Leveraging LLM-Respondents for Item Evaluation: a Psychometric Analysis

0

Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) as respondents for evaluating test items, and analyzes the psychometric properties of this approach.
- The researchers investigate whether LLMs can provide reliable and valid feedback on the quality of test items, which could potentially streamline the item evaluation process.
- The paper includes an empirical study that compares item ratings from human experts and LLM-generated responses, and examines the psychometric qualities of the LLM-based evaluations.
Plain English Explanation
The research paper looks at using large language models (LLMs) - powerful AI systems that can generate human-like text - as "respondents" to evaluate test items or questions. The goal is to see if LLMs can provide reliable and valid feedback on the quality of test items, which could make the item evaluation process more efficient.
The researchers conducted a study where they compared item ratings from human experts to the ratings generated by an LLM. They wanted to see how well the LLM-based evaluations matched the expert assessments, and whether the LLM-generated feedback had the same psychometric properties (e.g., consistency, accuracy) as human evaluations.
The idea is that if LLMs can reliably and accurately assess test items, they could potentially be used to streamline the item evaluation process, which is typically done by human experts. This could save time and resources, especially for tests and assessments that require a large number of items to be reviewed.
Technical Explanation
The paper investigates the use of LLMs as "respondents" to evaluate the psychometric properties of test items. The researchers conducted an empirical study where they compared item ratings from human experts to the ratings generated by an LLM model.
Specifically, the study used the Unibuc-LLM model to provide item ratings, and compared these to ratings from a panel of human experts. The researchers analyzed the psychometric qualities of the LLM-generated ratings, including their consistency, accuracy, and alignment with the expert assessments.
The findings suggest that LLMs can provide reliable and valid feedback on the quality of test items, with the LLM-based ratings showing strong psychometric properties that are comparable to human evaluations. This indicates that LLMs may be a viable alternative to human experts for certain item evaluation tasks, potentially streamlining the assessment development process.
The paper builds on prior research in this area, such as studies exploring the limitations of LLMs in simulating human psychological processes, using LLMs for automated prediction of item difficulty, and generating and evaluating reading comprehension test items with LLMs.
Critical Analysis
The paper provides a well-designed empirical study and a thorough psychometric analysis of using LLMs for item evaluation. However, there are a few important caveats and limitations to consider:
-
The study only used a single LLM (Unibuc-LLM) and focused on a specific type of test items. More research is needed to see how well the findings generalize to other LLMs and item types.
-
The paper does not address potential biases or inconsistencies that may arise in LLM-generated item ratings, which could be a concern given the challenges in validating the outputs of large language models.
-
While the LLM-based approach may streamline item evaluation, there are still open questions about how well LLMs can capture the nuanced, context-dependent judgments that human experts bring to the assessment development process.
-
The study does not explore the potential limitations of using LLMs to evaluate open-ended student responses, which may require more advanced natural language understanding capabilities.
Overall, the paper presents an interesting and promising approach, but further research is needed to fully understand the strengths, weaknesses, and appropriate use cases of LLMs for item evaluation and assessment development.
Conclusion
This research paper explores the use of large language models (LLMs) as respondents for evaluating test items, and analyzes the psychometric properties of this approach. The key finding is that LLMs can provide reliable and valid feedback on the quality of test items, with the LLM-generated ratings showing strong psychometric qualities comparable to human expert evaluations.
This suggests that LLMs may be a viable alternative to human experts for certain item evaluation tasks, potentially streamlining the assessment development process. However, there are important caveats and limitations that need to be further explored, such as potential biases, the generalizability to different LLMs and item types, and the ability to capture the nuanced judgments of human experts.
Overall, the paper presents an innovative approach that could have significant implications for the efficient and scalable development of high-quality assessments. As the capabilities of LLMs continue to advance, there will likely be growing interest in exploring their potential applications in the field of psychometrics and educational measurement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging LLM-Respondents for Item Evaluation: a Psychometric Analysis
Yunting Liu, Shreya Bhandari, Zachary A. Pardos
Effective educational measurement relies heavily on the curation of well-designed item pools (i.e., possessing the right psychometric properties). However, item calibration is time-consuming and costly, requiring a sufficient number of respondents for the response process. We explore using six different LLMs (GPT-3.5, GPT-4, Llama 2, Llama 3, Gemini-Pro, and Cohere Command R Plus) and various combinations of them using sampling methods to produce responses with psychometric properties similar to human answers. Results show that some LLMs have comparable or higher proficiency in College Algebra than college students. No single LLM mimics human respondents due to narrow proficiency distributions, but an ensemble of LLMs can better resemble college students' ability distribution. The item parameters calibrated by LLM-Respondents have high correlations (e.g. > 0.8 for GPT-3.5) compared to their human calibrated counterparts, and closely resemble the parameters of the human subset (e.g. 0.02 Spearman correlation difference). Several augmentation strategies are evaluated for their relative performance, with resampling methods proving most effective, enhancing the Spearman correlation from 0.89 (human only) to 0.93 (augmented human).
Read more7/16/2024
🏷️
0
Limited Ability of LLMs to Simulate Human Psychological Behaviours: a Psychometric Analysis
Nikolay B Petrov, Gregory Serapio-Garc'ia, Jason Rentfrow
The humanlike responses of large language models (LLMs) have prompted social scientists to investigate whether LLMs can be used to simulate human participants in experiments, opinion polls and surveys. Of central interest in this line of research has been mapping out the psychological profiles of LLMs by prompting them to respond to standardized questionnaires. The conflicting findings of this research are unsurprising given that mapping out underlying, or latent, traits from LLMs' text responses to questionnaires is no easy task. To address this, we use psychometrics, the science of psychological measurement. In this study, we prompt OpenAI's flagship models, GPT-3.5 and GPT-4, to assume different personas and respond to a range of standardized measures of personality constructs. We used two kinds of persona descriptions: either generic (four or five random person descriptions) or specific (mostly demographics of actual humans from a large-scale human dataset). We found that the responses from GPT-4, but not GPT-3.5, using generic persona descriptions show promising, albeit not perfect, psychometric properties, similar to human norms, but the data from both LLMs when using specific demographic profiles, show poor psychometrics properties. We conclude that, currently, when LLMs are asked to simulate silicon personas, their responses are poor signals of potentially underlying latent traits. Thus, our work casts doubt on LLMs' ability to simulate individual-level human behaviour across multiple-choice question answering tasks.
Read more5/14/2024
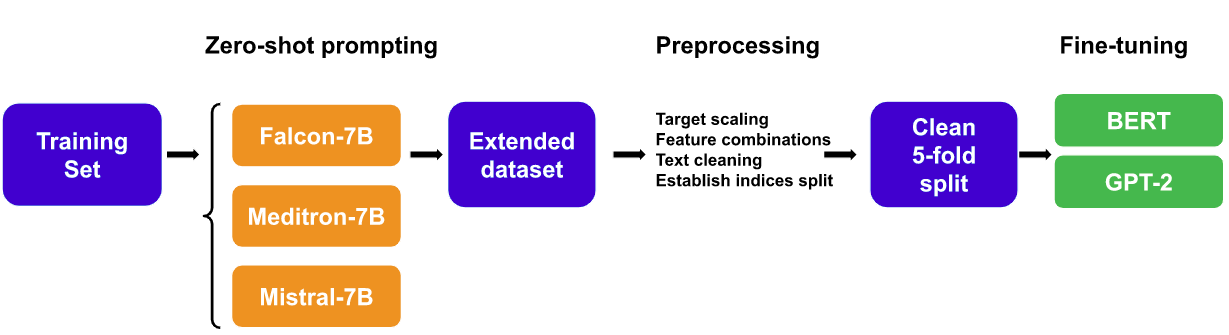
0
UnibucLLM: Harnessing LLMs for Automated Prediction of Item Difficulty and Response Time for Multiple-Choice Questions
Ana-Cristina Rogoz, Radu Tudor Ionescu
This work explores a novel data augmentation method based on Large Language Models (LLMs) for predicting item difficulty and response time of retired USMLE Multiple-Choice Questions (MCQs) in the BEA 2024 Shared Task. Our approach is based on augmenting the dataset with answers from zero-shot LLMs (Falcon, Meditron, Mistral) and employing transformer-based models based on six alternative feature combinations. The results suggest that predicting the difficulty of questions is more challenging. Notably, our top performing methods consistently include the question text, and benefit from the variability of LLM answers, highlighting the potential of LLMs for improving automated assessment in medical licensing exams. We make our code available https://github.com/ana-rogoz/BEA-2024.
Read more4/23/2024

0
Psychometric Alignment: Capturing Human Knowledge Distributions via Language Models
Joy He-Yueya, Wanjing Anya Ma, Kanishk Gandhi, Benjamin W. Domingue, Emma Brunskill, Noah D. Goodman
Language models (LMs) are increasingly used to simulate human-like responses in scenarios where accurately mimicking a population's behavior can guide decision-making, such as in developing educational materials and designing public policies. The objective of these simulations is for LMs to capture the variations in human responses, rather than merely providing the expected correct answers. Prior work has shown that LMs often generate unrealistically accurate responses, but there are no established metrics to quantify how closely the knowledge distribution of LMs aligns with that of humans. To address this, we introduce psychometric alignment, a metric that measures the extent to which LMs reflect human knowledge distribution. Assessing this alignment involves collecting responses from both LMs and humans to the same set of test items and using Item Response Theory to analyze the differences in item functioning between the groups. We demonstrate that our metric can capture important variations in populations that traditional metrics, like differences in accuracy, fail to capture. We apply this metric to assess existing LMs for their alignment with human knowledge distributions across three real-world domains. We find significant misalignment between LMs and human populations, though using persona-based prompts can improve alignment. Interestingly, smaller LMs tend to achieve greater psychometric alignment than larger LMs. Further, training LMs on human response data from the target distribution enhances their psychometric alignment on unseen test items, but the effectiveness of such training varies across domains.
Read more7/23/2024