LeKUBE: A Legal Knowledge Update BEnchmark

0

Sign in to get full access
Overview
- Introduces LeKUBE: A Legal Knowledge Update BEnchmark
- Evaluates the ability of large language models to update their knowledge on legal topics
- Provides a dataset and metrics for benchmarking knowledge update performance
Plain English Explanation
LeKUBE: A Legal Knowledge Update BEnchmark is a new benchmark that evaluates how well large language models can update their knowledge on legal topics. As new laws and court rulings are constantly emerging, it's important that these models can quickly and accurately incorporate the latest information.
The key idea behind LeKUBE is to present language models with a series of legal questions, where the answers may change over time due to updates in the law. The models must then demonstrate their ability to recognize when information is outdated and provide updated, accurate responses. This tests not only the models' legal knowledge, but also their capacity to dynamically update that knowledge.
By establishing this benchmark, the researchers aim to spur progress in developing language models that can keep pace with the ever-evolving legal landscape. Accurate and up-to-date legal knowledge is crucial for many real-world applications, from legal research to policy advising. LeKUBE provides a standardized way to measure and track advancements in this area.
Technical Explanation
LeKUBE is a benchmark designed to evaluate how well large language models can update their knowledge on legal topics over time. The researchers created a dataset of legal questions and answers, where the answers may change due to updates in the law. They then present these questions to language models and assess their ability to recognize when information is outdated and provide accurate, updated responses.
The dataset covers a range of legal domains, including civil law, criminal law, and intellectual property. For each question, the researchers track when the underlying law was updated and the corresponding change in the correct answer. This allows them to evaluate not only the models' initial legal knowledge, but also their capacity to adapt to new information.
The researchers propose several metrics to assess the models' performance, including accuracy, F1 score, and a novel "Knowledge Update Score" that specifically measures how well the models recognize and respond to changes in the law.
By establishing this LeKUBE benchmark, the researchers aim to drive progress in developing language models that can keep pace with the evolving legal landscape. Accurate and up-to-date legal knowledge is crucial for many real-world applications, and LeKUBE provides a standardized way to measure and track advancements in this area.
Critical Analysis
The LeKUBE benchmark represents an important step forward in evaluating the capabilities of large language models to handle dynamic, time-sensitive information. The researchers have thoughtfully designed the dataset and metrics to capture the nuances of legal knowledge updates.
However, one potential limitation is the scope of the dataset. While it covers several key legal domains, there may be other areas of law that evolve rapidly and are not represented. Additionally, the researchers acknowledge that their dataset is focused on US law, and further work may be needed to extend the benchmark to other legal systems.
Another area for further research is understanding the specific mechanisms by which language models can effectively update their knowledge. The researchers provide some insights into this, but more work may be needed to develop robust knowledge update strategies that can be generalized across domains.
Overall, LeKUBE is a valuable contribution to the field of language model evaluation and provides a strong foundation for continued progress in this important area.
Conclusion
LeKUBE: A Legal Knowledge Update BEnchmark introduces a new benchmark for evaluating the ability of large language models to update their knowledge on legal topics over time. By creating a dataset of legal questions with dynamic answers and proposing novel evaluation metrics, the researchers have provided a valuable tool for driving progress in this critical area.
Accurate and up-to-date legal knowledge is essential for many real-world applications, and the LeKUBE benchmark offers a standardized way to measure and track advancements in the capacity of language models to adapt to the constantly evolving legal landscape. As the field of natural language processing continues to advance, this benchmark will play an important role in ensuring that language models can keep pace with the latest legal developments and provide reliable, informed support for a wide range of legal applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LeKUBE: A Legal Knowledge Update BEnchmark
Changyue Wang, Weihang Su, Hu Yiran, Qingyao Ai, Yueyue Wu, Cheng Luo, Yiqun Liu, Min Zhang, Shaoping Ma
Recent advances in Large Language Models (LLMs) have significantly shaped the applications of AI in multiple fields, including the studies of legal intelligence. Trained on extensive legal texts, including statutes and legal documents, the legal LLMs can capture important legal knowledge/concepts effectively and provide important support for downstream legal applications such as legal consultancy. Yet, the dynamic nature of legal statutes and interpretations also poses new challenges to the use of LLMs in legal applications. Particularly, how to update the legal knowledge of LLMs effectively and efficiently has become an important research problem in practice. Existing benchmarks for evaluating knowledge update methods are mostly designed for the open domain and cannot address the specific challenges of the legal domain, such as the nuanced application of new legal knowledge, the complexity and lengthiness of legal regulations, and the intricate nature of legal reasoning. To address this gap, we introduce the Legal Knowledge Update BEnchmark, i.e. LeKUBE, which evaluates knowledge update methods for legal LLMs across five dimensions. Specifically, we categorize the needs of knowledge updates in the legal domain with the help of legal professionals, and then hire annotators from law schools to create synthetic updates to the Chinese Criminal and Civil Code as well as sets of questions of which the answers would change after the updates. Through a comprehensive evaluation of state-of-the-art knowledge update methods, we reveal a notable gap between existing knowledge update methods and the unique needs of the legal domain, emphasizing the need for further research and development of knowledge update mechanisms tailored for legal LLMs.
Read more7/22/2024
📉
0
CodeUpdateArena: Benchmarking Knowledge Editing on API Updates
Zeyu Leo Liu, Shrey Pandit, Xi Ye, Eunsol Choi, Greg Durrett
Large language models (LLMs) are increasingly being used to synthesize and reason about source code. However, the static nature of these models' knowledge does not reflect the fact that libraries and API functions they invoke are continuously evolving, with functionality being added or changing. While numerous benchmarks evaluate how LLMs can generate code, no prior work has studied how an LLMs' knowledge about code API functions can be updated. To fill this gap, we present CodeUpdateArena, a benchmark for knowledge editing in the code domain. An instance in our benchmark consists of a synthetic API function update paired with a program synthesis example that uses the updated functionality; our goal is to update an LLM to be able to solve this program synthesis example without providing documentation of the update at inference time. Compared to knowledge editing for facts encoded in text, success here is more challenging: a code LLM must correctly reason about the semantics of the modified function rather than just reproduce its syntax. Our dataset is constructed by first prompting GPT-4 to generate atomic and executable function updates. Then, for each update, we generate program synthesis examples whose code solutions are prone to use the update. Our benchmark covers updates of various types to 54 functions from seven diverse Python packages, with a total of 670 program synthesis examples. Our experiments show that prepending documentation of the update to open-source code LLMs (i.e., DeepSeek, CodeLlama) does not allow them to incorporate changes for problem solving, and existing knowledge editing techniques also have substantial room for improvement. We hope our benchmark will inspire new methods for knowledge updating in code LLMs.
Read more7/10/2024
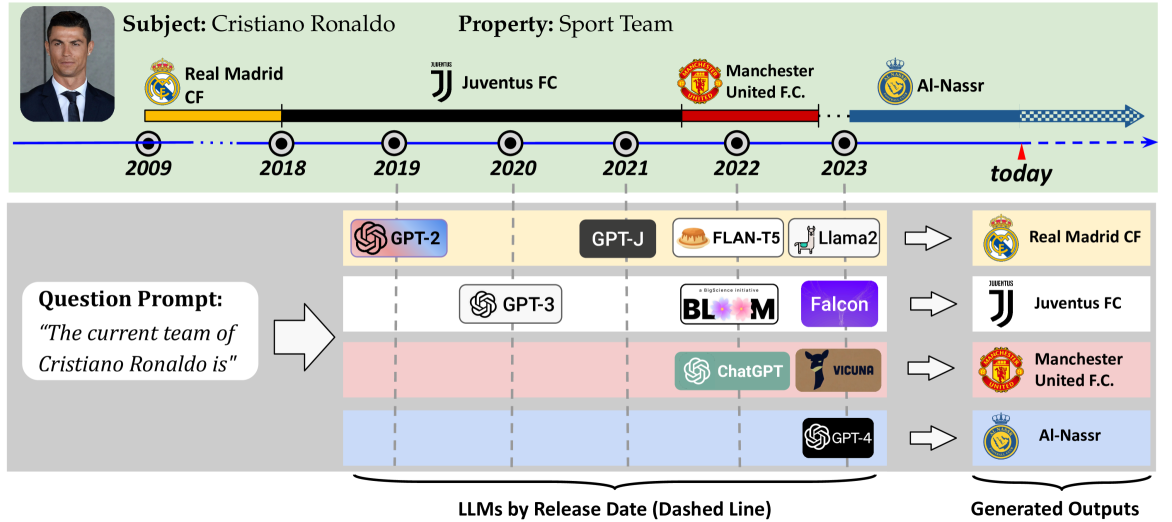
0
Is Your LLM Outdated? Benchmarking LLMs & Alignment Algorithms for Time-Sensitive Knowledge
Seyed Mahed Mousavi, Simone Alghisi, Giuseppe Riccardi
LLMs acquire knowledge from massive data snapshots collected at different timestamps. Their knowledge is then commonly evaluated using static benchmarks. However, factual knowledge is generally subject to time-sensitive changes, and static benchmarks cannot address those cases. We present an approach to dynamically evaluate the knowledge in LLMs and their time-sensitiveness against Wikidata, a publicly available up-to-date knowledge graph. We evaluate the time-sensitive knowledge in twenty-four private and open-source LLMs, as well as the effectiveness of four editing methods in updating the outdated facts. Our results show that 1) outdatedness is a critical problem across state-of-the-art LLMs; 2) LLMs output inconsistent answers when prompted with slight variations of the question prompt; and 3) the performance of the state-of-the-art knowledge editing algorithms is very limited, as they can not reduce the cases of outdatedness and output inconsistency.
Read more6/13/2024

0
Optimizing Numerical Estimation and Operational Efficiency in the Legal Domain through Large Language Models
Jia-Hong Huang, Chao-Chun Yang, Yixian Shen, Alessio M. Pacces, Evangelos Kanoulas
The legal landscape encompasses a wide array of lawsuit types, presenting lawyers with challenges in delivering timely and accurate information to clients, particularly concerning critical aspects like potential imprisonment duration or financial repercussions. Compounded by the scarcity of legal experts, there's an urgent need to enhance the efficiency of traditional legal workflows. Recent advances in deep learning, especially Large Language Models (LLMs), offer promising solutions to this challenge. Leveraging LLMs' mathematical reasoning capabilities, we propose a novel approach integrating LLM-based methodologies with specially designed prompts to address precision requirements in legal Artificial Intelligence (LegalAI) applications. The proposed work seeks to bridge the gap between traditional legal practices and modern technological advancements, paving the way for a more accessible, efficient, and equitable legal system. To validate this method, we introduce a curated dataset tailored to precision-oriented LegalAI tasks, serving as a benchmark for evaluating LLM-based approaches. Extensive experimentation confirms the efficacy of our methodology in generating accurate numerical estimates within the legal domain, emphasizing the role of LLMs in streamlining legal processes and meeting the evolving demands of LegalAI.
Read more7/30/2024