HiDe-PET: Continual Learning via Hierarchical Decomposition of Parameter-Efficient Tuning

0

Sign in to get full access
Overview
- Continual learning: The ability to learn new tasks while retaining knowledge of previous tasks without catastrophic forgetting.
- Parameter-efficient tuning: Techniques that update only a small subset of a pre-trained model's parameters to adapt it to new tasks.
- HiDe-PET: Continual Learning via Hierarchical Decomposition of Parameter-Efficient Tuning: A novel approach that decomposes a pre-trained model hierarchically and updates only a subset of the parameters in a principled manner.
Plain English Explanation
Continual learning is the idea of training an AI system to learn new tasks without forgetting what it has learned before. This is an important challenge, as real-world AI systems often need to adapt to changing circumstances and learn new skills over time.
One approach to continual learning is parameter-efficient tuning, where only a small subset of a pre-trained model's parameters are updated to adapt it to new tasks. This can help prevent catastrophic forgetting, where the model forgets how to perform previous tasks when learning new ones.
The HiDe-PET method takes this idea further by decomposing the pre-trained model hierarchically and updating only a carefully selected subset of the parameters. This allows the model to efficiently learn new tasks while retaining its knowledge of previous ones.
Imagine you're a student who has learned a lot about history, math, and science. When you start a new course in a different subject, like computer programming, you don't want to forget everything you've learned in your other classes. The HiDe-PET approach is like a way of selectively updating only the parts of your brain that are relevant to the new programming course, while leaving the rest of your knowledge intact.
Technical Explanation
The HiDe-PET method builds on previous work in parameter-efficient fine-tuning and continual learning. The key idea is to decompose the pre-trained model's parameters hierarchically and update only a subset of them when learning new tasks.
The method first decomposes the model's parameters into a hierarchy of subspaces, with the most important parameters at the top and less important ones at the lower levels. When learning a new task, the model only updates the parameters in the lower-level subspaces, leaving the more important top-level parameters unchanged. This allows the model to retain its knowledge of previous tasks while efficiently adapting to new ones.
The researchers also introduce a technique called gradient projection, which ensures that the updates to the lower-level parameters do not interfere with the upper-level ones. This helps to further prevent catastrophic forgetting and enables more robust continual learning performance.
The HiDe-PET method is evaluated on a range of continual learning benchmarks, including PEMT, and is shown to outperform previous state-of-the-art approaches in terms of both learning efficiency and the ability to retain knowledge of previous tasks.
Critical Analysis
The HiDe-PET paper presents a strong and principled approach to continual learning, but it is important to consider some potential limitations and areas for further research.
One key question is how the hierarchical decomposition of the model's parameters is determined. The paper describes a method for learning this decomposition, but it is not clear how well this would generalize to different model architectures or task domains. Further research may be needed to understand the robustness and flexibility of this approach.
Additionally, the paper focuses primarily on single-task continual learning, where the model learns a sequence of tasks. It would be interesting to see how the HiDe-PET method would perform in more complex multi-task settings, where the model needs to learn and retain knowledge of multiple tasks simultaneously.
Finally, while the HiDe-PET method demonstrates impressive results, it is important to consider the broader implications of continual learning research. As AI systems become more capable of adapting to new situations, it will be critical to ensure that they do so in a safe and ethical manner, without unintended consequences.
Conclusion
The HiDe-PET method presents a novel and effective approach to continual learning, addressing the challenge of enabling AI systems to learn new tasks without forgetting previous knowledge. By hierarchically decomposing the model's parameters and selectively updating a subset of them, the method is able to efficiently adapt to new situations while maintaining its overall performance.
This research represents an important step forward in the field of continual learning, which is crucial for developing AI systems that can truly learn and evolve over time, just as humans do. As the field continues to progress, it will be important to consider the broader implications and ensure that these advancements are leveraged in a responsible and beneficial manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HiDe-PET: Continual Learning via Hierarchical Decomposition of Parameter-Efficient Tuning
Liyuan Wang, Jingyi Xie, Xingxing Zhang, Hang Su, Jun Zhu
The deployment of pre-trained models (PTMs) has greatly advanced the field of continual learning (CL), enabling positive knowledge transfer and resilience to catastrophic forgetting. To sustain these advantages for sequentially arriving tasks, a promising direction involves keeping the pre-trained backbone frozen while employing parameter-efficient tuning (PET) techniques to instruct representation learning. Despite the popularity of Prompt-based PET for CL, its empirical design often leads to sub-optimal performance in our evaluation of different PTMs and target tasks. To this end, we propose a unified framework for CL with PTMs and PET that provides both theoretical and empirical advancements. We first perform an in-depth theoretical analysis of the CL objective in a pre-training context, decomposing it into hierarchical components namely within-task prediction, task-identity inference and task-adaptive prediction. We then present Hierarchical Decomposition PET (HiDe-PET), an innovative approach that explicitly optimizes the decomposed objective through incorporating task-specific and task-shared knowledge via mainstream PET techniques along with efficient recovery of pre-trained representations. Leveraging this framework, we delve into the distinct impacts of implementation strategy, PET technique and PET architecture, as well as adaptive knowledge accumulation amidst pronounced distribution changes. Finally, across various CL scenarios, our approach demonstrates remarkably superior performance over a broad spectrum of recent strong baselines.
Read more7/9/2024
0
Parameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective
Jingren Liu, Zhong Ji, YunLong Yu, Jiale Cao, Yanwei Pang, Jungong Han, Xuelong Li
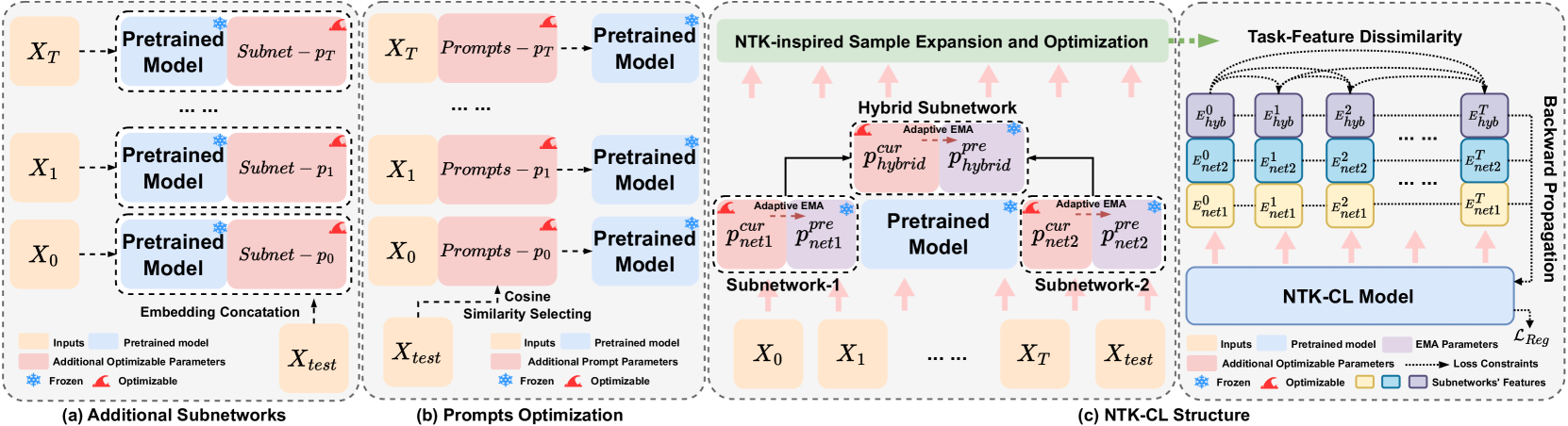
Parameter-efficient fine-tuning for continual learning (PEFT-CL) has shown promise in adapting pre-trained models to sequential tasks while mitigating catastrophic forgetting problem. However, understanding the mechanisms that dictate continual performance in this paradigm remains elusive. To tackle this complexity, we undertake a rigorous analysis of PEFT-CL dynamics to derive relevant metrics for continual scenarios using Neural Tangent Kernel (NTK) theory. With the aid of NTK as a mathematical analysis tool, we recast the challenge of test-time forgetting into the quantifiable generalization gaps during training, identifying three key factors that influence these gaps and the performance of PEFT-CL: training sample size, task-level feature orthogonality, and regularization. To address these challenges, we introduce NTK-CL, a novel framework that eliminates task-specific parameter storage while adaptively generating task-relevant features. Aligning with theoretical guidance, NTK-CL triples the feature representation of each sample, theoretically and empirically reducing the magnitude of both task-interplay and task-specific generalization gaps. Grounded in NTK analysis, our approach imposes an adaptive exponential moving average mechanism and constraints on task-level feature orthogonality, maintaining intra-task NTK forms while attenuating inter-task NTK forms. Ultimately, by fine-tuning optimizable parameters with appropriate regularization, NTK-CL achieves state-of-the-art performance on established PEFT-CL benchmarks. This work provides a theoretical foundation for understanding and improving PEFT-CL models, offering insights into the interplay between feature representation, task orthogonality, and generalization, contributing to the development of more efficient continual learning systems.
Read more7/25/2024

0
Parameter-Efficient and Memory-Efficient Tuning for Vision Transformer: A Disentangled Approach
Taolin Zhang, Jiawang Bai, Zhihe Lu, Dongze Lian, Genping Wang, Xinchao Wang, Shu-Tao Xia
Recent works on parameter-efficient transfer learning (PETL) show the potential to adapt a pre-trained Vision Transformer to downstream recognition tasks with only a few learnable parameters. However, since they usually insert new structures into the pre-trained model, entire intermediate features of that model are changed and thus need to be stored to be involved in back-propagation, resulting in memory-heavy training. We solve this problem from a novel disentangled perspective, i.e., dividing PETL into two aspects: task-specific learning and pre-trained knowledge utilization. Specifically, we synthesize the task-specific query with a learnable and lightweight module, which is independent of the pre-trained model. The synthesized query equipped with task-specific knowledge serves to extract the useful features for downstream tasks from the intermediate representations of the pre-trained model in a query-only manner. Built upon these features, a customized classification head is proposed to make the prediction for the input sample. lightweight architecture and avoids the use of heavy intermediate features for running gradient descent, it demonstrates limited memory usage in training. Extensive experiments manifest that our method achieves state-of-the-art performance under memory constraints, showcasing its applicability in real-world situations.
Read more7/16/2024
🎲
0
Gradient Projection For Parameter-Efficient Continual Learning
Jingyang Qiao, Zhizhong Zhang, Xin Tan, Yanyun Qu, Wensheng Zhang, Zhi Han, Yuan Xie
Parameter-efficient tunings (PETs) have demonstrated impressive performance and promising perspectives in training large models, while they are still confronted with a common problem: the trade-off between learning new content and protecting old knowledge, leading to zero-shot generalization collapse, and cross-modal hallucination. In this paper, we reformulate Adapter, LoRA, Prefix-tuning, and Prompt-tuning from the perspective of gradient projection, and firstly propose a unified framework called Parameter Efficient Gradient Projection (PEGP). We introduce orthogonal gradient projection into different PET paradigms and theoretically demonstrate that the orthogonal condition for the gradient can effectively resist forgetting even for large-scale models. It therefore modifies the gradient towards the direction that has less impact on the old feature space, with less extra memory space and training time. We extensively evaluate our method with different backbones, including ViT and CLIP, on diverse datasets, and experiments comprehensively demonstrate its efficiency in reducing forgetting in class, online class, domain, task, and multi-modality continual settings. The project page is available at https://dmcv-ecnu-pegp.github.io/.
Read more7/18/2024