Leveraging Large Language Models for Efficient Failure Analysis in Game Development
2406.07084
0
0

Abstract
In games, and more generally in the field of software development, early detection of bugs is vital to maintain a high quality of the final product. Automated tests are a powerful tool that can catch a problem earlier in development by executing periodically. As an example, when new code is submitted to the code base, a new automated test verifies these changes. However, identifying the specific change responsible for a test failure becomes harder when dealing with batches of changes -- especially in the case of a large-scale project such as a AAA game, where thousands of people contribute to a single code base. This paper proposes a new approach to automatically identify which change in the code caused a test to fail. The method leverages Large Language Models (LLMs) to associate error messages with the corresponding code changes causing the failure. We investigate the effectiveness of our approach with quantitative and qualitative evaluations. Our approach reaches an accuracy of 71% in our newly created dataset, which comprises issues reported by developers at EA over a period of one year. We further evaluated our model through a user study to assess the utility and usability of the tool from a developer perspective, resulting in a significant reduction in time -- up to 60% -- spent investigating issues.
Create account to get full access
Overview
- The paper explores leveraging large language models (LLMs) to improve the efficiency of failure analysis in game development.
- It focuses on using LLMs to automatically detect and diagnose issues during game testing and development.
- The proposed approach aims to reduce the time and effort required for manual failure analysis, which is a crucial but time-consuming task in game development.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. In this paper, the researchers investigate how these LLMs can be used to streamline the process of identifying and analyzing issues that arise during game development.
Game development is a complex process that often involves extensive testing to ensure the final product is of high quality. When problems or "failures" are encountered during testing, developers need to carefully analyze the causes and identify the appropriate fixes. This failure analysis is a critical step, but it can be time-consuming and resource-intensive, especially for large or complex games.
The researchers propose using LLMs to automate parts of the failure analysis process. By training the LLMs on past issues and their resolutions, they can develop systems that can automatically detect new problems, suggest likely causes, and even propose potential solutions. This could dramatically reduce the time and effort required for manual failure analysis, allowing developers to focus more on the creative aspects of game development.
The key idea is to leverage the natural language processing capabilities of LLMs to better understand the context and nature of game-related issues. Just as humans can quickly identify and diagnose problems based on descriptions or logs, the researchers aim to create AI systems that can do the same, but at a much larger scale and faster pace.
Technical Explanation
The paper presents a framework for leveraging large language models (LLMs) to improve the efficiency of failure analysis in game development. The proposed approach involves using LLMs to automatically detect, diagnose, and provide recommendations for addressing issues that arise during game testing and development.
The researchers first describe the challenges of manual failure analysis, which can be time-consuming, labor-intensive, and require significant domain expertise. They then outline how LLMs can be used to automate various steps in the failure analysis process, including:
-
Issue Detection: LLMs can be trained on historical bug reports, error logs, and other data sources to learn the patterns and characteristics of common game-related issues. This allows the system to automatically identify new problems as they arise during testing.
-
Cause Diagnosis: By analyzing the contextual information and descriptions associated with detected issues, LLMs can infer the likely root causes and provide insights to developers.
-
Resolution Recommendation: Building on the diagnostic capabilities, the LLM-powered system can suggest potential fixes or workarounds based on past solutions to similar problems.
The paper discusses the key components of the proposed framework, including data collection, model training, and the integration of the LLM-based system into the game development workflow. The authors also present the results of preliminary experiments, demonstrating the potential for significant time and effort savings compared to traditional manual failure analysis.
Critical Analysis
The paper presents a promising approach to leveraging large language models (LLMs) for improving the efficiency of failure analysis in game development. The researchers make a compelling case for the challenges of manual failure analysis and the potential benefits of automating this process using LLM-based techniques.
One key strength of the proposed framework is its ability to learn from historical data and apply that knowledge to identify, diagnose, and suggest resolutions for new issues. This could significantly reduce the time and effort required for developers to understand and address problems that arise during testing and deployment.
However, the paper does acknowledge some limitations and areas for further research. For example, the authors note that the effectiveness of the LLM-based system will depend on the quality and representativeness of the training data, as well as the ability to integrate the system seamlessly into the game development workflow.
Additionally, while the preliminary results are encouraging, the paper does not provide a thorough evaluation of the system's performance across a diverse range of game types, development environments, and failure scenarios. Further research and real-world testing would be needed to fully validate the scalability and robustness of the approach.
Another potential area of concern is the reliance on language models, which can sometimes exhibit biases or inconsistencies in their outputs. The researchers may need to explore techniques for improving the reliability and trustworthiness of the LLM-based failure analysis system, particularly in mission-critical game development contexts.
Overall, the paper presents a compelling and well-designed research project that could have significant implications for improving the efficiency and quality of game development. By leveraging large language models for software vulnerability detection, automating bug detection using LLMs, and predicting flaky tests with LLMs, the researchers are exploring promising avenues for AI-powered software engineering tools.
Conclusion
This paper investigates the use of large language models (LLMs) to improve the efficiency of failure analysis in game development. By automating the detection, diagnosis, and resolution of issues that arise during testing and deployment, the proposed framework has the potential to significantly reduce the time and effort required for manual failure analysis.
The key innovations of this work include leveraging LLMs' natural language processing capabilities to understand the context and nature of game-related problems, as well as the ability to learn from historical data to inform the identification and resolution of new issues.
While the preliminary results are promising, further research and real-world testing are needed to fully validate the scalability and robustness of the LLM-based failure analysis system. Addressing potential challenges, such as data quality, model biases, and integration with existing development workflows, will be crucial for the successful deployment of this technology in the game industry.
Overall, this research represents an important step forward in automating patch set generation from code reviews and using LLMs for multi-role consensus in vulnerability discussions, demonstrating the potential of AI-powered tools to enhance the efficiency and quality of software development processes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study
Karl Tamberg, Hayretdin Bahsi
0
0
Despite various approaches being employed to detect vulnerabilities, the number of reported vulnerabilities shows an upward trend over the years. This suggests the problems are not caught before the code is released, which could be caused by many factors, like lack of awareness, limited efficacy of the existing vulnerability detection tools or the tools not being user-friendly. To help combat some issues with traditional vulnerability detection tools, we propose using large language models (LLMs) to assist in finding vulnerabilities in source code. LLMs have shown a remarkable ability to understand and generate code, underlining their potential in code-related tasks. The aim is to test multiple state-of-the-art LLMs and identify the best prompting strategies, allowing extraction of the best value from the LLMs. We provide an overview of the strengths and weaknesses of the LLM-based approach and compare the results to those of traditional static analysis tools. We find that LLMs can pinpoint many more issues than traditional static analysis tools, outperforming traditional tools in terms of recall and F1 scores. The results should benefit software developers and security analysts responsible for ensuring that the code is free of vulnerabilities.
5/27/2024

Automatic Bug Detection in LLM-Powered Text-Based Games Using LLMs
Claire Jin, Sudha Rao, Xiangyu Peng, Portia Botchway, Jessica Quaye, Chris Brockett, Bill Dolan
0
0
Advancements in large language models (LLMs) are revolutionizing interactive game design, enabling dynamic plotlines and interactions between players and non-player characters (NPCs). However, LLMs may exhibit flaws such as hallucinations, forgetfulness, or misinterpretations of prompts, causing logical inconsistencies and unexpected deviations from intended designs. Automated techniques for detecting such game bugs are still lacking. To address this, we propose a systematic LLM-based method for automatically identifying such bugs from player game logs, eliminating the need for collecting additional data such as post-play surveys. Applied to a text-based game DejaBoom!, our approach effectively identifies bugs inherent in LLM-powered interactive games, surpassing unstructured LLM-powered bug-catching methods and filling the gap in automated detection of logical and design flaws.
6/10/2024

FlakyFix: Using Large Language Models for Predicting Flaky Test Fix Categories and Test Code Repair
Sakina Fatima, Hadi Hemmati, Lionel Briand
0
0
Flaky tests are problematic because they non-deterministically pass or fail for the same software version under test, causing confusion and wasting development effort. While machine learning models have been used to predict flakiness and its root causes, there is much less work on providing support to fix the problem. To address this gap, in this paper, we focus on predicting the type of fix that is required to remove flakiness and then repair the test code on that basis. We do this for a subset of flaky test cases where the root cause of flakiness is in the test case itself and not in the production code. Our key idea is to guide the repair process with additional knowledge about the test's flakiness in the form of its predicted fix category. Thus, we first propose a framework that automatically generates labeled datasets for 13 fix categories and trains models to predict the fix category of a flaky test by analyzing the test code only. Our experimental results using code models and few-shot learning show that we can correctly predict most of the fix categories. To show the usefulness of such fix category labels for automatically repairing flakiness, in addition to informing testers, we augment a Large Language Model (LLM) like GPT with such extra knowledge to ask the LLM for repair suggestions. The results show that our suggested fix category labels, complemented with in-context learning, significantly enhance the capability of GPT 3.5 Turbo in generating fixes for flaky tests. Based on the execution and analysis of a sample of GPT-repaired flaky tests, we estimate that a large percentage of such repairs, (roughly between 70% and 90%) can be expected to pass. For the failing repaired tests, on average, 16% of the test code needs to be further changed for them to pass.
5/21/2024
AutoDetect: Towards a Unified Framework for Automated Weakness Detection in Large Language Models
Jiale Cheng, Yida Lu, Xiaotao Gu, Pei Ke, Xiao Liu, Yuxiao Dong, Hongning Wang, Jie Tang, Minlie Huang
0
0
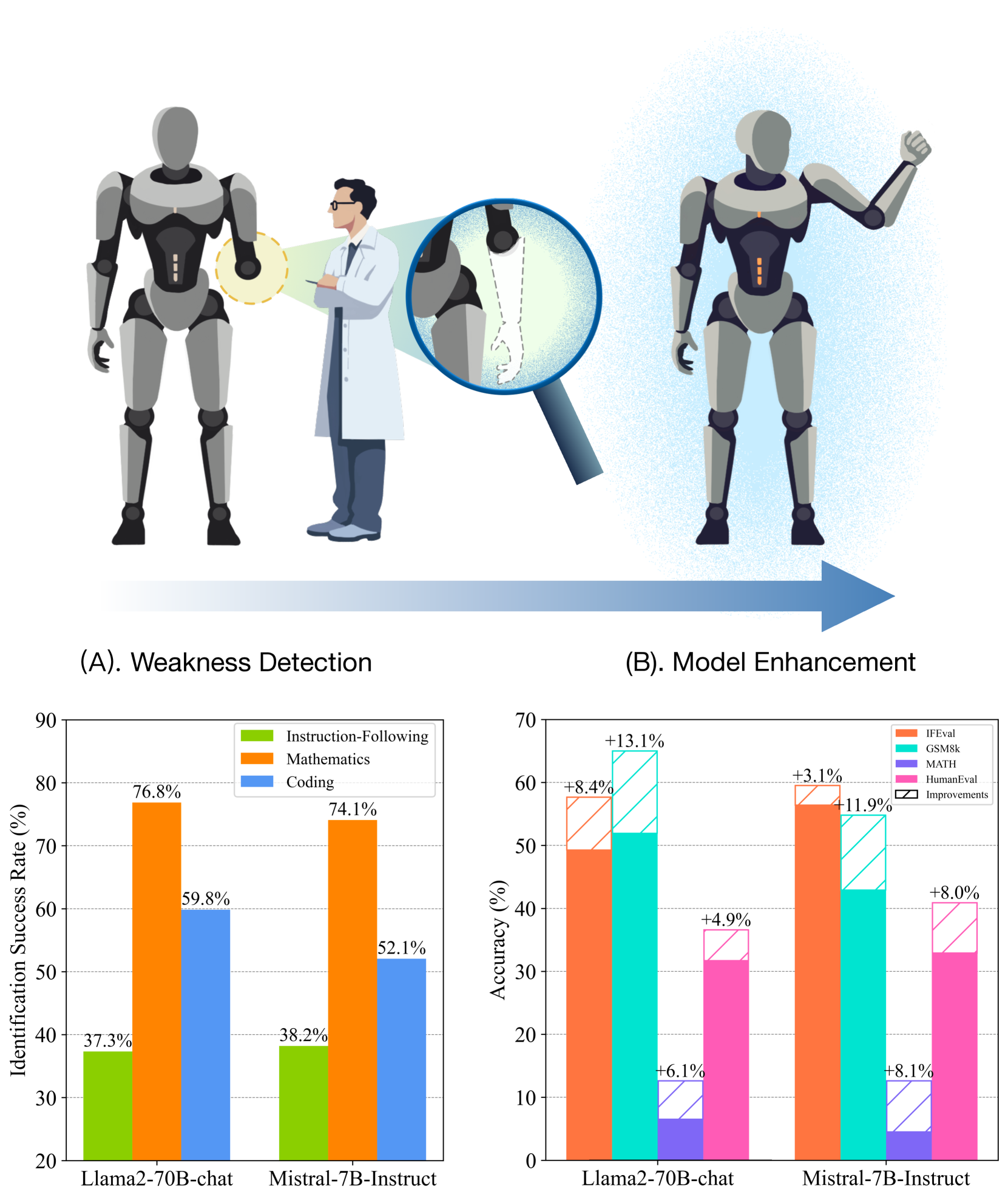
Although Large Language Models (LLMs) are becoming increasingly powerful, they still exhibit significant but subtle weaknesses, such as mistakes in instruction-following or coding tasks. As these unexpected errors could lead to severe consequences in practical deployments, it is crucial to investigate the limitations within LLMs systematically. Traditional benchmarking approaches cannot thoroughly pinpoint specific model deficiencies, while manual inspections are costly and not scalable. In this paper, we introduce a unified framework, AutoDetect, to automatically expose weaknesses in LLMs across various tasks. Inspired by the educational assessment process that measures students' learning outcomes, AutoDetect consists of three LLM-powered agents: Examiner, Questioner, and Assessor. The collaboration among these three agents is designed to realize comprehensive and in-depth weakness identification. Our framework demonstrates significant success in uncovering flaws, with an identification success rate exceeding 30% in prominent models such as ChatGPT and Claude. More importantly, these identified weaknesses can guide specific model improvements, proving more effective than untargeted data augmentation methods like Self-Instruct. Our approach has led to substantial enhancements in popular LLMs, including the Llama series and Mistral-7b, boosting their performance by over 10% across several benchmarks. Code and data are publicly available at https://github.com/thu-coai/AutoDetect.
6/26/2024