Style-Talker: Finetuning Audio Language Model and Style-Based Text-to-Speech Model for Fast Spoken Dialogue Generation

0

Sign in to get full access
Overview
- This paper presents a system called "Style-Talker" that combines an audio language model and a style-based text-to-speech (TTS) model to enable fast spoken dialogue generation.
- The key innovations are finetuning the audio language model and the style-based TTS model to improve the quality and speed of the spoken dialogue.
- The authors evaluate their system on several benchmarks and report improvements in terms of response quality, generation speed, and user preference compared to existing approaches.
Plain English Explanation
The researchers developed a system called "Style-Talker" that can generate spoken dialogue quickly and with good quality. The system works by combining two key components:
- An audio language model that has been fine-tuned to understand and generate spoken language better.
- A style-based text-to-speech (TTS) model that can convert the generated text into natural-sounding speech, while also capturing the desired speaking style.
By fine-tuning these two models, the researchers were able to create a system that can generate spoken dialogue responses more quickly and with higher quality compared to previous approaches. This could be useful for applications like virtual assistants, chatbots, or other systems that need to engage in natural-sounding spoken conversations.
Technical Explanation
The key technical innovations in this paper are:
-
Finetuning the Audio Language Model: The authors start with a large pretrained audio language model, which can understand and generate spoken language. They then fine-tune this model on a dataset of spoken dialogue, to further improve its ability to generate relevant and coherent spoken responses.
-
Finetuning the Style-Based TTS Model: Similarly, the authors take a pretrained style-based text-to-speech (TTS) model, which can convert text into natural-sounding speech with different styles. They fine-tune this model to better capture the desired speaking style for the spoken dialogue task.
-
Integrating the Audio LM and TTS Models: The authors combine the finetuned audio language model and TTS model into a single "Style-Talker" system. This allows the system to quickly generate relevant spoken dialogue responses and convert them to high-quality synthetic speech.
The authors evaluate their Style-Talker system on several benchmark datasets for spoken dialogue generation. They report improvements in response quality, generation speed, and user preference compared to existing approaches that do not leverage the fine-tuned audio LM and style-based TTS components.
Critical Analysis
The paper makes a strong contribution by demonstrating how finetuning large language models and TTS models can improve the performance of spoken dialogue systems. However, a few potential limitations or areas for further research are:
-
Dataset Bias: The authors fine-tune their models on specific datasets of spoken dialogue. It's possible that the models may exhibit biases or limitations when applied to more diverse real-world conversations.
-
Evaluation Scope: The authors focus their evaluation primarily on automatically computed metrics and user preference surveys. It would be valuable to also assess the system's performance in more real-world, interactive dialogue scenarios.
-
Generalization to Other Domains: The authors demonstrate the effectiveness of their approach on spoken dialogue, but it's unclear how well the techniques would generalize to other speech-related tasks, such as spontaneous speech synthesis or multimodal language understanding.
Overall, the Style-Talker system represents an important step forward in leveraging large language models and style-based TTS for more natural and efficient spoken dialogue. Further research exploring the system's robustness, generalization, and real-world performance would be valuable.
Conclusion
This paper presents the "Style-Talker" system, which combines a fine-tuned audio language model and a fine-tuned style-based text-to-speech model to enable fast and high-quality spoken dialogue generation. The key innovations are the fine-tuning process for both the language model and TTS model, which significantly improves the performance of the overall system.
The authors demonstrate the effectiveness of their approach through various benchmarks, showing improvements in response quality, generation speed, and user preference compared to existing methods. While the system shows promise, further research is needed to explore its robustness, generalization, and real-world performance in more diverse dialogue scenarios.
Overall, the Style-Talker system represents an important step forward in leveraging large language models and style-based TTS for more natural and efficient spoken dialogue, with potential applications in virtual assistants, chatbots, and other conversational AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Style-Talker: Finetuning Audio Language Model and Style-Based Text-to-Speech Model for Fast Spoken Dialogue Generation
Yinghao Aaron Li, Xilin Jiang, Jordan Darefsky, Ge Zhu, Nima Mesgarani
The rapid advancement of large language models (LLMs) has significantly propelled the development of text-based chatbots, demonstrating their capability to engage in coherent and contextually relevant dialogues. However, extending these advancements to enable end-to-end speech-to-speech conversation bots remains a formidable challenge, primarily due to the extensive dataset and computational resources required. The conventional approach of cascading automatic speech recognition (ASR), LLM, and text-to-speech (TTS) models in a pipeline, while effective, suffers from unnatural prosody because it lacks direct interactions between the input audio and its transcribed text and the output audio. These systems are also limited by their inherent latency from the ASR process for real-time applications. This paper introduces Style-Talker, an innovative framework that fine-tunes an audio LLM alongside a style-based TTS model for fast spoken dialog generation. Style-Talker takes user input audio and uses transcribed chat history and speech styles to generate both the speaking style and text for the response. Subsequently, the TTS model synthesizes the speech, which is then played back to the user. While the response speech is being played, the input speech undergoes ASR processing to extract the transcription and speaking style, serving as the context for the ensuing dialogue turn. This novel pipeline accelerates the traditional cascade ASR-LLM-TTS systems while integrating rich paralinguistic information from input speech. Our experimental results show that Style-Talker significantly outperforms the conventional cascade and speech-to-speech baselines in terms of both dialogue naturalness and coherence while being more than 50% faster.
Read more8/23/2024

0
StyleSpeech: Parameter-efficient Fine Tuning for Pre-trained Controllable Text-to-Speech
Haowei Lou, Helen Paik, Wen Hu, Lina Yao
This paper introduces StyleSpeech, a novel Text-to-Speech~(TTS) system that enhances the naturalness and accuracy of synthesized speech. Building upon existing TTS technologies, StyleSpeech incorporates a unique Style Decorator structure that enables deep learning models to simultaneously learn style and phoneme features, improving adaptability and efficiency through the principles of Lower Rank Adaptation~(LoRA). LoRA allows efficient adaptation of style features in pre-trained models. Additionally, we introduce a novel automatic evaluation metric, the LLM-Guided Mean Opinion Score (LLM-MOS), which employs large language models to offer an objective and robust protocol for automatically assessing TTS system performance. Extensive testing on benchmark datasets shows that our approach markedly outperforms existing state-of-the-art baseline methods in producing natural, accurate, and high-quality speech. These advancements not only pushes the boundaries of current TTS system capabilities, but also facilitate the application of TTS system in more dynamic and specialized, such as interactive virtual assistants, adaptive audiobooks, and customized voice for gaming. Speech samples can be found in https://style-speech.vercel.app
Read more8/28/2024
0
Advancing Large Language Models to Capture Varied Speaking Styles and Respond Properly in Spoken Conversations
Guan-Ting Lin, Cheng-Han Chiang, Hung-yi Lee
In spoken dialogue, even if two current turns are the same sentence, their responses might still differ when they are spoken in different styles. The spoken styles, containing paralinguistic and prosodic information, mark the most significant difference between text and speech modality. When using text-only LLMs to model spoken dialogue, text-only LLMs cannot give different responses based on the speaking style of the current turn. In this paper, we focus on enabling LLMs to listen to the speaking styles and respond properly. Our goal is to teach the LLM that even if the sentences are identical if they are spoken in different styles, their corresponding responses might be different. Since there is no suitable dataset for achieving this goal, we collect a speech-to-speech dataset, StyleTalk, with the following desired characteristics: when two current speeches have the same content but are spoken in different styles, their responses will be different. To teach LLMs to understand and respond properly to the speaking styles, we propose the Spoken-LLM framework that can model the linguistic content and the speaking styles. We train Spoken-LLM using the StyleTalk dataset and devise a two-stage training pipeline to help the Spoken-LLM better learn the speaking styles. Based on extensive experiments, we show that Spoken-LLM outperforms text-only baselines and prior speech LLMs methods.
Read more5/31/2024
0
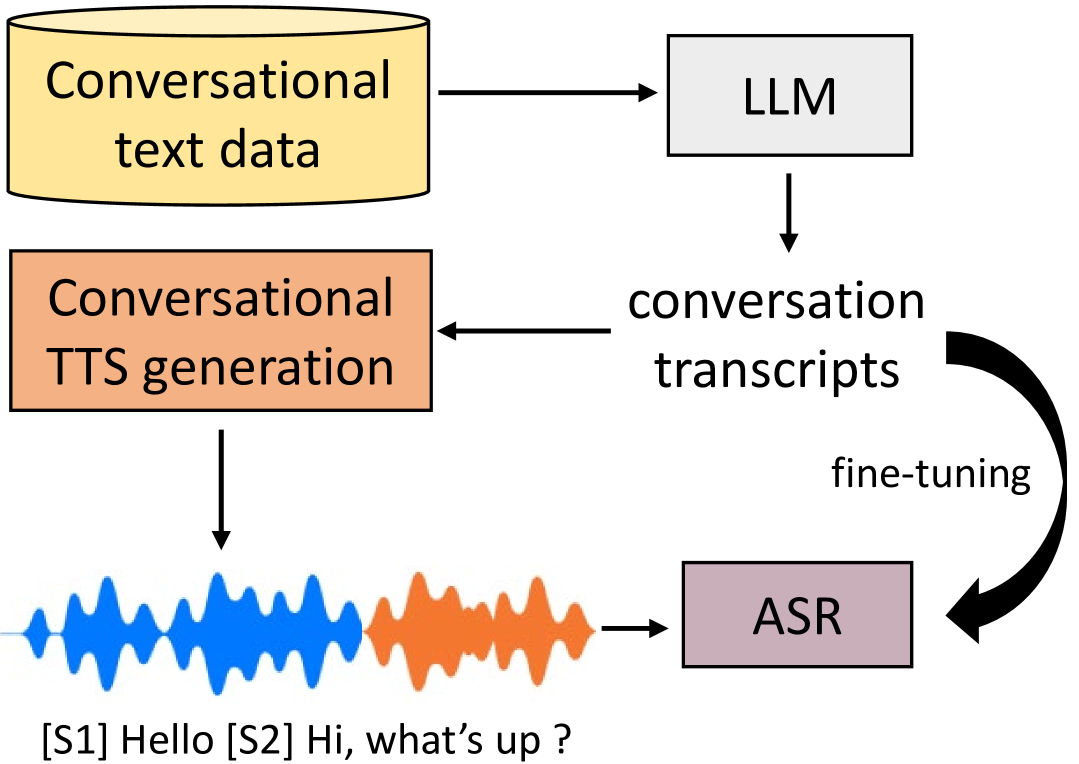
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024