Less is more: Summarizing Patch Tokens for efficient Multi-Label Class-Incremental Learning

0
Sign in to get full access
Overview
- This research paper introduces a method for efficient multi-label class-incremental learning using summarized patch tokens.
- The key idea is to use a patch token summarization module to reduce the size of the input representation, which can improve the efficiency of multi-label classification models.
- The paper evaluates the proposed approach on several benchmark datasets and demonstrates its advantages over existing methods in terms of accuracy and computational efficiency.
Plain English Explanation
In machine learning, multi-label classification is a task where an object can belong to multiple classes at the same time. For example, an image might contain multiple objects (e.g., a dog, a ball, and a person). Class-incremental learning is a setting where new classes are added over time, and the model needs to learn to recognize them without forgetting the previous ones.
The researchers in this paper propose a method to make multi-label class-incremental learning more efficient. Their key insight is that not all the information in the input (e.g., an image) is equally important for classification. They introduce a patch token summarization module that can distill the most relevant information from the input into a more compact representation.
By using this summarized representation, the classification model can be more efficient, requiring less memory and computation. The researchers show that their approach outperforms existing methods on standard multi-label classification benchmarks, achieving higher accuracy while being more computationally efficient.
This work is relevant for Prompt-Tuned Embedding Classification for Multi-Label Industry, Convolutional Prompting Meets Language Models for Continual Learning, Multi-Prompt Depth-Partitioned Cross-Modal Learning, Plug and Play Prompts: A Prompt-Tuning Approach to Controlling, and SEP: Self-Enhanced Prompt Tuning for Visual-Language as they all explore efficient and effective ways to tackle multi-label classification and continual learning problems.
Technical Explanation
The researchers propose a method called Summarized Patch Tokens (SPT) for efficient multi-label class-incremental learning. The key components of their approach are:
-
Patch Token Summarization Module: This module takes the input (e.g., an image) and summarizes the patch tokens into a more compact representation. The summarization is done using a transformer-based network that learns to distill the most relevant information.
-
Multi-Label Classifier: The summarized patch tokens are then fed into a multi-label classification model, which predicts the presence or absence of each class in the input.
-
Class-Incremental Learning: To handle new classes added over time, the researchers use a distillation loss to ensure the model does not forget previous classes while learning new ones.
The researchers evaluate their approach on several multi-label classification datasets, including MS-COCO, Pascal VOC, and NUS-WIDE. They compare their method to various baselines and state-of-the-art approaches, and show that SPT achieves higher accuracy while being more computationally efficient.
The key insights from this research are:
- Patch Token Summarization: Reducing the input size through token summarization can improve the efficiency of multi-label classification models without sacrificing accuracy.
- Class-Incremental Learning: The distillation loss helps the model learn new classes while retaining knowledge of previous ones, enabling effective continual learning.
Critical Analysis
The researchers have provided a thorough evaluation of their proposed method, and the results demonstrate the benefits of their approach. However, there are a few potential limitations and areas for further research:
-
Generalization to Other Domains: The evaluation is primarily focused on image classification tasks. It would be valuable to investigate the performance of the SPT method on other multi-label domains, such as text or multi-modal data.
-
Interpretability: The paper does not provide much insight into how the patch token summarization module works and what information it is capturing. Incorporating more interpretability could help understand the inner workings of the model and potentially lead to further improvements.
-
Computational Complexity: While the researchers show that SPT is more computationally efficient than baseline methods, the complexity of the patch token summarization module itself is not discussed in detail. It would be useful to understand the scalability of this component as the input size or number of classes increases.
-
Ablation Studies: The paper could benefit from more extensive ablation studies to understand the individual contributions of the different components of the proposed approach, such as the patch token summarization and the distillation loss.
Despite these potential areas for improvement, the research presented in this paper is a valuable contribution to the field of efficient multi-label class-incremental learning. The use of patch token summarization is a promising direction that could inspire further advancements in this area.
Conclusion
This research paper introduces a novel method called Summarized Patch Tokens (SPT) for efficient multi-label class-incremental learning. The key idea is to use a patch token summarization module to reduce the size of the input representation, which can improve the computational efficiency of the multi-label classification model without sacrificing accuracy.
The researchers demonstrate the effectiveness of their approach on several benchmark datasets, showing that SPT outperforms existing methods in terms of both accuracy and efficiency. This work is relevant for a range of applications, from Prompt-Tuned Embedding Classification for Multi-Label Industry to Convolutional Prompting Meets Language Models for Continual Learning, as it provides a promising solution for efficient multi-label classification and continual learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Less is more: Summarizing Patch Tokens for efficient Multi-Label Class-Incremental Learning
Thomas De Min, Massimiliano Mancini, St'ephane Lathuili`ere, Subhankar Roy, Elisa Ricci
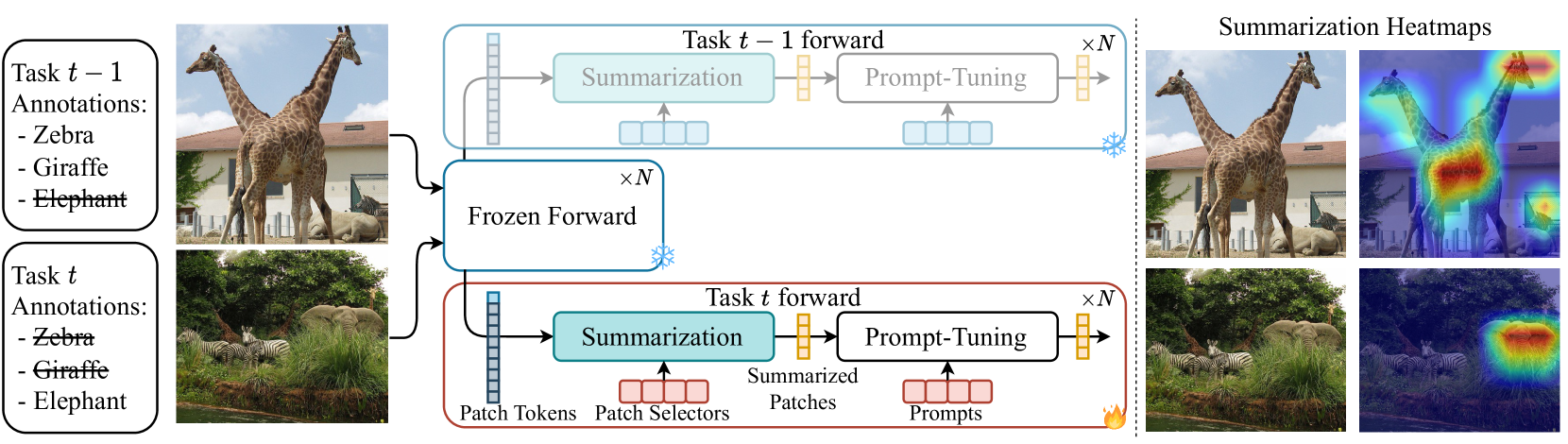
Prompt tuning has emerged as an effective rehearsal-free technique for class-incremental learning (CIL) that learns a tiny set of task-specific parameters (or prompts) to instruct a pre-trained transformer to learn on a sequence of tasks. Albeit effective, prompt tuning methods do not lend well in the multi-label class incremental learning (MLCIL) scenario (where an image contains multiple foreground classes) due to the ambiguity in selecting the correct prompt(s) corresponding to different foreground objects belonging to multiple tasks. To circumvent this issue we propose to eliminate the prompt selection mechanism by maintaining task-specific pathways, which allow us to learn representations that do not interact with the ones from the other tasks. Since independent pathways in truly incremental scenarios will result in an explosion of computation due to the quadratically complex multi-head self-attention (MSA) operation in prompt tuning, we propose to reduce the original patch token embeddings into summarized tokens. Prompt tuning is then applied to these fewer summarized tokens to compute the final representation. Our proposed method Multi-Label class incremental learning via summarising pAtch tokeN Embeddings (MULTI-LANE) enables learning disentangled task-specific representations in MLCIL while ensuring fast inference. We conduct experiments in common benchmarks and demonstrate that our MULTI-LANE achieves a new state-of-the-art in MLCIL. Additionally, we show that MULTI-LANE is also competitive in the CIL setting. Source code available at https://github.com/tdemin16/multi-lane
Read more5/27/2024

0
Enhancing Few-Shot Transfer Learning with Optimized Multi-Task Prompt Tuning through Modular Prompt Composition
Ahmad Pouramini, Hesham Faili
In recent years, multi-task prompt tuning has garnered considerable attention for its inherent modularity and potential to enhance parameter-efficient transfer learning across diverse tasks. This paper aims to analyze and improve the performance of multiple tasks by facilitating the transfer of knowledge between their corresponding prompts in a multi-task setting. Our proposed approach decomposes the prompt for each target task into a combination of shared prompts (source prompts) and a task-specific prompt (private prompt). During training, the source prompts undergo fine-tuning and are integrated with the private prompt to drive the target prompt for each task. We present and compare multiple methods for combining source prompts to construct the target prompt, analyzing the roles of both source and private prompts within each method. We investigate their contributions to task performance and offer flexible, adjustable configurations based on these insights to optimize performance. Our empirical findings clearly showcase improvements in accuracy and robustness compared to the conventional practice of prompt tuning and related works. Notably, our results substantially outperform other methods in the field in few-shot settings, demonstrating superior performance in various tasks across GLUE benchmark, among other tasks. This achievement is attained with a significantly reduced amount of training data, making our method a promising one for few-shot settings.
Read more8/26/2024
👀
0
Patch-Prompt Aligned Bayesian Prompt Tuning for Vision-Language Models
Xinyang Liu, Dongsheng Wang, Bowei Fang, Miaoge Li, Zhibin Duan, Yishi Xu, Bo Chen, Mingyuan Zhou
For downstream applications of vision-language pre-trained models, there has been significant interest in constructing effective prompts. Existing works on prompt engineering, which either require laborious manual designs or optimize the prompt tuning as a point estimation problem, may fail to describe diverse characteristics of categories and limit their applications. We introduce a Bayesian probabilistic resolution to prompt tuning, where the label-specific stochastic prompts are generated hierarchically by first sampling a latent vector from an underlying distribution and then employing a lightweight generative model. Importantly, we semantically regularize the tuning process by minimizing the statistical distance between the visual patches and linguistic prompts, which pushes the stochastic label representations to faithfully capture diverse visual concepts, instead of overfitting the training categories. We evaluate the effectiveness of our approach on four tasks: few-shot image recognition, base-to-new generalization, dataset transfer learning, and domain shifts. Extensive results over 15 datasets show promising transferability and generalization performance of our proposed model, both quantitatively and qualitatively.
Read more7/2/2024
🏷️
0
Prompt Tuned Embedding Classification for Multi-Label Industry Sector Allocation
Valentin Leonhard Buchner, Lele Cao, Jan-Christoph Kalo, Vilhelm von Ehrenheim
Prompt Tuning is emerging as a scalable and cost-effective method to fine-tune Pretrained Language Models (PLMs), which are often referred to as Large Language Models (LLMs). This study benchmarks the performance and computational efficiency of Prompt Tuning and baselines for multi-label text classification. This is applied to the challenging task of classifying companies into an investment firm's proprietary industry taxonomy, supporting their thematic investment strategy. Text-to-text classification is frequently reported to outperform task-specific classification heads, but has several limitations when applied to a multi-label classification problem where each label consists of multiple tokens: (a) Generated labels may not match any label in the label taxonomy; (b) The fine-tuning process lacks permutation invariance and is sensitive to the order of the provided labels; (c) The model provides binary decisions rather than appropriate confidence scores. Limitation (a) is addressed by applying constrained decoding using Trie Search, which slightly improves classification performance. All limitations (a), (b), and (c) are addressed by replacing the PLM's language head with a classification head, which is referred to as Prompt Tuned Embedding Classification (PTEC). This improves performance significantly, while also reducing computational costs during inference. In our industrial application, the training data is skewed towards well-known companies. We confirm that the model's performance is consistent across both well-known and less-known companies. Our overall results indicate the continuing need to adapt state-of-the-art methods to domain-specific tasks, even in the era of PLMs with strong generalization abilities. We release our codebase and a benchmarking dataset at https://github.com/EQTPartners/PTEC.
Read more4/15/2024