Length Desensitization in Directed Preference Optimization

0

Sign in to get full access
Overview
- This paper explores the challenge of length desensitization in directed preference optimization, a machine learning technique used to generate desired outputs.
- The authors propose approaches to address the issue of models becoming overly focused on output length at the expense of quality.
- Key insights include methods to disentangle length from quality in the optimization process and ways to regularize length while preserving the desired properties of the outputs.
Plain English Explanation
When training machine learning models to generate specific types of outputs, such as text or images, there is often a tendency for the models to become overly focused on the length of the outputs rather than their quality or desired properties. This is known as the length desensitization problem in directed preference optimization.
The authors of this paper propose several approaches to address this issue. One key idea is to disentangle length from quality in the optimization process, so the model is not as heavily influenced by the length of the outputs. They also explore iterative length regularization, where the model is incentivized to produce outputs of the desired length while still preserving important qualities.
By tackling the length desensitization problem, the researchers aim to improve the ability of these machine learning systems to generate high-quality, meaningful outputs that align with the intended goals, rather than simply optimizing for length. This has important implications for a wide range of applications, from language modeling to creative content generation.
Technical Explanation
The paper begins by introducing the problem of length desensitization in the context of directed preference optimization, where models can become overly focused on output length at the expense of other desired properties.
The authors then provide preliminary background on directed preference optimization and the challenges of length desensitization. They discuss how existing approaches often struggle to effectively balance length and quality considerations.
To address these issues, the paper proposes several novel techniques:
- Disentangling Length from Quality: The authors present methods to separate the model's understanding of length from its understanding of quality, allowing for more nuanced optimization.
- Iterative Length Regularization: This approach introduces length-based regularization terms that encourage the model to produce outputs of the desired length while still preserving important qualities.
- Eliminating Biased Length Reliance: The researchers explore ways to reduce the model's inherent tendency to rely on length as a proxy for quality.
Through detailed experiments and analysis, the paper demonstrates the effectiveness of these techniques in improving the quality of outputs while better controlling for length considerations.
Critical Analysis
The paper acknowledges several limitations and areas for further research:
- The proposed methods may not fully address the underlying biases that lead to length desensitization, and more fundamental architectural or training changes may be required.
- The techniques are evaluated on a limited set of tasks and datasets, and their performance may vary across different application domains.
- The paper does not explore the potential unintended consequences or ethical implications of these length optimization methods, which could be an important area for future work.
Additionally, one could question whether the focus on length is truly the core issue, or if there are deeper challenges in aligning machine learning models with human preferences and values that need to be addressed.
Conclusion
This paper presents novel approaches to tackling the length desensitization problem in directed preference optimization, a significant challenge in the development of high-quality, goal-oriented machine learning systems. By disentangling length from quality and introducing iterative length regularization, the researchers have made important progress in enabling these models to generate outputs that better match the intended objectives.
The insights and techniques outlined in this work have the potential to enhance a wide range of applications, from language generation to content creation, where the ability to control output characteristics while preserving desired qualities is crucial. As the field of machine learning continues to advance, addressing issues like length desensitization will be essential for developing systems that can reliably and responsibly assist and empower human users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Length Desensitization in Directed Preference Optimization
Wei Liu, Yang Bai, Chengcheng Han, Rongxiang Weng, Jun Xu, Xuezhi Cao, Jingang Wang, Xunliang Cai
Direct Preference Optimization (DPO) is widely utilized in the Reinforcement Learning from Human Feedback (RLHF) phase to align Large Language Models (LLMs) with human preferences, thereby enhancing both their harmlessness and efficacy. However, it has been observed that DPO tends to over-optimize for verbosity, which can detrimentally affect both performance and user experience. In this paper, we conduct an in-depth theoretical analysis of DPO's optimization objective and reveal a strong correlation between its implicit reward and data length. This correlation misguides the optimization direction, resulting in length sensitivity during the DPO training and leading to verbosity. To address this issue, we propose a length-desensitization improvement method for DPO, termed LD-DPO. The proposed method aims to desensitize DPO to data length by decoupling explicit length preference, which is relatively insignificant, from the other implicit preferences, thereby enabling more effective learning of the intrinsic preferences. We utilized two settings (Base and Instruct) of Llama2-13B, Llama3-8B, and Qwen2-7B for experimental validation on various benchmarks including MT-Bench and AlpacaEval 2. The experimental results indicate that LD-DPO consistently outperforms DPO and other baseline methods, achieving more concise responses with a 10-40% reduction in length compared to DPO. We conducted in-depth experimental analyses to demonstrate that LD-DPO can indeed achieve length desensitization and align the model more closely with human-real preferences.
Read more9/11/2024

0
Disentangling Length from Quality in Direct Preference Optimization
Ryan Park, Rafael Rafailov, Stefano Ermon, Chelsea Finn
Reinforcement Learning from Human Feedback (RLHF) has been a crucial component in the recent success of Large Language Models. However, RLHF is know to exploit biases in human preferences, such as verbosity. A well-formatted and eloquent answer is often more highly rated by users, even when it is less helpful and objective. A number of approaches have been developed to control those biases in the classical RLHF literature, but the problem remains relatively under-explored for Direct Alignment Algorithms such as Direct Preference Optimization (DPO). Unlike classical RLHF, DPO does not train a separate reward model or use reinforcement learning directly, so previous approaches developed to control verbosity cannot be directly applied to this setting. Our work makes several contributions. For the first time, we study the length problem in the DPO setting, showing significant exploitation in DPO and linking it to out-of-distribution bootstrapping. We then develop a principled but simple regularization strategy that prevents length exploitation, while still maintaining improvements in model quality. We demonstrate these effects across datasets on summarization and dialogue, where we achieve up to 20% improvement in win rates when controlling for length, despite the GPT4 judge's well-known verbosity bias.
Read more9/10/2024
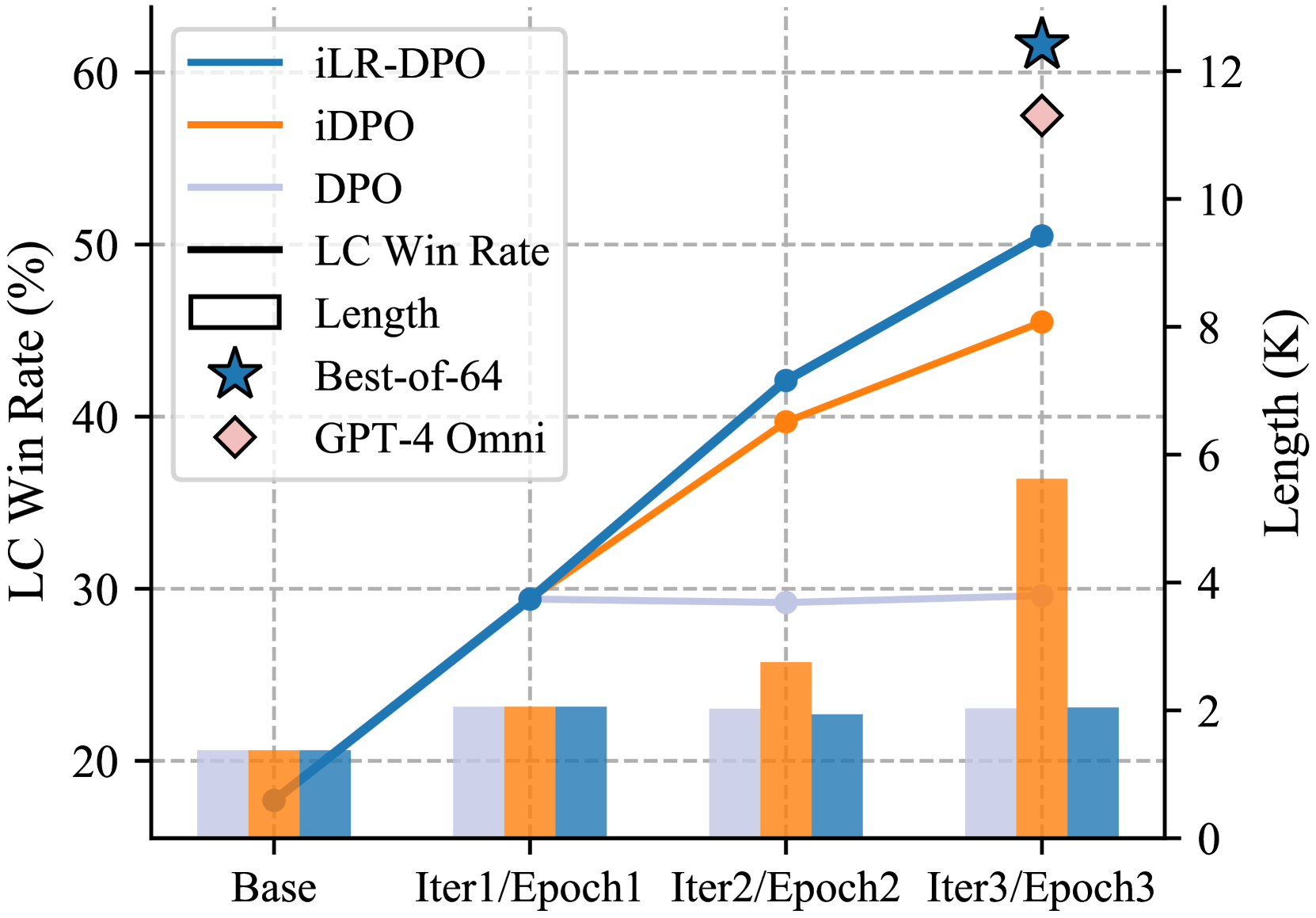
0
Iterative Length-Regularized Direct Preference Optimization: A Case Study on Improving 7B Language Models to GPT-4 Level
Jie Liu, Zhanhui Zhou, Jiaheng Liu, Xingyuan Bu, Chao Yang, Han-Sen Zhong, Wanli Ouyang
Direct Preference Optimization (DPO), a standard method for aligning language models with human preferences, is traditionally applied to offline preferences. Recent studies show that DPO benefits from iterative training with online preferences labeled by a trained reward model. In this work, we identify a pitfall of vanilla iterative DPO - improved response quality can lead to increased verbosity. To address this, we introduce iterative length-regularized DPO (iLR-DPO) to penalize response length. Our empirical results show that iLR-DPO can enhance a 7B model to perform on par with GPT-4 without increasing verbosity. Specifically, our 7B model achieves a $50.5%$ length-controlled win rate against $texttt{GPT-4 Preview}$ on AlpacaEval 2.0, and excels across standard benchmarks including MT-Bench, Arena-Hard and OpenLLM Leaderboard. These results demonstrate the effectiveness of iterative DPO in aligning language models with human feedback.
Read more6/18/2024

0
New Desiderata for Direct Preference Optimization
Xiangkun Hu, Tong He, David Wipf
Large language models in the past have typically relied on some form of reinforcement learning with human feedback (RLHF) to better align model responses with human preferences. However, because of oft-observed instabilities when implementing these RLHF pipelines, various reparameterization techniques have recently been introduced to sidestep the need for separately learning an RL reward model. Instead, directly fine-tuning for human preferences is achieved via the minimization of a single closed-form training objective, a process originally referred to as direct preference optimization (DPO) and followed by several notable descendants. Although effective in certain real-world settings, we introduce new evaluation criteria that serve to highlight unresolved shortcomings in the ability of existing DPO methods to interpolate between a pre-trained reference model and empirical measures of human preferences, as well as unavoidable trade-offs in how low- and high-quality responses are regularized and constraints are handled. Our insights then motivate an alternative DPO-like loss that provably mitigates these limitations. Empirical results serve to corroborate notable aspects of our analyses.
Read more7/15/2024