Leveraging Sub-Optimal Data for Human-in-the-Loop Reinforcement Learning

0
Sign in to get full access
Overview
• This paper explores a novel approach to leveraging sub-optimal data for human-in-the-loop reinforcement learning (RL), which aims to improve the performance of AI systems by incorporating feedback from human users.
• The researchers propose a technique that can effectively utilize suboptimal demonstrations and preference feedback from humans to guide the RL agent towards better policies, even when the human input is not always perfect or consistent.
• The method, called Contrastive Preference Learning, combines human preferences with an exploration strategy to efficiently learn reward functions that capture the user's true intentions.
Plain English Explanation
The paper presents a way to use imperfect or incomplete feedback from humans to help train reinforcement learning (RL) systems. RL is a type of machine learning where an AI agent learns to make decisions by trial and error, getting feedback on whether its actions were good or bad.
Traditionally, RL agents are trained using carefully curated data that shows the optimal actions to take. However, in the real world, humans may provide feedback that is not always perfect or fully consistent. This paper shows how to use even this messy, sub-optimal human feedback to help the RL agent learn better policies.
The key idea is to use "contrastive preference learning" - this means comparing the agent's current behavior to the human's feedback, and then updating the agent's reward function to steer it towards actions the human prefers, even if the human feedback is imperfect. The agent also explores the environment intelligently to find even better actions that the human might like, rather than just blindly following the flawed human guidance.
By leveraging this sub-optimal human data, the researchers demonstrate that RL agents can learn effective policies more efficiently, without needing perfectly curated training data. This could make RL systems more practical and accessible in real-world applications that rely on human input.
Technical Explanation
The paper introduces a novel framework called Contrastive Preference Learning that can effectively utilize suboptimal human demonstrations and preference feedback to guide the reinforcement learning agent towards better policies.
The key components of the approach are:
-
Preference Modeling: The agent learns a reward function that captures the human's preferences by contrasting the agent's current behavior with the human feedback. This allows the agent to infer the user's true intentions, even when the feedback is noisy or inconsistent.
-
Exploration Strategy: The agent uses an exploration strategy that intelligently explores the environment to find actions that are likely to be preferred by the human, rather than just blindly following the suboptimal human guidance.
-
Iterative Learning: The agent iterates between improving its reward function based on human feedback and then using that reward function to update its policy, gradually converging towards an optimal policy that aligns with the human's preferences.
The researchers evaluate their approach on a range of simulated environments and demonstrate that it can significantly outperform baseline methods that rely on perfect human data or ignore the exploration-exploitation trade-off. The results suggest that Contrastive Preference Learning is a promising technique for incorporating realistic, imperfect human feedback into reinforcement learning systems.
Critical Analysis
The paper presents a compelling approach for leveraging sub-optimal human data to improve reinforcement learning, addressing an important challenge in the field of human-in-the-loop RL.
One potential limitation is that the method assumes the human feedback can be represented as a relative preference between the agent's actions, rather than a more general reward signal. In some cases, humans may provide feedback that is better modeled as an absolute reward function, rather than just pairwise preferences.
Additionally, the paper focuses on simulated environments, and further research would be needed to understand how well the approach scales to real-world, high-dimensional problems. Integrating this method with other techniques for reward modeling and preference learning could also be a fruitful area for future work.
Overall, the Contrastive Preference Learning approach represents an important step forward in making reinforcement learning systems more robust and practical by effectively utilizing the imperfect but valuable feedback that humans can provide.
Conclusion
This paper presents a novel technique called Contrastive Preference Learning that enables reinforcement learning agents to efficiently leverage suboptimal human demonstrations and preference feedback to learn better policies.
By modeling human preferences through a contrastive approach and using an intelligent exploration strategy, the method can outperform baseline techniques that rely on perfect human data or ignore the exploration-exploitation trade-off. This research represents an important advancement in the field of human-in-the-loop reinforcement learning, paving the way for more practical and effective AI systems that can learn from real-world, imperfect human feedback.
The insights from this work could also have broader implications for reward modeling and preference learning in reinforcement learning, potentially helping to address challenges around reward overoptimization and building AI systems that are better aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging Sub-Optimal Data for Human-in-the-Loop Reinforcement Learning
Calarina Muslimani, Matthew E. Taylor
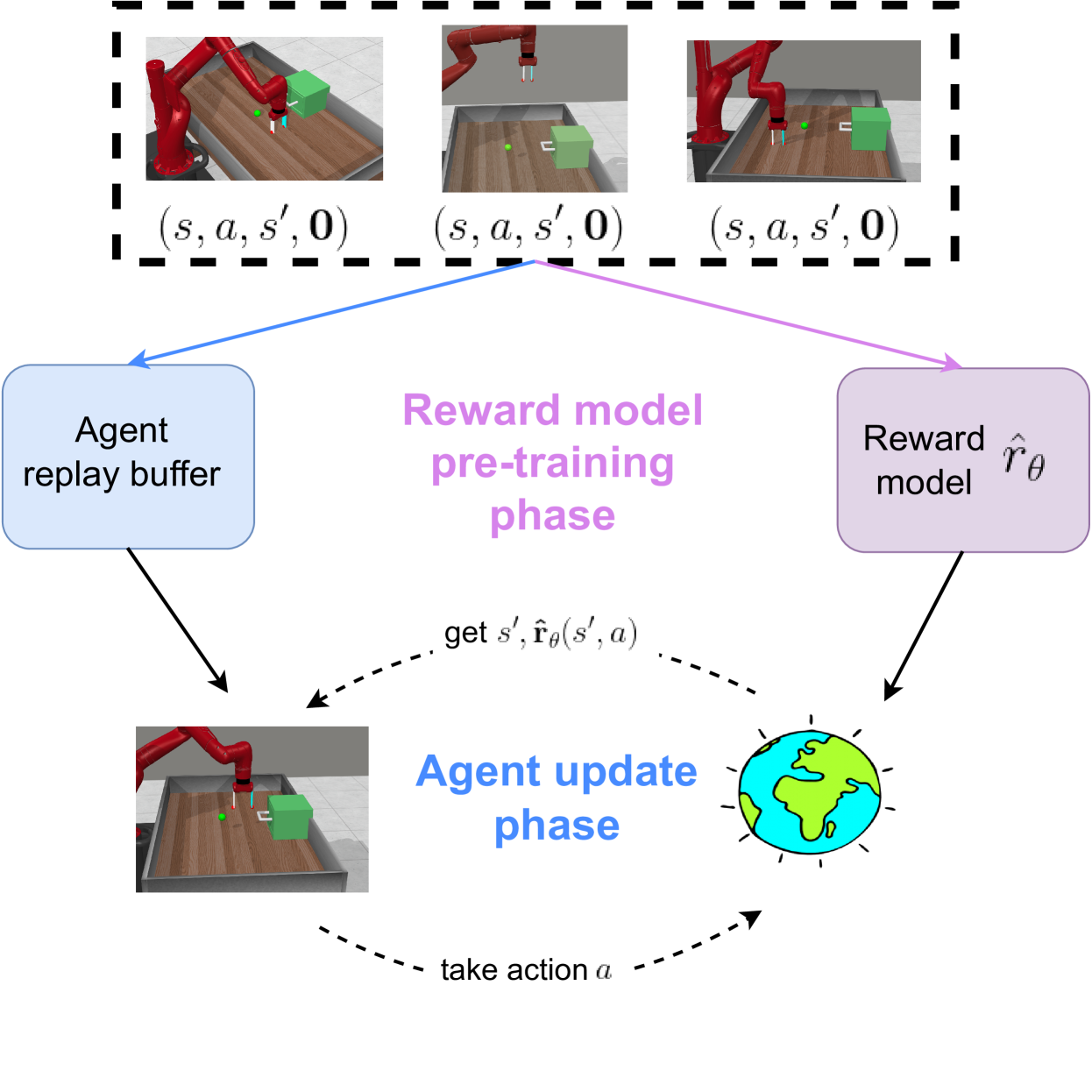
To create useful reinforcement learning (RL) agents, step zero is to design a suitable reward function that captures the nuances of the task. However, reward engineering can be a difficult and time-consuming process. Instead, human-in-the-loop (HitL) RL allows agents to learn reward functions from human feedback. Despite recent successes, many of the HitL RL methods still require numerous human interactions to learn successful reward functions. To improve the feedback efficiency of HitL RL methods (i.e., require less feedback), this paper introduces Sub-optimal Data Pre-training, SDP, an approach that leverages reward-free, sub-optimal data to improve scalar- and preference-based HitL RL algorithms. In SDP, we start by pseudo-labeling all low-quality data with rewards of zero. Through this process, we obtain free reward labels to pre-train our reward model. This pre-training phase provides the reward model a head start in learning, whereby it can identify that low-quality transitions should have a low reward, all without any actual feedback. Through extensive experiments with a simulated teacher, we demonstrate that SDP can significantly improve or achieve competitive performance with state-of-the-art (SOTA) HitL RL algorithms across nine robotic manipulation and locomotion tasks.
Read more5/3/2024
📶
0
Contrastive Preference Learning: Learning from Human Feedback without RL
Joey Hejna, Rafael Rafailov, Harshit Sikchi, Chelsea Finn, Scott Niekum, W. Bradley Knox, Dorsa Sadigh
Reinforcement Learning from Human Feedback (RLHF) has emerged as a popular paradigm for aligning models with human intent. Typically RLHF algorithms operate in two phases: first, use human preferences to learn a reward function and second, align the model by optimizing the learned reward via reinforcement learning (RL). This paradigm assumes that human preferences are distributed according to reward, but recent work suggests that they instead follow the regret under the user's optimal policy. Thus, learning a reward function from feedback is not only based on a flawed assumption of human preference, but also leads to unwieldy optimization challenges that stem from policy gradients or bootstrapping in the RL phase. Because of these optimization challenges, contemporary RLHF methods restrict themselves to contextual bandit settings (e.g., as in large language models) or limit observation dimensionality (e.g., state-based robotics). We overcome these limitations by introducing a new family of algorithms for optimizing behavior from human feedback using the regret-based model of human preferences. Using the principle of maximum entropy, we derive Contrastive Preference Learning (CPL), an algorithm for learning optimal policies from preferences without learning reward functions, circumventing the need for RL. CPL is fully off-policy, uses only a simple contrastive objective, and can be applied to arbitrary MDPs. This enables CPL to elegantly scale to high-dimensional and sequential RLHF problems while being simpler than prior methods.
Read more5/1/2024

0
Adaptive Preference Scaling for Reinforcement Learning with Human Feedback
Ilgee Hong, Zichong Li, Alexander Bukharin, Yixiao Li, Haoming Jiang, Tianbao Yang, Tuo Zhao
Reinforcement learning from human feedback (RLHF) is a prevalent approach to align AI systems with human values by learning rewards from human preference data. Due to various reasons, however, such data typically takes the form of rankings over pairs of trajectory segments, which fails to capture the varying strengths of preferences across different pairs. In this paper, we propose a novel adaptive preference loss, underpinned by distributionally robust optimization (DRO), designed to address this uncertainty in preference strength. By incorporating an adaptive scaling parameter into the loss for each pair, our method increases the flexibility of the reward function. Specifically, it assigns small scaling parameters to pairs with ambiguous preferences, leading to more comparable rewards, and large scaling parameters to those with clear preferences for more distinct rewards. Computationally, our proposed loss function is strictly convex and univariate with respect to each scaling parameter, enabling its efficient optimization through a simple second-order algorithm. Our method is versatile and can be readily adapted to various preference optimization frameworks, including direct preference optimization (DPO). Our experiments with robotic control and natural language generation with large language models (LLMs) show that our method not only improves policy performance but also aligns reward function selection more closely with policy optimization, simplifying the hyperparameter tuning process.
Read more6/6/2024
🐍
0
A Unified Linear Programming Framework for Offline Reward Learning from Human Demonstrations and Feedback
Kihyun Kim, Jiawei Zhang, Asuman Ozdaglar, Pablo A. Parrilo
Inverse Reinforcement Learning (IRL) and Reinforcement Learning from Human Feedback (RLHF) are pivotal methodologies in reward learning, which involve inferring and shaping the underlying reward function of sequential decision-making problems based on observed human demonstrations and feedback. Most prior work in reward learning has relied on prior knowledge or assumptions about decision or preference models, potentially leading to robustness issues. In response, this paper introduces a novel linear programming (LP) framework tailored for offline reward learning. Utilizing pre-collected trajectories without online exploration, this framework estimates a feasible reward set from the primal-dual optimality conditions of a suitably designed LP, and offers an optimality guarantee with provable sample efficiency. Our LP framework also enables aligning the reward functions with human feedback, such as pairwise trajectory comparison data, while maintaining computational tractability and sample efficiency. We demonstrate that our framework potentially achieves better performance compared to the conventional maximum likelihood estimation (MLE) approach through analytical examples and numerical experiments.
Read more6/5/2024