LEEETs-Dial: Linguistic Entrainment in End-to-End Task-oriented Dialogue systems

0
🐍
Sign in to get full access
Overview
- Linguistic entrainment, or alignment, is a phenomenon where people in a conversation start to use similar language patterns.
- This can lead to a more natural user experience, but most dialogue systems don't have features for achieving this.
- The paper introduces methods for enabling dialogue entrainment in a GPT-2-based conversational system using shared vocabulary.
- The approaches include training instance weighting, entrainment-specific loss, and additional conditioning to align the system's responses with the user's language.
- The researchers demonstrate that all three methods significantly improve entrainment compared to a base model without entrainment optimization.
Plain English Explanation
When people have a conversation, they often unconsciously start to use similar words, phrases, and ways of speaking as the person they're talking to. This "linguistic entrainment" or "alignment" can make the conversation feel more natural and comfortable.
Imagine two friends chatting - over time, they may start adopting each other's slang, mannerisms, or sentence structures without even realizing it. This mirroring effect helps the conversation flow smoothly.
However, most conversational AI systems today don't have the capability to entrain or align their language with the user. The paper addresses this by developing techniques to enable an AI dialogue system based on the GPT-2 language model to dynamically match the user's vocabulary and phrasing.
The key ideas include:
- Weighting training examples that demonstrate good entrainment more heavily
- Adding a special loss function component to reward entrainment
- Providing the system with additional context about the user's language to condition its responses
By using these methods, the researchers were able to significantly improve the entrainment of the AI system compared to a baseline model without these entrainment-focused optimizations. This makes the AI's language sound more natural and human-like when conversing with users.
Technical Explanation
The paper investigates methods for enabling linguistic entrainment, or alignment of language patterns, in a GPT-2-based end-to-end task-oriented dialogue system.
The researchers experiment with three different approaches:
-
Training Instance Weighting: They assign higher weights to training examples that demonstrate good entrainment, encouraging the model to learn these patterns.
-
Entrainment-Specific Loss: They add a special loss function component that directly rewards the model for generating responses that are linguistically aligned with the user.
-
Additional Conditioning: They provide the model with extra contextual information about the user's language to help it better match their vocabulary and phrasing.
Through automated and human evaluation metrics, the paper demonstrates that all three of these techniques lead to significantly improved entrainment compared to a base GPT-2 dialogue model without any entrainment-focused optimizations.
Critical Analysis
The paper provides a thorough technical evaluation of the proposed entrainment methods, but it acknowledges some potential limitations. For example, the experiments were conducted in a relatively constrained, task-oriented dialogue setting. Further research would be needed to see how well these techniques generalize to more open-ended, free-form conversations.
Additionally, the paper does not delve deeply into potential ethical or societal implications of dialogue systems that can so closely mirror a user's language. There could be concerns around manipulation, privacy, or the system potentially amplifying biases present in the user's speech.
Overall, the research represents an important step forward in developing more natural, human-like conversational AI. However, as these systems become more advanced, it will be crucial to consider the broader impacts and ensure they are designed with ethical principles in mind.
Conclusion
This paper introduces novel methods for enabling linguistic entrainment, or alignment of language patterns, in a GPT-2-based task-oriented dialogue system. By experimenting with techniques like training instance weighting, entrainment-specific loss, and additional user language conditioning, the researchers were able to significantly improve the system's ability to mirror the user's vocabulary and phrasing.
These advancements bring conversational AI systems closer to achieving a more natural, human-like interaction. As the field continues to progress, it will be important to thoughtfully address potential ethical concerns and ensure these powerful technologies are developed responsibly. Overall, this research represents an important contribution towards building more intelligent and empathetic dialogue agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
LEEETs-Dial: Linguistic Entrainment in End-to-End Task-oriented Dialogue systems
Nalin Kumar, Ondv{r}ej Duv{s}ek
Linguistic entrainment, or alignment, represents a phenomenon where linguistic patterns employed by conversational participants converge to one another. While entrainment has been shown to produce a more natural user experience, most dialogue systems do not have any provisions for it. In this work, we introduce methods for achieving dialogue entrainment in a GPT-2-based end-to-end task-oriented dialogue system through the utilization of shared vocabulary. We experiment with training instance weighting, entrainment-specific loss, and additional conditioning to generate responses that align with the user. We demonstrate that all three approaches produce significantly better entrainment than the base, non-entrainment-optimized model, as confirmed by both automated and manual evaluation metrics.
Read more4/5/2024

0
Language Proficiency and F0 Entrainment: A Study of L2 English Imitation in Italian, French, and Slovak Speakers
Zheng Yuan, v{S}tefan Bev{n}uv{s}, Alessandro D'Ausilio
This study explores F0 entrainment in second language (L2) English speech imitation during an Alternating Reading Task (ART). Participants with Italian, French, and Slovak native languages imitated English utterances, and their F0 entrainment was quantified using the Dynamic Time Warping (DTW) distance between the parameterized F0 contours of the imitated utterances and those of the model utterances. Results indicate a nuanced relationship between L2 English proficiency and entrainment: speakers with higher proficiency generally exhibit less entrainment in pitch variation and declination. However, within dyads, the more proficient speakers demonstrate a greater ability to mimic pitch range, leading to increased entrainment. This suggests that proficiency influences entrainment differently at individual and dyadic levels, highlighting the complex interplay between language skill and prosodic adaptation.
Read more4/17/2024
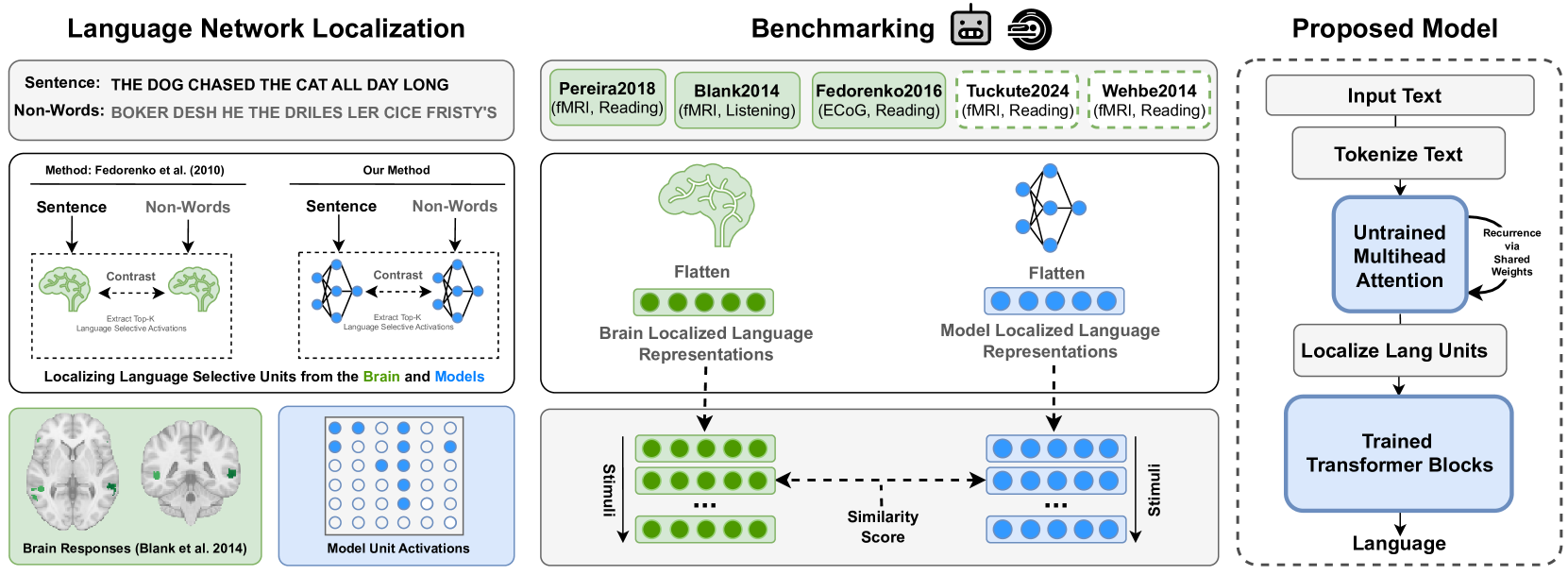
0
Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
Badr AlKhamissi, Greta Tuckute, Antoine Bosselut, Martin Schrimpf
Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.
Read more6/24/2024

0
Breaking Boundaries: Investigating the Effects of Model Editing on Cross-linguistic Performance
Somnath Banerjee, Avik Halder, Rajarshi Mandal, Sayan Layek, Ian Soboroff, Rima Hazra, Animesh Mukherjee
The integration of pretrained language models (PLMs) like BERT and GPT has revolutionized NLP, particularly for English, but it has also created linguistic imbalances. This paper strategically identifies the need for linguistic equity by examining several knowledge editing techniques in multilingual contexts. We evaluate the performance of models such as Mistral, TowerInstruct, OpenHathi, Tamil-Llama, and Kan-Llama across languages including English, German, French, Italian, Spanish, Hindi, Tamil, and Kannada. Our research identifies significant discrepancies in normal and merged models concerning cross-lingual consistency. We employ strategies like 'each language for itself' (ELFI) and 'each language for others' (ELFO) to stress-test these models. Our findings demonstrate the potential for LLMs to overcome linguistic barriers, laying the groundwork for future research in achieving linguistic inclusivity in AI technologies.
Read more7/19/2024