Lessons Learned from a Unifying Empirical Study of Parameter-Efficient Transfer Learning (PETL) in Visual Recognition

0

Sign in to get full access
Overview
- The paper presents a unifying empirical study of parameter-efficient transfer learning (PETL) methods in visual recognition tasks.
- PETL methods aim to achieve high performance with fewer trainable parameters compared to full fine-tuning.
- The study evaluates the performance and efficiency of various PETL approaches across different vision transformer models and datasets.
Plain English Explanation
The paper looks at a group of machine learning techniques called "parameter-efficient transfer learning" (PETL) and how well they work for visual recognition tasks. PETL methods try to get good results with fewer trainable parameters compared to fully retraining a model from scratch.
The researchers evaluated the performance and efficiency of various PETL approaches using different vision transformer models and datasets. Vision transformers are a type of neural network that can recognize objects and scenes in images.
The key idea behind PETL is to reuse parts of a pre-trained model instead of training everything from the beginning. This can make the process more parameter-efficient and memory-efficient. The paper investigates how well different PETL methods perform compared to fully retraining the models.
Technical Explanation
The paper conducts a comprehensive empirical study of parameter-efficient transfer learning (PETL) approaches for visual recognition tasks. PETL aims to achieve high performance with fewer trainable parameters compared to full fine-tuning.
The study evaluates various PETL methods, including:
- Prompt Tuning: Optimizing a small set of prompt tokens while freezing the backbone model.
- Adapter Tuning: Adding lightweight adapter modules to the backbone model.
- Prefix Tuning: Optimizing a continuous prefix to the input while freezing the backbone.
- BitFit: Tuning only the bias terms of the backbone model.
These PETL techniques are compared across different vision transformer models (ViT, DeiT, Swin Transformer) and datasets (ImageNet, CIFAR-100, iNaturalist). The experiments measure the performance, parameter efficiency, and training time of the PETL approaches.
The results show that PETL methods can achieve competitive accuracy compared to full fine-tuning, while using significantly fewer trainable parameters. The paper also provides insights into the strengths and weaknesses of the different PETL techniques in various settings.
Critical Analysis
The paper provides a thorough and unbiased evaluation of PETL methods for visual recognition. It acknowledges that the performance of PETL can be dataset and model-dependent, and encourages readers to critically evaluate the trade-offs between parameter efficiency and accuracy for their specific use cases.
One potential limitation is that the study is focused on vision transformer models and may not generalize as well to other model architectures. Additionally, the paper does not deeply explore the underlying reasons for the performance differences between PETL techniques, which could be an area for further research.
While the paper is technically sound, it would benefit from a more accessible presentation of the results and insights to a broader audience. The use of technical jargon and lack of visual aids may make it challenging for non-experts to fully appreciate the significance of the findings.
Conclusion
This paper presents a comprehensive empirical study of parameter-efficient transfer learning (PETL) methods for visual recognition tasks. The results demonstrate that PETL techniques can achieve competitive performance with significantly fewer trainable parameters compared to full fine-tuning.
The insights from this research can inform the development of more efficient and practical machine learning models, particularly in domains with limited compute resources or data. The paper encourages readers to carefully consider the trade-offs between parameter efficiency and accuracy when selecting PETL approaches for their specific applications.
Overall, this study advances our understanding of how to effectively leverage pre-trained models and transfer learning to build high-performing yet parameter-efficient computer vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lessons Learned from a Unifying Empirical Study of Parameter-Efficient Transfer Learning (PETL) in Visual Recognition
Zheda Mai, Ping Zhang, Cheng-Hao Tu, Hong-You Chen, Li Zhang, Wei-Lun Chao
Parameter-efficient transfer learning (PETL) has attracted significant attention lately, due to the increasing size of pre-trained models and the need to fine-tune (FT) them for superior downstream performance. This community-wide enthusiasm has sparked a plethora of approaches. Nevertheless, a systematic study to understand their performance and suitable application scenarios is lacking, leaving questions like when to apply PETL and which approach to use largely unanswered. In this paper, we conduct a unifying empirical study of representative PETL methods in the context of Vision Transformers. We systematically tune their hyper-parameters to fairly compare their accuracy on downstream tasks. Our study not only offers a valuable user guide but also unveils several new insights. First, if tuned carefully, different PETL methods can obtain similar accuracy in the low-shot benchmark VTAB-1K. This includes simple methods like FT the bias terms that were reported inferior. Second, though with similar accuracy, we find that PETL methods make different mistakes and high-confidence predictions, likely due to their different inductive biases. Such an inconsistency (or complementariness) opens up the opportunity for ensemble methods, and we make preliminary attempts at this. Third, going beyond the commonly used low-shot tasks, we find that PETL is also useful in many-shot regimes -- it achieves comparable and sometimes better accuracy than full FT, using much fewer learnable parameters. Last but not least, we investigate PETL's ability to preserve a pre-trained model's robustness to distribution shifts (e.g., a CLIP backbone). Perhaps not surprisingly, PETL methods outperform full FT alone. However, with weight-space ensembles, the fully fine-tuned model can better balance target (i.e., downstream) distribution and distribution shift performance, suggesting a future research direction for PETL.
Read more10/3/2024

0
Parameter-Efficient and Memory-Efficient Tuning for Vision Transformer: A Disentangled Approach
Taolin Zhang, Jiawang Bai, Zhihe Lu, Dongze Lian, Genping Wang, Xinchao Wang, Shu-Tao Xia
Recent works on parameter-efficient transfer learning (PETL) show the potential to adapt a pre-trained Vision Transformer to downstream recognition tasks with only a few learnable parameters. However, since they usually insert new structures into the pre-trained model, entire intermediate features of that model are changed and thus need to be stored to be involved in back-propagation, resulting in memory-heavy training. We solve this problem from a novel disentangled perspective, i.e., dividing PETL into two aspects: task-specific learning and pre-trained knowledge utilization. Specifically, we synthesize the task-specific query with a learnable and lightweight module, which is independent of the pre-trained model. The synthesized query equipped with task-specific knowledge serves to extract the useful features for downstream tasks from the intermediate representations of the pre-trained model in a query-only manner. Built upon these features, a customized classification head is proposed to make the prediction for the input sample. lightweight architecture and avoids the use of heavy intermediate features for running gradient descent, it demonstrates limited memory usage in training. Extensive experiments manifest that our method achieves state-of-the-art performance under memory constraints, showcasing its applicability in real-world situations.
Read more7/16/2024

0
Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers
Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti, Mirco Ravanelli
Parameter-efficient transfer learning (PETL) methods have emerged as a solid alternative to the standard full fine-tuning approach. They only train a few extra parameters for each downstream task, without sacrificing performance and dispensing with the issue of storing a copy of the pre-trained model for each task. For audio classification tasks, the Audio Spectrogram Transformer (AST) model shows impressive results. However, surprisingly, how to efficiently adapt it to several downstream tasks has not been tackled before. In this paper, we bridge this gap and present a detailed investigation of common PETL methods for the adaptation of the AST model to audio/speech tasks. Furthermore, we propose a new adapter design that exploits the convolution module of the Conformer model, leading to superior performance over the standard PETL approaches and surpassing or achieving performance parity with full fine-tuning by updating only 0.29% of the parameters. Finally, we provide ablation studies revealing that our proposed adapter: 1) proves to be effective in few-shot efficient transfer learning, 2) attains optimal results regardless of the amount of the allocated parameters, and 3) can be applied to other pre-trained models.
Read more7/16/2024
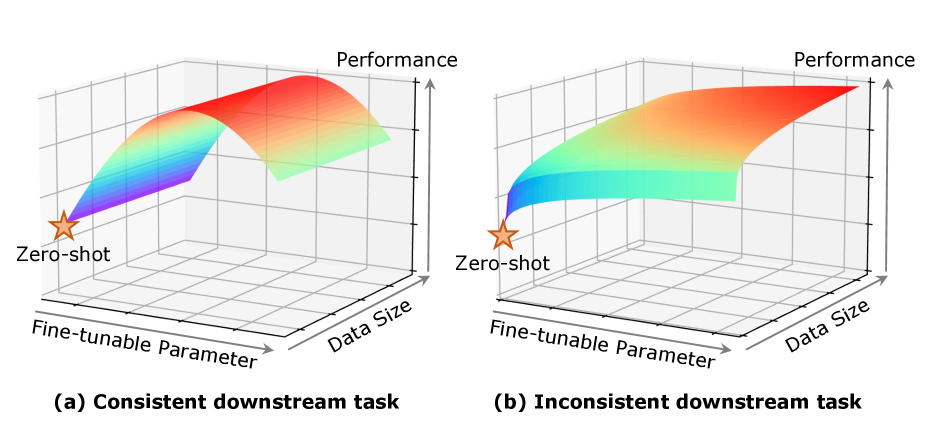
0
An Empirical Study of Parameter Efficient Fine-tuning on Vision-Language Pre-train Model
Yuxin Tian, Mouxing Yang, Yunfan Li, Dayiheng Liu, Xingzhang Ren, Xi Peng, Jiancheng Lv
Recent studies applied Parameter Efficient Fine-Tuning techniques (PEFTs) to efficiently narrow the performance gap between pre-training and downstream. There are two important factors for various PEFTs, namely, the accessible data size and fine-tunable parameter size. A natural expectation for PEFTs is that the performance of various PEFTs is positively related to the data size and fine-tunable parameter size. However, according to the evaluation of five PEFTs on two downstream vision-language (VL) tasks, we find that such an intuition holds only if the downstream data and task are not consistent with pre-training. For downstream fine-tuning consistent with pre-training, data size no longer affects the performance, while the influence of fine-tunable parameter size is not monotonous. We believe such an observation could guide the choice of training strategy for various PEFTs.
Read more5/21/2024