Multi-role Consensus through LLMs Discussions for Vulnerability Detection
2403.14274
0
0
Abstract
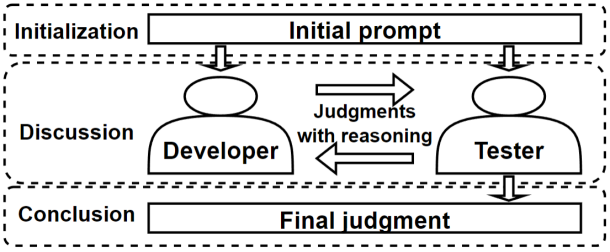
Recent advancements in large language models (LLMs) have highlighted the potential for vulnerability detection, a crucial component of software quality assurance. Despite this progress, most studies have been limited to the perspective of a single role, usually testers, lacking diverse viewpoints from different roles in a typical software development life-cycle, including both developers and testers. To this end, this paper introduces a multi-role approach to employ LLMs to act as different roles simulating a real-life code review process and engaging in discussions toward a consensus on the existence and classification of vulnerabilities in the code. Preliminary evaluation of this approach indicates a 13.48% increase in the precision rate, an 18.25% increase in the recall rate, and a 16.13% increase in the F1 score.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper proposes a novel approach called "MuCoLD" (Multi-role Consensus through LLMs Discussions for Vulnerability Detection) to leverage large language models (LLMs) for collaboratively detecting software vulnerabilities.
- The paper explores how LLMs can facilitate discussions among various stakeholders, such as developers, security experts, and users, to reach a consensus on identifying and addressing vulnerabilities.
- The preliminary evaluation of MuCoLD suggests its potential for improving the software security assessment process by leveraging the collective knowledge and perspectives of multiple roles.
Plain English Explanation
The research paper presents a new way to use large language models to help find and fix software bugs or security problems. The idea is to get different people involved, like developers, security experts, and regular users, to discuss the issues together using the language models. This way, they can all share their knowledge and perspectives to reach an agreement on what the problems are and how to solve them.
The researchers call this approach "MuCoLD," which stands for "Multi-role Consensus through LLMs Discussions for Vulnerability Detection." The initial testing of MuCoLD suggests it could be a promising way to improve the process of assessing software security by tapping into the collective wisdom of multiple stakeholders.
Technical Explanation
The paper introduces the MuCoLD framework, which leverages large language models to facilitate discussions among different roles, such as developers, security experts, and users, to collaboratively identify and address software vulnerabilities.
The MuCoLD workflow involves the following steps:
- Vulnerability identification: LLMs are used to analyze software code and other relevant artifacts to detect potential vulnerabilities.
- Role-specific discussions: LLMs facilitate discussions among stakeholders, allowing them to share their perspectives, concerns, and proposed solutions.
- Consensus building: The LLM-mediated discussions aim to help the stakeholders reach a shared understanding and consensus on the identified vulnerabilities and appropriate remediation strategies.
The preliminary evaluation of MuCoLD was conducted on a dataset of known software vulnerabilities. The results suggest that the approach can effectively leverage the collective knowledge and expertise of various stakeholders to improve the vulnerability detection and resolution process.
Critical Analysis
The paper presents a promising approach to leveraging large language models for collaborative software vulnerability detection. However, the research is still in the preliminary stage, and further evaluation is needed to fully assess the practical benefits and limitations of the MuCoLD framework.
One potential concern is the reliance on LLMs, which have been shown to have various biases and limitations that could impact the quality and objectivity of the discussions. Additionally, the paper does not address the challenges of ensuring effective and unbiased participation from all stakeholders, which could be crucial for achieving meaningful consensus.
Further research is needed to explore the scalability of the MuCoLD approach, its performance in real-world software development scenarios, and the potential implications of categorizing LLMs as productivity tools in the context of software security.
Conclusion
The MuCoLD framework presented in this paper represents an innovative approach to leveraging large language models for collaborative software vulnerability detection. By facilitating discussions among diverse stakeholders, the method aims to harness the collective knowledge and perspectives to improve the software security assessment process.
While the preliminary evaluation is promising, further research and development are needed to fully realize the potential of this approach. Addressing the challenges of LLM biases, stakeholder engagement, and scalability will be crucial for the practical adoption and effectiveness of the MuCoLD framework in real-world software development and security contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Model for Vulnerability Detection and Repair: Literature Review and Roadmap
Xin Zhou, Sicong Cao, Xiaobing Sun, David Lo
0
0
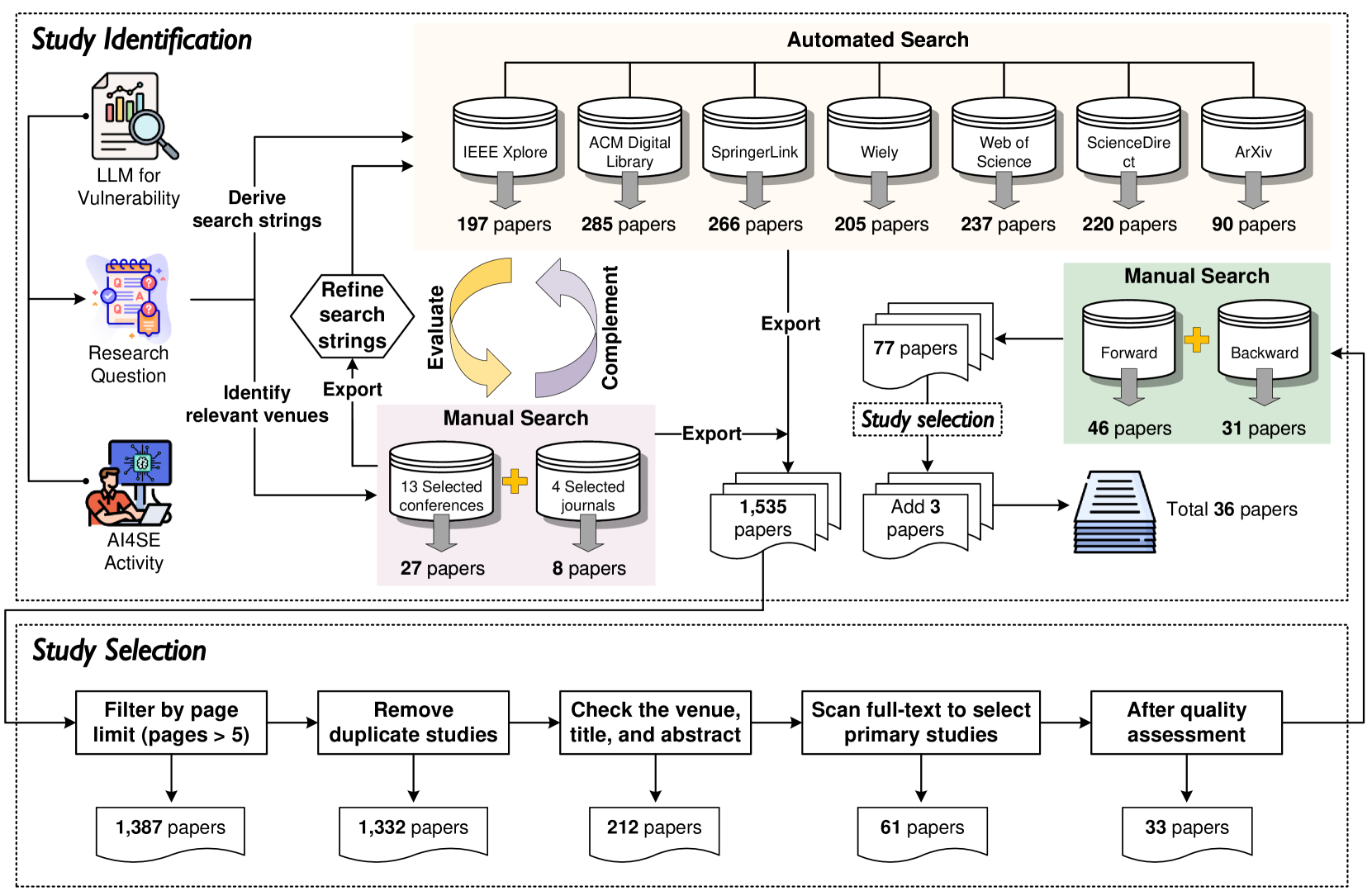
The significant advancements in Large Language Models (LLMs) have resulted in their widespread adoption across various tasks within Software Engineering (SE), including vulnerability detection and repair. Numerous recent studies have investigated the application of LLMs to enhance vulnerability detection and repair tasks. Despite the increasing research interest, there is currently no existing survey that focuses on the utilization of LLMs for vulnerability detection and repair. In this paper, we aim to bridge this gap by offering a systematic literature review of approaches aimed at improving vulnerability detection and repair through the utilization of LLMs. The review encompasses research work from leading SE, AI, and Security conferences and journals, covering 36 papers published at 21 distinct venues. By answering three key research questions, we aim to (1) summarize the LLMs employed in the relevant literature, (2) categorize various LLM adaptation techniques in vulnerability detection, and (3) classify various LLM adaptation techniques in vulnerability repair. Based on our findings, we have identified a series of challenges that still need to be tackled considering existing studies. Additionally, we have outlined a roadmap highlighting potential opportunities that we believe are pertinent and crucial for future research endeavors.
4/4/2024
Multitask-based Evaluation of Open-Source LLM on Software Vulnerability
Xin Yin, Chao Ni
0
0
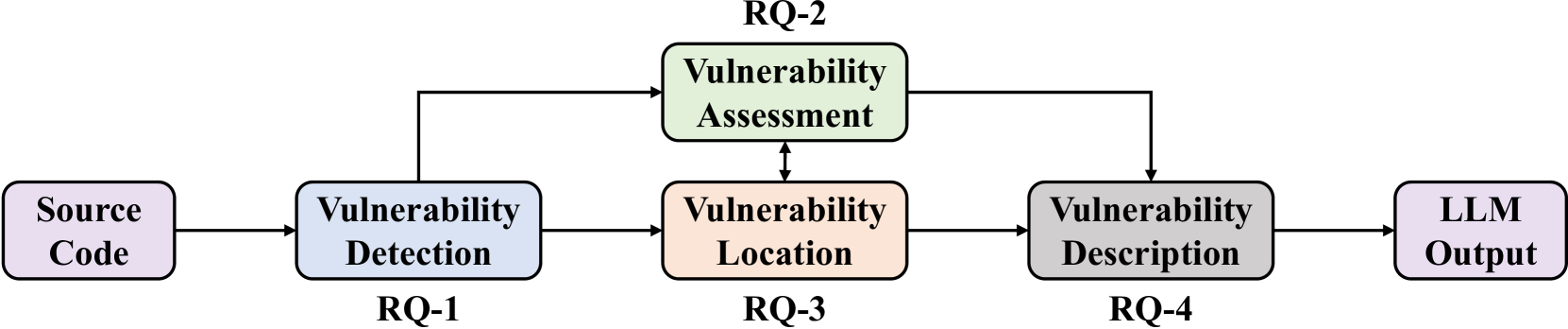
This paper proposes a pipeline for quantitatively evaluating interactive LLMs using publicly available datasets. We carry out an extensive technical evaluation of LLMs using Big-Vul covering four different common software vulnerability tasks. We evaluate the multitask and multilingual aspects of LLMs based on this dataset. We find that the existing state-of-the-art methods are generally superior to LLMs in software vulnerability detection. Although LLMs improve accuracy when providing context information, they still have limitations in accurately predicting severity ratings for certain CWE types. In addition, LLMs demonstrate some ability to locate vulnerabilities for certain CWE types, but their performance varies among different CWE types. Finally, LLMs show uneven performance in generating CVE descriptions for various CWE types, with limited accuracy in a few-shot setting. Overall, though LLMs perform well in some aspects, they still need improvement in understanding the subtle differences in code vulnerabilities and the ability to describe vulnerabilities to fully realize their potential. Our evaluation pipeline provides valuable insights for further enhancing LLMs' software vulnerability handling capabilities.
4/3/2024
Large Language Models for Cyber Security: A Systematic Literature Review
HanXiang Xu, ShenAo Wang, NingKe Li, KaiLong Wang, YanJie Zhao, Kai Chen, Ting Yu, Yang Liu, HaoYu Wang
0
0
The rapid advancement of Large Language Models (LLMs) has opened up new opportunities for leveraging artificial intelligence in various domains, including cybersecurity. As the volume and sophistication of cyber threats continue to grow, there is an increasing need for intelligent systems that can automatically detect vulnerabilities, analyze malware, and respond to attacks. In this survey, we conduct a comprehensive review of the literature on the application of LLMs in cybersecurity (LLM4Security). By comprehensively collecting over 30K relevant papers and systematically analyzing 127 papers from top security and software engineering venues, we aim to provide a holistic view of how LLMs are being used to solve diverse problems across the cybersecurity domain. Through our analysis, we identify several key findings. First, we observe that LLMs are being applied to a wide range of cybersecurity tasks, including vulnerability detection, malware analysis, network intrusion detection, and phishing detection. Second, we find that the datasets used for training and evaluating LLMs in these tasks are often limited in size and diversity, highlighting the need for more comprehensive and representative datasets. Third, we identify several promising techniques for adapting LLMs to specific cybersecurity domains, such as fine-tuning, transfer learning, and domain-specific pre-training. Finally, we discuss the main challenges and opportunities for future research in LLM4Security, including the need for more interpretable and explainable models, the importance of addressing data privacy and security concerns, and the potential for leveraging LLMs for proactive defense and threat hunting. Overall, our survey provides a comprehensive overview of the current state-of-the-art in LLM4Security and identifies several promising directions for future research.
5/10/2024
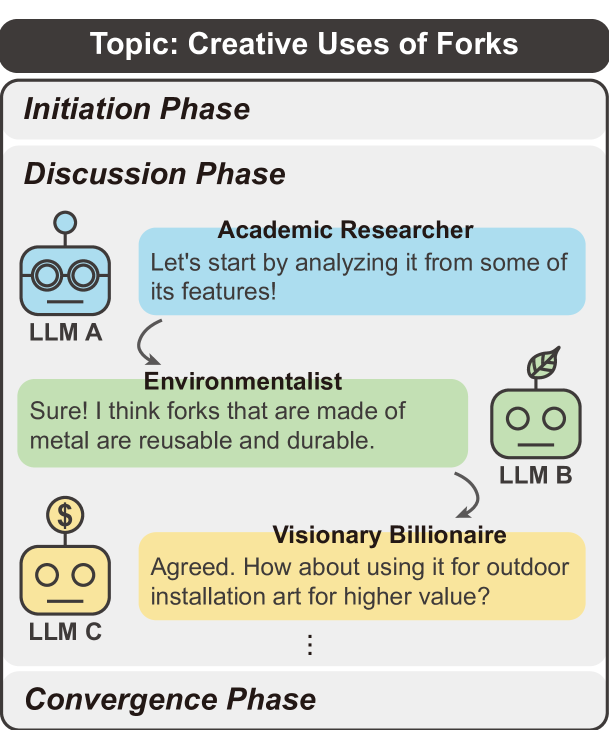
LLM Discussion: Enhancing the Creativity of Large Language Models via Discussion Framework and Role-Play
Li-Chun Lu, Shou-Jen Chen, Tsung-Min Pai, Chan-Hung Yu, Hung-yi Lee, Shao-Hua Sun
0
0
Large language models (LLMs) have shown exceptional proficiency in natural language processing but often fall short of generating creative and original responses to open-ended questions. To enhance LLM creativity, our key insight is to emulate the human process of inducing collective creativity through engaging discussions with participants from diverse backgrounds and perspectives. To this end, we propose LLM Discussion, a three-phase discussion framework that facilitates vigorous and diverging idea exchanges and ensures convergence to creative answers. Moreover, we adopt a role-playing technique by assigning distinct roles to LLMs to combat the homogeneity of LLMs. We evaluate the efficacy of the proposed framework with the Alternative Uses Test, Similarities Test, Instances Test, and Scientific Creativity Test through both LLM evaluation and human study. Our proposed framework outperforms single-LLM approaches and existing multi-LLM frameworks across various creativity metrics.
5/14/2024