Is Your LLM Outdated? Benchmarking LLMs & Alignment Algorithms for Time-Sensitive Knowledge
2404.08700
0
0
Abstract
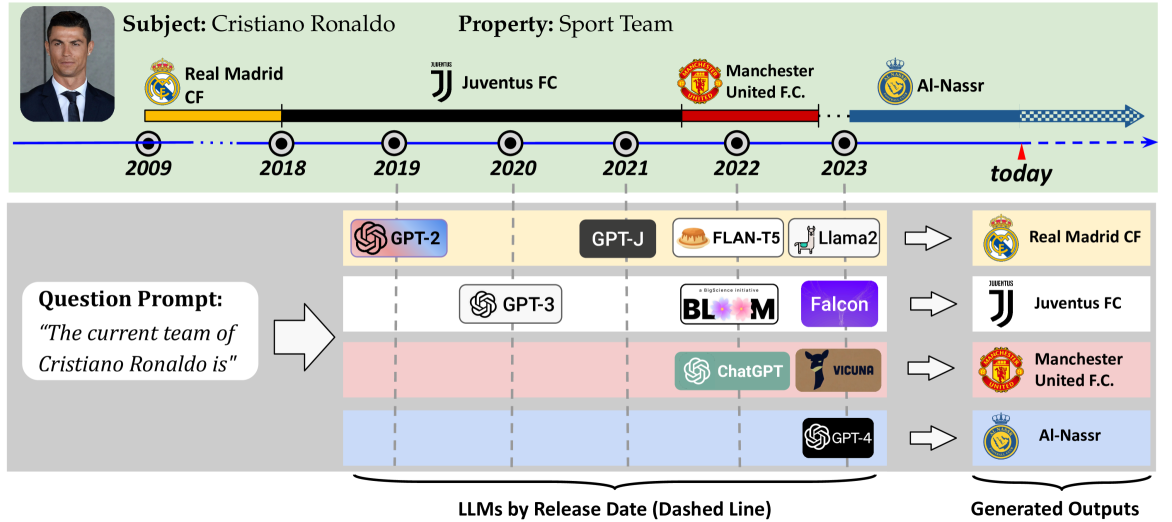
LLMs acquire knowledge from massive data snapshots collected at different timestamps. Their knowledge is then commonly evaluated using static benchmarks. However, factual knowledge is generally subject to time-sensitive changes, and static benchmarks cannot address those cases. We present an approach to dynamically evaluate the knowledge in LLMs and their time-sensitiveness against Wikidata, a publicly available up-to-date knowledge graph. We evaluate the time-sensitive knowledge in twenty-four private and open-source LLMs, as well as the effectiveness of four editing methods in updating the outdated facts. Our results show that 1) outdatedness is a critical problem across state-of-the-art LLMs; 2) LLMs output inconsistent answers when prompted with slight variations of the question prompt; and 3) the performance of the state-of-the-art knowledge editing algorithms is very limited, as they can not reduce the cases of outdatedness and output inconsistency.
Create account to get full access
Overview
- This paper investigates the issue of maintaining up-to-date knowledge in large language models (LLMs) over time.
- It introduces a new benchmark called DyKnow to evaluate the ability of LLMs to handle time-sensitive information.
- The paper also explores novel alignment algorithms designed to help keep LLMs aligned with evolving knowledge.
Plain English Explanation
As AI systems become more advanced, it's important to ensure they have the most current and accurate information. This paper looks at the challenge of keeping large language models (LLMs) - powerful AI systems that can understand and generate human-like text - up-to-date with the latest knowledge.
The researchers created a new testing framework called DyKnow to evaluate how well LLMs can handle information that changes over time. For example, if an LLM is trained on news articles from 2020, how well can it still answer questions about current events in 2023? DyKnow allows the researchers to measure this type of "temporal knowledge" in LLMs.
The paper also explores new algorithms that could help align LLMs with evolving knowledge. Just like humans need to continuously learn and update their understanding, these alignment techniques aim to keep LLMs synchronized with the latest information in their knowledge base.
By developing better ways to benchmark and maintain the temporal knowledge of LLMs, this research aims to ensure these powerful AI systems remain accurate and relevant over time.
Technical Explanation
The paper introduces a new benchmark called DyKnow ("[https://aimodels.fyi/papers/arxiv/towards-practical-tool-usage-continually-learning-llms]DyKnow: Dynamic Knowledge Benchmark") to evaluate how well large language models (LLMs) can handle time-sensitive information. DyKnow tests an LLM's ability to answer questions about current events, trends, and other time-dependent knowledge.
The authors also explore novel "[https://aimodels.fyi/papers/arxiv/unveiling-llms-evolution-latent-representations-temporal-knowledge]alignment algorithms" designed to keep LLM knowledge synchronized with the real world. These techniques aim to continuously update the LLM's internal representations to match the latest information, similar to how humans update their understanding over time.
The paper builds on prior research in areas like "[https://aimodels.fyi/papers/arxiv/head-to-tail-how-knowledgeable-are-large]measuring LLM knowledge" and "[https://aimodels.fyi/papers/arxiv/unveiling-llm-evaluation-focused-metrics-challenges-solutions]LLM evaluation metrics". It also relates to work on "[https://aimodels.fyi/papers/arxiv/medexpqa-multilingual-benchmarking-large-language-models-medical]evaluating LLMs in specific domains" like medicine.
Critical Analysis
The paper makes a compelling case for the importance of maintaining up-to-date knowledge in LLMs as they become more widely deployed. The DyKnow benchmark provides a valuable new tool for evaluating this critical capability.
However, the paper does not go into detail on the specific methods used to create DyKnow or the alignment algorithms. More information on the technical implementation and validation of these approaches would be helpful for assessing their effectiveness.
Additionally, the paper does not address potential challenges around keeping LLM knowledge aligned with fast-moving, ambiguous, or politically-charged real-world information. These types of knowledge domains may require more sophisticated techniques beyond what is presented here.
Overall, this research highlights an important issue facing the development of reliable and trustworthy AI systems. Continued work in this area will be crucial as LLMs become more influential in our lives.
Conclusion
This paper tackles the crucial problem of ensuring large language models (LLMs) maintain accurate, up-to-date knowledge over time. By introducing the DyKnow benchmark and exploring new alignment algorithms, the researchers are working to address a key limitation of current LLM technology.
As LLMs become more powerful and widely deployed, keeping their knowledge synchronized with the real world will be essential. The techniques explored in this paper represent an important step towards developing LLMs that can reliably provide relevant and temporally-accurate information. Further advancements in this area could have significant implications for the responsible development of transformative AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Evaluating LLMs at Evaluating Temporal Generalization
Chenghao Zhu, Nuo Chen, Yufei Gao, Benyou Wang
0
0
The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.
5/15/2024
🧠
Towards a Holistic Evaluation of LLMs on Factual Knowledge Recall
Jiaqing Yuan, Lin Pan, Chung-Wei Hang, Jiang Guo, Jiarong Jiang, Bonan Min, Patrick Ng, Zhiguo Wang
0
0
Large language models (LLMs) have shown remarkable performance on a variety of NLP tasks, and are being rapidly adopted in a wide range of use cases. It is therefore of vital importance to holistically evaluate the factuality of their generated outputs, as hallucinations remain a challenging issue. In this work, we focus on assessing LLMs' ability to recall factual knowledge learned from pretraining, and the factors that affect this ability. To that end, we construct FACT-BENCH, a representative benchmark covering 20 domains, 134 property types, 3 answer types, and different knowledge popularity levels. We benchmark 31 models from 10 model families and provide a holistic assessment of their strengths and weaknesses. We observe that instruction-tuning hurts knowledge recall, as pretraining-only models consistently outperform their instruction-tuned counterparts, and positive effects of model scaling, as larger models outperform smaller ones for all model families. However, the best performance from GPT-4 still represents a large gap with the upper-bound. We additionally study the role of in-context exemplars using counterfactual demonstrations, which lead to significant degradation of factual knowledge recall for large models. By further decoupling model known and unknown knowledge, we find the degradation is attributed to exemplars that contradict a model's known knowledge, as well as the number of such exemplars. Lastly, we fine-tune LLaMA-7B in different settings of known and unknown knowledge. In particular, fine-tuning on a model's known knowledge is beneficial, and consistently outperforms fine-tuning on unknown and mixed knowledge. We will make our benchmark publicly available.
4/26/2024
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, Bryan Perozzi
0
0
Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
6/14/2024
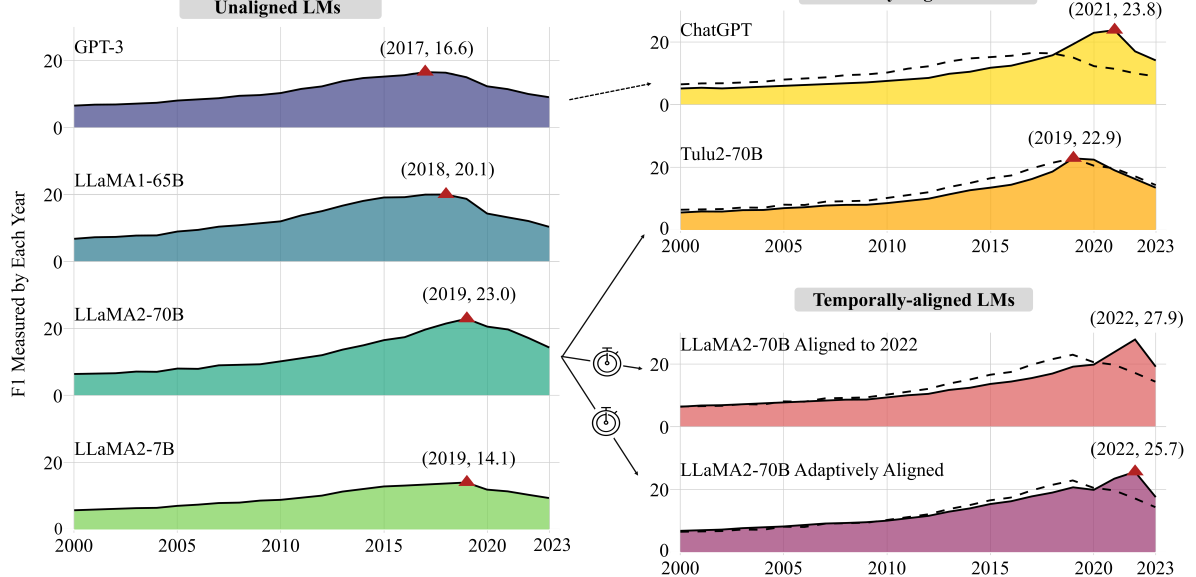
Set the Clock: Temporal Alignment of Pretrained Language Models
Bowen Zhao, Zander Brumbaugh, Yizhong Wang, Hannaneh Hajishirzi, Noah A. Smith
0
0
Language models (LMs) are trained on web text originating from many points in time and, in general, without any explicit temporal grounding. This work investigates the temporal chaos of pretrained LMs and explores various methods to align their internal knowledge to a target time, which we call temporal alignment. To do this, we first automatically construct a dataset containing 20K time-sensitive questions and their answers for each year from 2000 to 2023. Based on this dataset, we empirically show that pretrained LMs (e.g., LLaMa2), despite having a recent pretraining cutoff (e.g., 2022), mostly answer questions using earlier knowledge (e.g., in 2019). We then develop several methods, from prompting to finetuning, to align LMs to use their most recent knowledge when answering questions, and investigate various factors in this alignment. Our experiments demonstrate that aligning LLaMa2 to the year 2022 can enhance its performance by up to 62% according to that year's answers. This improvement occurs even without explicitly mentioning time information, indicating the possibility of aligning models' internal sense of time after pretraining. Finally, we find that alignment to a historical time is also possible, with up to 2.8$times$ the performance of the unaligned LM in 2010 if finetuning models to that year. These findings hint at the sophistication of LMs' internal knowledge organization and the necessity of tuning them properly.
6/11/2024