Leveraging knowledge distillation for partial multi-task learning from multiple remote sensing datasets

0
🏅
Sign in to get full access
Overview
- This paper proposes using knowledge distillation to enhance the performance of partial multi-task learning in remote sensing applications.
- Partial multi-task learning allows combining datasets annotated for different tasks and predicting more tasks with fewer network parameters.
- The naive approach to partial multi-task learning is sub-optimal due to the lack of all-task annotations for learning joint representations.
Plain English Explanation
In machine learning, there is often a need to train models that can perform multiple tasks, such as object detection and semantic segmentation, on aerial images. This paper introduces a technique called "partial multi-task learning" that can help with this.
Partial multi-task learning allows you to combine datasets that are annotated for different tasks and use that information to train a single model that can perform multiple tasks. This is useful because it means you can get more capabilities from your model without having to train separate models for each task.
However, the traditional way of doing partial multi-task learning has a problem - it doesn't work well because the model doesn't have access to all the annotations it needs to learn the joint representations (the connections between the different tasks) properly. This paper proposes using a technique called "knowledge distillation" to overcome this issue.
Knowledge distillation involves using a more complex "teacher" model to guide the training of a simpler "student" model. In this case, the idea is to use the teacher model to provide the missing annotations that the student model needs to learn the joint representations and perform well on all the tasks.
The experiments in the paper show that this approach can be effective for tasks like object detection and semantic segmentation in aerial images, compared to other techniques for partial multi-task learning.
Technical Explanation
The paper proposes a method for performing partial multi-task learning, where training examples are annotated for only one of the target tasks. This is a common scenario in remote sensing applications, where datasets may be annotated for different tasks (e.g., object detection, semantic segmentation).
The key contribution of this paper is the use of knowledge distillation to address the limitations of the naive approach to partial multi-task learning. In the naive approach, the lack of all-task annotations makes it difficult to learn effective joint representations across the tasks.
To overcome this, the proposed method uses a "teacher" model that is trained on the full set of tasks to guide the training of a "student" model that is only trained on the partial task annotations. The teacher model provides the missing annotations for the alternate tasks, which helps the student model learn better joint representations and perform well on all the tasks.
The paper evaluates this approach on the public ISPRS 2D Semantic Labeling Contest dataset, which includes aerial images annotated for both object detection and semantic segmentation tasks. The results show that the proposed method outperforms other techniques for partial multi-task learning, as well as single-task models.
Critical Analysis
The paper presents a promising approach to addressing the challenges of partial multi-task learning in remote sensing applications. The use of knowledge distillation to leverage the information from a teacher model is a clever solution to the problem of missing annotations.
However, the paper does not explore the potential limitations or caveats of this approach. For example, it's unclear how the performance of the method would scale as the number of tasks or the complexity of the tasks increases. Additionally, the paper does not discuss the computational overhead or training time required for the teacher-student framework, which could be an important consideration in practical applications.
Furthermore, the paper could benefit from a more thorough comparison to related work in the field of knowledge distillation and multi-task learning. This would help situate the proposed method within the broader context of the research landscape and highlight its unique contributions.
Overall, the paper presents a compelling approach that demonstrates the potential of combining partial multi-task learning and knowledge distillation. However, further research is needed to fully understand the limitations and broader applicability of this technique.
Conclusion
This paper introduces a novel approach to partial multi-task learning in remote sensing applications, where training data is only annotated for a subset of the target tasks. By leveraging knowledge distillation, the proposed method is able to overcome the limitations of the naive approach, which struggles to learn effective joint representations due to the lack of all-task annotations.
The experimental results on the ISPRS 2D Semantic Labeling Contest dataset show that the proposed method can outperform other techniques for partial multi-task learning, as well as single-task models. This suggests that the combination of partial multi-task learning and knowledge distillation could be a valuable tool for remote sensing applications, where the ability to predict multiple tasks from limited annotated data is often crucial.
While the paper presents a promising approach, further research is needed to fully understand its limitations and broader applicability. Nonetheless, this work represents an important step forward in addressing the practical challenges of multi-task learning in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Leveraging knowledge distillation for partial multi-task learning from multiple remote sensing datasets
Ho`ang-^An L^e, Minh-Tan Pham
Partial multi-task learning where training examples are annotated for one of the target tasks is a promising idea in remote sensing as it allows combining datasets annotated for different tasks and predicting more tasks with fewer network parameters. The naive approach to partial multi-task learning is sub-optimal due to the lack of all-task annotations for learning joint representations. This paper proposes using knowledge distillation to replace the need of ground truths for the alternate task and enhance the performance of such approach. Experiments conducted on the public ISPRS 2D Semantic Labeling Contest dataset show the effectiveness of the proposed idea on partial multi-task learning for semantic tasks including object detection and semantic segmentation in aerial images.
Read more5/27/2024
🖼️
0
Multi-Task Multi-Scale Contrastive Knowledge Distillation for Efficient Medical Image Segmentation
Risab Biswas
This thesis aims to investigate the feasibility of knowledge transfer between neural networks for medical image segmentation tasks, specifically focusing on the transfer from a larger multi-task Teacher network to a smaller Student network. In the context of medical imaging, where the data volumes are often limited, leveraging knowledge from a larger pre-trained network could be useful. The primary objective is to enhance the performance of a smaller student model by incorporating knowledge representations acquired by a teacher model that adopts a multi-task pre-trained architecture trained on CT images, to a more resource-efficient student network, which can essentially be a smaller version of the same, trained on a mere 50% of the data than that of the teacher model. To facilitate knowledge transfer between the two models, we devised an architecture incorporating multi-scale feature distillation and supervised contrastive learning. Our study aims to improve the student model's performance by integrating knowledge representations from the teacher model. We investigate whether this approach is particularly effective in scenarios with limited computational resources and limited training data availability. To assess the impact of multi-scale feature distillation, we conducted extensive experiments. We also conducted a detailed ablation study to determine whether it is essential to distil knowledge at various scales, including low-level features from encoder layers, for effective knowledge transfer. In addition, we examine different losses in the knowledge distillation process to gain insights into their effects on overall performance.
Read more6/6/2024
0
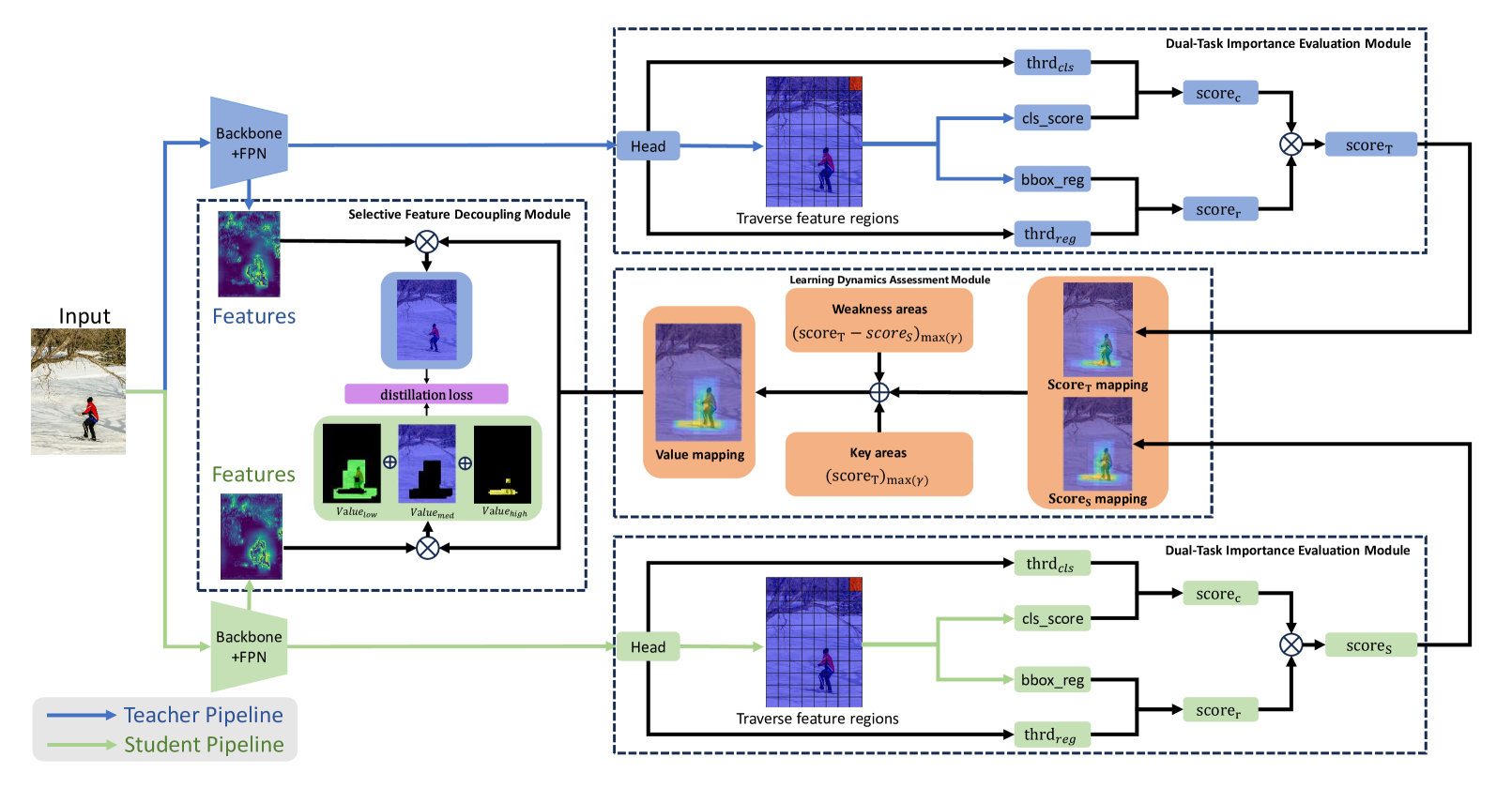
Task Integration Distillation for Object Detectors
Hai Su, ZhenWen Jian, Songsen Yu
Knowledge distillation is a widely adopted technique for model lightening. However, the performance of most knowledge distillation methods in the domain of object detection is not satisfactory. Typically, knowledge distillation approaches consider only the classification task among the two sub-tasks of an object detector, largely overlooking the regression task. This oversight leads to a partial understanding of the object detector's comprehensive task, resulting in skewed estimations and potentially adverse effects. Therefore, we propose a knowledge distillation method that addresses both the classification and regression tasks, incorporating a task significance strategy. By evaluating the importance of features based on the output of the detector's two sub-tasks, our approach ensures a balanced consideration of both classification and regression tasks in object detection. Drawing inspiration from real-world teaching processes and the definition of learning condition, we introduce a method that focuses on both key and weak areas. By assessing the value of features for knowledge distillation based on their importance differences, we accurately capture the current model's learning situation. This method effectively prevents the issue of biased predictions about the model's learning reality caused by an incomplete utilization of the detector's outputs.
Read more4/3/2024
✨
0
Knowledge Distillation via the Target-aware Transformer
Sihao Lin, Hongwei Xie, Bing Wang, Kaicheng Yu, Xiaojun Chang, Xiaodan Liang, Gang Wang
Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code is available at https://github.com/sihaoevery/TaT.
Read more4/9/2024