the lecture notes are written in a C-like style, and the notes deliberately avoid covering GPU architectures and programming, as the general principles and guidelines discussed will be just as relevant for efficiently utilizing various GPU architectures. The focus is on deterministic algorithms, meaning they always produce the same output given the same input, without using randomization.
The lecture notes emphasize the importance of understanding parallel computing concepts and algorithms visually, and the exercises provided can be used for self-study or as the basis for small implementation projects in OpenMP and MPI. These projects can be a valuable part of any serious course on parallel computing, as they allow students to actually implement and carefully benchmark the suggested algorithms on the parallel computing system available as part of the course.
Technical Explanation
The lecture notes cover a range of topics related to parallel computing, including theoretical concepts, tools for expressing and analyzing parallel algorithms, and the two most widely used parallel programming frameworks: OpenMP and MPI. The notes also include information on the pthreads threading interface, which can be used to write parallel programs for either shared or distributed memory parallel computers.
The examples provided in the lecture notes are presented in a C-like style, and the notes deliberately do not cover GPU architectures and programming. The focus is on deterministic algorithms, meaning they always produce the same output given the same input, without using randomization.
The lecture notes emphasize the importance of understanding parallel computing concepts and algorithms visually, and the exercises provided can be used for self-study or as the basis for small implementation projects in OpenMP and MPI. These projects can be a valuable part of any serious course on parallel computing, as they allow students to actually implement and carefully benchmark the suggested algorithms on the parallel computing system available as part of the course.
Critical Analysis
The lecture notes provide a comprehensive introduction to the fundamentals of parallel computing, covering both theoretical concepts and practical programming frameworks. The focus on deterministic algorithms and the avoidance of GPU architectures and programming may be seen as a limitation by some, as these topics are increasingly relevant in the field of parallel computing.
However, the emphasis on understanding concepts and algorithms visually, as well as the inclusion of exercises for self-study and project-based learning, are significant strengths of the lecture notes. These features can help students develop a deeper understanding of parallel computing and its practical applications.
One potential area for further research could be the integration of GPU architectures and programming into the lecture notes, as these technologies are becoming increasingly important in the field of high-performance computing. Additionally, the inclusion of more real-world case studies and applications of parallel computing could further enhance the relevance and practical value of the course material.
Conclusion
The lecture notes provided offer a comprehensive introduction to the fundamentals of parallel computing, covering both theoretical concepts and practical programming frameworks. The focus on visual understanding, self-study exercises, and project-based learning can help students develop a deep understanding of parallel computing and its applications.
While the lack of coverage of GPU architectures and programming may be seen as a limitation, the general principles and guidelines discussed in the lecture notes can still be highly relevant for efficiently utilizing various parallel computing technologies, including GPUs. Overall, the lecture notes appear to be a valuable resource for both undergraduate and graduate students interested in the field of parallel computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Lectures on Parallel Computing
Jesper Larsson Traff
These lecture notes are designed to accompany an imaginary, virtual, undergraduate, one or two semester course on fundamentals of Parallel Computing as well as to serve as background and reference for graduate courses on High-Performance Computing, parallel algorithms and shared-memory multiprocessor programming. They introduce theoretical concepts and tools for expressing, analyzing and judging parallel algorithms and, in detail, cover the two most widely used concrete frameworks OpenMP and MPI as well as the threading interface pthreads for writing parallel programs for either shared or distributed memory parallel computers with emphasis on general concepts and principles. Code examples are given in a C-like style and many are actual, correct C code. The lecture notes deliberately do not cover GPU architectures and GPU programming, but the general concerns, guidelines and principles (time, work, cost, efficiency, scalability, memory structure and bandwidth) will be just as relevant for efficiently utilizing various GPU architectures. Likewise, the lecture notes focus on deterministic algorithms only and do not use randomization. The student of this material will find it instructive to take the time to understand concepts and algorithms visually. The exercises can be used for self-study and as inspiration for small implementation projects in OpenMP and MPI that can and should accompany any serious course on Parallel Computing. The student will benefit from actually implementing and carefully benchmarking the suggested algorithms on the parallel computing system that may or should be made available as part of such a Parallel Computing course. In class, the exercises can be used as basis for hand-ins and small programming projects for which sufficient, additional detail and precision should be provided by the instructor.
Read more7/29/2024
🚀
0
New!A Study of Performance Programming of CPU, GPU accelerated Computers and SIMD Architecture
Xinyao Yi
Parallel computing is a standard approach to achieving high-performance computing (HPC). Three commonly used methods to implement parallel computing include: 1) applying multithreading technology on single-core or multi-core CPUs; 2) incorporating powerful parallel computing devices such as GPUs, FPGAs, and other accelerators; and 3) utilizing special parallel architectures like Single Instruction/Multiple Data (SIMD). Many researchers have made efforts using different parallel technologies, including developing applications, conducting performance analyses, identifying performance bottlenecks, and proposing feasible solutions. However, balancing and optimizing parallel programs remain challenging due to the complexity of parallel algorithms and hardware architectures. Issues such as data transfer between hosts and devices in heterogeneous systems continue to be bottlenecks that limit performance. This work summarizes a vast amount of information on various parallel programming techniques, aiming to present the current state and future development trends of parallel programming, performance issues, and solutions. It seeks to give readers an overall picture and provide background knowledge to support subsequent research.
Read more9/18/2024
0
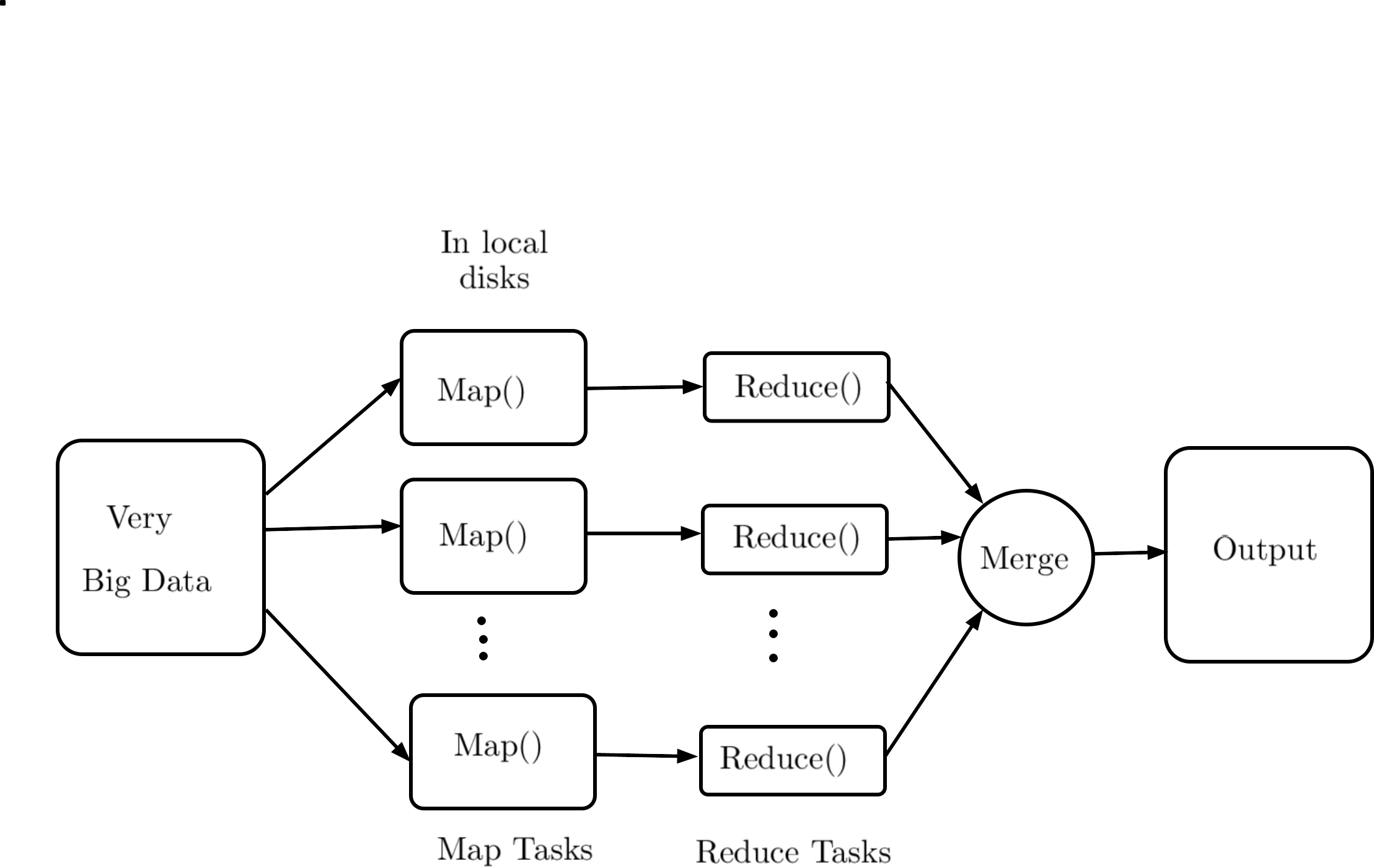
Analysis of Distributed Algorithms for Big-data
Rajendra Purohit, K R Chowdhary, S D Purohit
The parallel and distributed processing are becoming de facto industry standard, and a large part of the current research is targeted on how to make computing scalable and distributed, dynamically, without allocating the resources on permanent basis. The present article focuses on the study and performance of distributed and parallel algorithms their file systems, to achieve scalability at local level (OpenMP platform), and at global level where computing and file systems are distributed. Various applications, algorithms,file systems have been used to demonstrate the areas, and their performance studies have been presented. The systems and applications chosen here are of open-source nature, due to their wider applicability.
Read more4/10/2024

0
DNA sequence alignment: An assignment for OpenMP, MPI, and CUDA/OpenCL
Arturo Gonzalez-Escribano (Universidad de Valladolid, Spain), Diego Garc'ia-'Alvarez (Universidad de Valladolid, Spain), Jes'us C'amara (Universidad de Valladolid, Spain)
We present an assignment for a full Parallel Computing course. Since 2017/2018, we have proposed a different problem each academic year to illustrate various methodologies for approaching the same computational problem using different parallel programming models. They are designed to be parallelized using shared-memory programming with OpenMP, distributed-memory programming with MPI, and GPU programming with CUDA or OpenCL. The problem chosen for this year implements a brute-force solution for exact DNA sequence alignment of multiple patterns. The program searches for exact coincidences of multiple nucleotide strings in a long DNA sequence. The sequential implementation is designed to be clear and understandable to students while offering many opportunities for parallelization and optimization. This assignment addresses key concepts many students find difficult to apply in practical scenarios: race conditions, reductions, collective operations, and point-to-point communications. It also covers the problem of parallel generation of pseudo-random sequences and strategies to notify and stop speculative computations when matches are found. This assignment serves as an exercise that reinforces basic knowledge and prepares students for more complex parallel computing concepts and structures. It has been successfully implemented as a practical assignment in a Parallel Computing course in the third year of a Computer Engineering degree program. Supporting materials for this and previous assignments in this series are publicly available.
Read more9/11/2024