AutoDetect: Towards a Unified Framework for Automated Weakness Detection in Large Language Models
2406.16714
0
0
Abstract
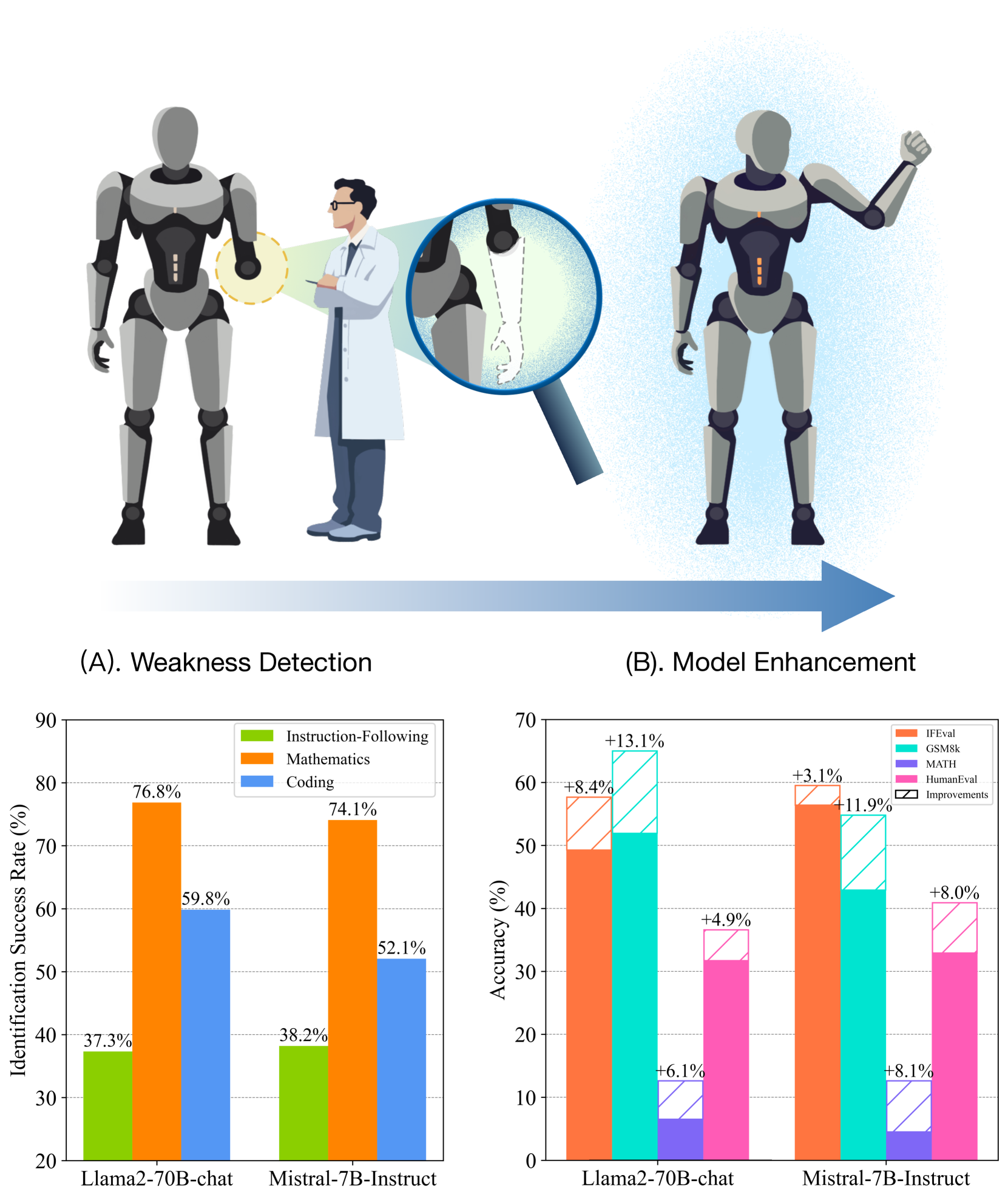
Although Large Language Models (LLMs) are becoming increasingly powerful, they still exhibit significant but subtle weaknesses, such as mistakes in instruction-following or coding tasks. As these unexpected errors could lead to severe consequences in practical deployments, it is crucial to investigate the limitations within LLMs systematically. Traditional benchmarking approaches cannot thoroughly pinpoint specific model deficiencies, while manual inspections are costly and not scalable. In this paper, we introduce a unified framework, AutoDetect, to automatically expose weaknesses in LLMs across various tasks. Inspired by the educational assessment process that measures students' learning outcomes, AutoDetect consists of three LLM-powered agents: Examiner, Questioner, and Assessor. The collaboration among these three agents is designed to realize comprehensive and in-depth weakness identification. Our framework demonstrates significant success in uncovering flaws, with an identification success rate exceeding 30% in prominent models such as ChatGPT and Claude. More importantly, these identified weaknesses can guide specific model improvements, proving more effective than untargeted data augmentation methods like Self-Instruct. Our approach has led to substantial enhancements in popular LLMs, including the Llama series and Mistral-7b, boosting their performance by over 10% across several benchmarks. Code and data are publicly available at https://github.com/thu-coai/AutoDetect.
Create account to get full access
Related Work
Weakness Detection in Large Language Models
Researchers have explored various approaches to detecting weaknesses and vulnerabilities in large language models (LLMs). Several papers have proposed techniques for this:
Harnessing Large Language Models for Software Vulnerability Detection presents a method that leverages LLMs to identify software vulnerabilities in code.
VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection in Large Language Models introduces a benchmark dataset and evaluation framework for assessing the ability of LLMs to detect vulnerabilities.
Leveraging Large Language Models for Efficient Failure Analysis demonstrates how LLMs can be used to automate the process of analyzing software failures.
LUNA: A Model-based Universal Analysis Framework for Large Language Models proposes a general framework for analyzing LLMs and identifying their weaknesses.
Security Code Review by Large Language Models explores using LLMs to assist in the security review of software code.
These papers provide valuable insights and techniques for the automated detection of weaknesses in large language models, which is the focus of the current work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study
Karl Tamberg, Hayretdin Bahsi
0
0
Despite various approaches being employed to detect vulnerabilities, the number of reported vulnerabilities shows an upward trend over the years. This suggests the problems are not caught before the code is released, which could be caused by many factors, like lack of awareness, limited efficacy of the existing vulnerability detection tools or the tools not being user-friendly. To help combat some issues with traditional vulnerability detection tools, we propose using large language models (LLMs) to assist in finding vulnerabilities in source code. LLMs have shown a remarkable ability to understand and generate code, underlining their potential in code-related tasks. The aim is to test multiple state-of-the-art LLMs and identify the best prompting strategies, allowing extraction of the best value from the LLMs. We provide an overview of the strengths and weaknesses of the LLM-based approach and compare the results to those of traditional static analysis tools. We find that LLMs can pinpoint many more issues than traditional static analysis tools, outperforming traditional tools in terms of recall and F1 scores. The results should benefit software developers and security analysts responsible for ensuring that the code is free of vulnerabilities.
5/27/2024
VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models
Yu Liu, Lang Gao, Mingxin Yang, Yu Xie, Ping Chen, Xiaojin Zhang, Wei Chen
0
0
Large Language Models (LLMs) have training corpora containing large amounts of program code, greatly improving the model's code comprehension and generation capabilities. However, sound comprehensive research on detecting program vulnerabilities, a more specific task related to code, and evaluating the performance of LLMs in this more specialized scenario is still lacking. To address common challenges in vulnerability analysis, our study introduces a new benchmark, VulDetectBench, specifically designed to assess the vulnerability detection capabilities of LLMs. The benchmark comprehensively evaluates LLM's ability to identify, classify, and locate vulnerabilities through five tasks of increasing difficulty. We evaluate the performance of 17 models (both open- and closed-source) and find that while existing models can achieve over 80% accuracy on tasks related to vulnerability identification and classification, they still fall short on specific, more detailed vulnerability analysis tasks, with less than 30% accuracy, making it difficult to provide valuable auxiliary information for professional vulnerability mining. Our benchmark effectively evaluates the capabilities of various LLMs at different levels in the specific task of vulnerability detection, providing a foundation for future research and improvements in this critical area of code security. VulDetectBench is publicly available at https://github.com/Sweetaroo/VulDetectBench.
6/26/2024
💬
LUNA: A Model-Based Universal Analysis Framework for Large Language Models
Da Song, Xuan Xie, Jiayang Song, Derui Zhu, Yuheng Huang, Felix Juefei-Xu, Lei Ma
0
0
Over the past decade, Artificial Intelligence (AI) has had great success recently and is being used in a wide range of academic and industrial fields. More recently, LLMs have made rapid advancements that have propelled AI to a new level, enabling even more diverse applications and industrial domains with intelligence, particularly in areas like software engineering and natural language processing. Nevertheless, a number of emerging trustworthiness concerns and issues exhibited in LLMs have already recently received much attention, without properly solving which the widespread adoption of LLMs could be greatly hindered in practice. The distinctive characteristics of LLMs, such as the self-attention mechanism, extremely large model scale, and autoregressive generation schema, differ from classic AI software based on CNNs and RNNs and present new challenges for quality analysis. Up to the present, it still lacks universal and systematic analysis techniques for LLMs despite the urgent industrial demand. Towards bridging this gap, we initiate an early exploratory study and propose a universal analysis framework for LLMs, LUNA, designed to be general and extensible, to enable versatile analysis of LLMs from multiple quality perspectives in a human-interpretable manner. In particular, we first leverage the data from desired trustworthiness perspectives to construct an abstract model as an auxiliary analysis asset, which is empowered by various abstract model construction methods. To assess the quality of the abstract model, we collect and define a number of evaluation metrics, aiming at both abstract model level and the semantics level. Then, the semantics, which is the degree of satisfaction of the LLM w.r.t. the trustworthiness perspective, is bound to and enriches the abstract model with semantics, which enables more detailed analysis applications for diverse purposes.
6/17/2024

Leveraging Large Language Models for Efficient Failure Analysis in Game Development
Leonardo Marini, Linus Gissl'en, Alessandro Sestini
0
0
In games, and more generally in the field of software development, early detection of bugs is vital to maintain a high quality of the final product. Automated tests are a powerful tool that can catch a problem earlier in development by executing periodically. As an example, when new code is submitted to the code base, a new automated test verifies these changes. However, identifying the specific change responsible for a test failure becomes harder when dealing with batches of changes -- especially in the case of a large-scale project such as a AAA game, where thousands of people contribute to a single code base. This paper proposes a new approach to automatically identify which change in the code caused a test to fail. The method leverages Large Language Models (LLMs) to associate error messages with the corresponding code changes causing the failure. We investigate the effectiveness of our approach with quantitative and qualitative evaluations. Our approach reaches an accuracy of 71% in our newly created dataset, which comprises issues reported by developers at EA over a period of one year. We further evaluated our model through a user study to assess the utility and usability of the tool from a developer perspective, resulting in a significant reduction in time -- up to 60% -- spent investigating issues.
6/12/2024