CodeUpdateArena: Benchmarking Knowledge Editing on API Updates

0
📉
Sign in to get full access
Overview
- This paper examines how large language models (LLMs) can be used to generate and reason about code, but notes that the static nature of these models' knowledge does not reflect the fact that code libraries and APIs are constantly evolving.
- The paper presents a new benchmark called CodeUpdateArena to test how well LLMs can update their knowledge to handle changes in code APIs.
- The benchmark involves synthetic API function updates paired with program synthesis examples that use the updated functionality, with the goal of testing whether an LLM can solve these examples without being provided the documentation for the updates.
Plain English Explanation
Large language models (LLMs) are powerful tools that can be used to generate and understand code. However, the knowledge these models have is static - it doesn't change even as the actual code libraries and APIs they rely on are constantly being updated with new features and changes.
The CodeUpdateArena benchmark is designed to test how well LLMs can update their own knowledge to keep up with these real-world changes. It presents the model with a synthetic update to a code API function, along with a programming task that requires using the updated functionality. The goal is to see if the model can solve the programming task without being explicitly shown the documentation for the API update.
This is a more challenging task than updating an LLM's knowledge about facts encoded in regular text. With code, the model has to correctly reason about the semantics and behavior of the modified function, not just reproduce its syntax. Succeeding at this benchmark would show that an LLM can dynamically adapt its knowledge to handle evolving code APIs, rather than being limited to a fixed set of capabilities.
Technical Explanation
The paper presents the CodeUpdateArena benchmark to test how well large language models (LLMs) can update their knowledge about code APIs that are continuously evolving.
The benchmark consists of synthetic API function updates paired with program synthesis examples that use the updated functionality. The goal is to update an LLM so that it can solve these programming tasks without being provided the documentation for the API changes at inference time. This is more challenging than updating an LLM's knowledge about general facts, as the model must reason about the semantics of the modified function rather than just reproducing its syntax.
The dataset is constructed by first prompting GPT-4 to generate atomic and executable function updates across 54 functions from 7 diverse Python packages. Then, for each update, the authors generate program synthesis examples whose solutions are prone to use the updated functionality.
The paper's experiments show that simply prepending documentation of the update to open-source code LLMs like DeepSeek and CodeLlama does not allow them to incorporate the changes for problem solving. Furthermore, existing knowledge editing techniques also have substantial room for improvement on this benchmark.
Critical Analysis
The CodeUpdateArena benchmark represents an important step forward in evaluating the capabilities of large language models (LLMs) to handle evolving code APIs, a critical limitation of current approaches. By focusing on the semantics of code updates rather than just their syntax, the benchmark poses a more challenging and realistic test of an LLM's ability to dynamically adapt its knowledge.
However, the paper acknowledges some potential limitations of the benchmark. For example, the synthetic nature of the API updates may not fully capture the complexities of real-world code library changes. Additionally, the scope of the benchmark is limited to a relatively small set of Python functions, and it remains to be seen how well the findings generalize to larger, more diverse codebases.
Further research is also needed to develop more effective techniques for enabling LLMs to update their knowledge about code APIs. The paper's finding that simply providing documentation is insufficient suggests that more sophisticated approaches, potentially drawing on ideas from dynamic knowledge verification or code editing, may be required.
Overall, the CodeUpdateArena benchmark represents an important contribution to the ongoing efforts to improve the code generation capabilities of large language models and make them more robust to the evolving nature of software development.
Conclusion
This paper presents a new benchmark called CodeUpdateArena to evaluate how well large language models (LLMs) can update their knowledge about evolving code APIs, a critical limitation of current approaches. The benchmark involves synthetic API function updates paired with programming tasks that require using the updated functionality, challenging the model to reason about the semantic changes rather than just reproducing syntax.
The paper's experiments show that existing techniques, such as simply providing documentation, are not sufficient for enabling LLMs to incorporate these changes for problem solving. This highlights the need for more advanced knowledge editing methods that can dynamically update an LLM's understanding of code APIs.
The CodeUpdateArena benchmark represents an important step forward in assessing the capabilities of LLMs in the code generation domain, and the insights from this research can help drive the development of more robust and adaptable models that can keep pace with the rapidly evolving software landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
CodeUpdateArena: Benchmarking Knowledge Editing on API Updates
Zeyu Leo Liu, Shrey Pandit, Xi Ye, Eunsol Choi, Greg Durrett
Large language models (LLMs) are increasingly being used to synthesize and reason about source code. However, the static nature of these models' knowledge does not reflect the fact that libraries and API functions they invoke are continuously evolving, with functionality being added or changing. While numerous benchmarks evaluate how LLMs can generate code, no prior work has studied how an LLMs' knowledge about code API functions can be updated. To fill this gap, we present CodeUpdateArena, a benchmark for knowledge editing in the code domain. An instance in our benchmark consists of a synthetic API function update paired with a program synthesis example that uses the updated functionality; our goal is to update an LLM to be able to solve this program synthesis example without providing documentation of the update at inference time. Compared to knowledge editing for facts encoded in text, success here is more challenging: a code LLM must correctly reason about the semantics of the modified function rather than just reproduce its syntax. Our dataset is constructed by first prompting GPT-4 to generate atomic and executable function updates. Then, for each update, we generate program synthesis examples whose code solutions are prone to use the update. Our benchmark covers updates of various types to 54 functions from seven diverse Python packages, with a total of 670 program synthesis examples. Our experiments show that prepending documentation of the update to open-source code LLMs (i.e., DeepSeek, CodeLlama) does not allow them to incorporate changes for problem solving, and existing knowledge editing techniques also have substantial room for improvement. We hope our benchmark will inspire new methods for knowledge updating in code LLMs.
Read more7/10/2024

0
LeKUBE: A Legal Knowledge Update BEnchmark
Changyue Wang, Weihang Su, Hu Yiran, Qingyao Ai, Yueyue Wu, Cheng Luo, Yiqun Liu, Min Zhang, Shaoping Ma
Recent advances in Large Language Models (LLMs) have significantly shaped the applications of AI in multiple fields, including the studies of legal intelligence. Trained on extensive legal texts, including statutes and legal documents, the legal LLMs can capture important legal knowledge/concepts effectively and provide important support for downstream legal applications such as legal consultancy. Yet, the dynamic nature of legal statutes and interpretations also poses new challenges to the use of LLMs in legal applications. Particularly, how to update the legal knowledge of LLMs effectively and efficiently has become an important research problem in practice. Existing benchmarks for evaluating knowledge update methods are mostly designed for the open domain and cannot address the specific challenges of the legal domain, such as the nuanced application of new legal knowledge, the complexity and lengthiness of legal regulations, and the intricate nature of legal reasoning. To address this gap, we introduce the Legal Knowledge Update BEnchmark, i.e. LeKUBE, which evaluates knowledge update methods for legal LLMs across five dimensions. Specifically, we categorize the needs of knowledge updates in the legal domain with the help of legal professionals, and then hire annotators from law schools to create synthetic updates to the Chinese Criminal and Civil Code as well as sets of questions of which the answers would change after the updates. Through a comprehensive evaluation of state-of-the-art knowledge update methods, we reveal a notable gap between existing knowledge update methods and the unique needs of the legal domain, emphasizing the need for further research and development of knowledge update mechanisms tailored for legal LLMs.
Read more7/22/2024
🔮
0
Learning Performance-Improving Code Edits
Alexander Shypula, Aman Madaan, Yimeng Zeng, Uri Alon, Jacob Gardner, Milad Hashemi, Graham Neubig, Parthasarathy Ranganathan, Osbert Bastani, Amir Yazdanbakhsh
With the decline of Moore's law, optimizing program performance has become a major focus of software research. However, high-level optimizations such as API and algorithm changes remain elusive due to the difficulty of understanding the semantics of code. Simultaneously, pretrained large language models (LLMs) have demonstrated strong capabilities at solving a wide range of programming tasks. To that end, we introduce a framework for adapting LLMs to high-level program optimization. First, we curate a dataset of performance-improving edits made by human programmers of over 77,000 competitive C++ programming submission pairs, accompanied by extensive unit tests. A major challenge is the significant variability of measuring performance on commodity hardware, which can lead to spurious improvements. To isolate and reliably evaluate the impact of program optimizations, we design an environment based on the gem5 full system simulator, the de facto simulator used in academia and industry. Next, we propose a broad range of adaptation strategies for code optimization; for prompting, these include retrieval-based few-shot prompting and chain-of-thought, and for finetuning, these include performance-conditioned generation and synthetic data augmentation based on self-play. A combination of these techniques achieves a mean speedup of 6.86 with eight generations, higher than average optimizations from individual programmers (3.66). Using our model's fastest generations, we set a new upper limit on the fastest speedup possible for our dataset at 9.64 compared to using the fastest human submissions available (9.56).
Read more4/29/2024
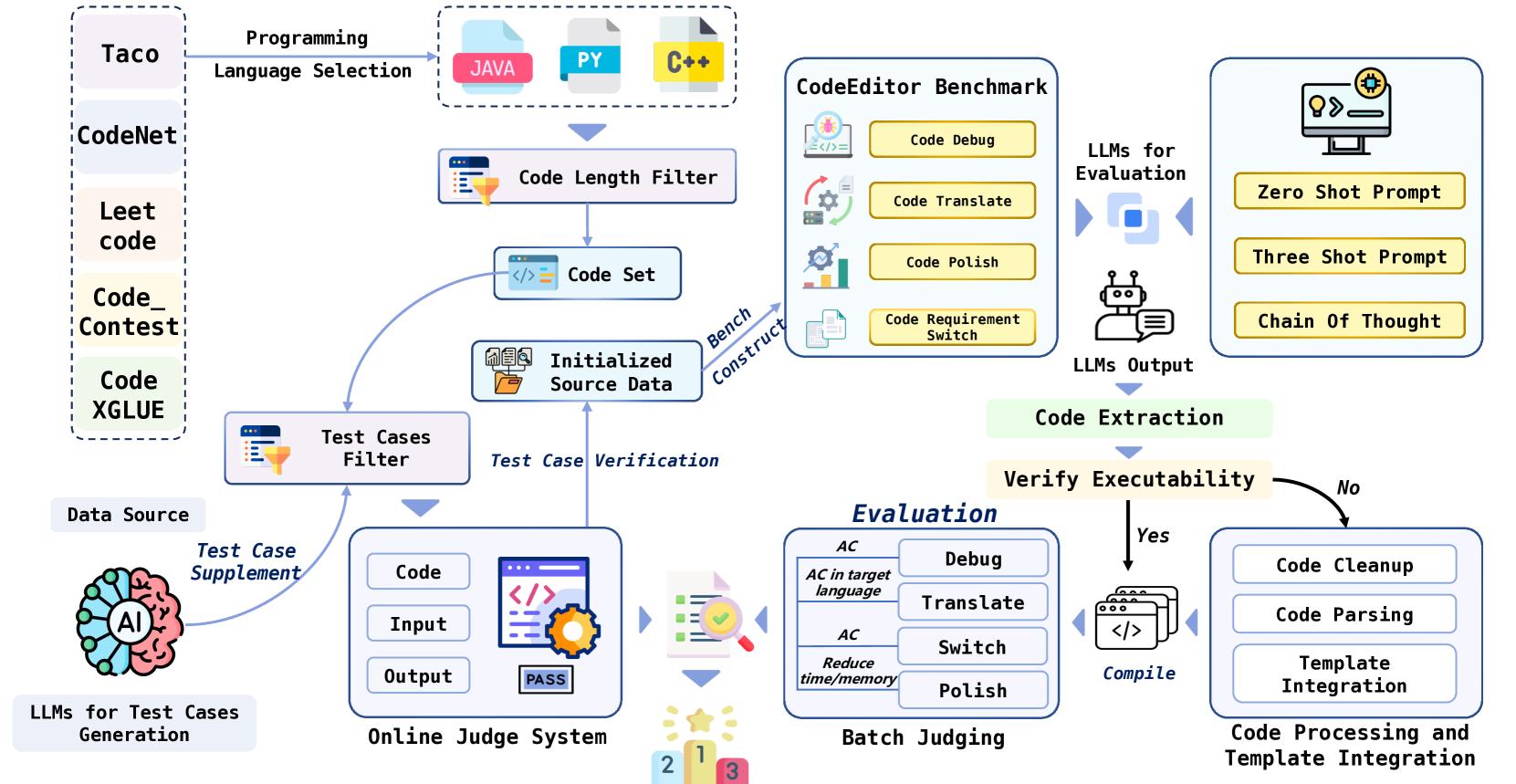
0
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
Read more4/9/2024