Leveraging Web-Crawled Data for High-Quality Fine-Tuning

0
📊
Sign in to get full access
Overview
- Large language models often rely on expensive human-annotated data or data generated by advanced models like GPT-4, which can have limitations in certain domains.
- The researchers argue that web-crawled data, despite formatting errors and semantic inaccuracies, can still be a valuable source for high-quality supervised fine-tuning in specific domains without advanced models.
- They create a paired training dataset by automatically aligning web-crawled data with a smaller set of high-quality data, allowing a language model to transform the web data into a higher quality format.
Plain English Explanation
The researchers believe that even though web-crawled data often has formatting and accuracy issues, it can still be a useful source for training language models in specific areas. This can be valuable when compared to relying on expensive human-annotated data or data generated by advanced models like GPT-4, which may have limitations in certain domains.
To take advantage of web-crawled data, the researchers automatically created a paired training dataset. They aligned the web-crawled data with a smaller set of high-quality data, allowing a language model to learn how to transform the web data into a more accurate and consistent format. This approach avoids the need for advanced models like GPT-4 and can produce better results than using only the high-quality data.
Technical Explanation
The researchers created a paired training dataset by automatically aligning web-crawled data with a smaller set of high-quality data. They then trained a language model on this dataset, allowing the model to learn how to convert the web data with irregular formats into a higher-quality format.
Their experiments showed that training with the model-transformed data yielded better results, surpassing training with only high-quality data by an average score of 9.4% on Chinese math problems. Additionally, their 7-billion-parameter model outperformed several open-source models larger than 32 billion parameters, as well as well-known closed-source models like GPT-3.5. This highlights the effectiveness of their approach in leveraging web-crawled data for fine-tuning language models.
Critical Analysis
The researchers acknowledge that web-crawled data often has formatting errors and semantic inaccuracies, which can lead to issues in certain domains. However, they demonstrate that by aligning this data with a smaller set of high-quality data, a language model can be trained to transform the web data into a more consistent and accurate format.
While the researchers' approach shows promising results, it is important to consider potential limitations and areas for further research. For example, the effectiveness of this method may depend on the specific domain and the quality of the high-quality data used for alignment. Additionally, the researchers do not address potential biases or fairness concerns that could arise from using web-crawled data, which may reflect societal biases.
Conclusion
The researchers have demonstrated a novel approach to leveraging web-crawled data for fine-tuning language models, even in the face of formatting errors and semantic inaccuracies. By automatically aligning this data with a smaller set of high-quality data, they have shown that a language model can be trained to transform the web data into a more consistent and accurate format.
This work highlights the potential of using web-crawled data as a valuable resource for language model fine-tuning, without relying on expensive human-annotated data or advanced models like GPT-4. The researchers' findings suggest that this approach can yield better results than using only high-quality data, potentially opening up new avenues for language model development and deployment in specific domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Leveraging Web-Crawled Data for High-Quality Fine-Tuning
Jing Zhou, Chenglin Jiang, Wei Shen, Xiao Zhou, Xiaonan He
Most large language models are fine-tuned using either expensive human-annotated data or GPT-4 generated data which cannot guarantee performance in certain domains. We argue that although the web-crawled data often has formatting errors causing semantic inaccuracies, it can still serve as a valuable source for high-quality supervised fine-tuning in specific domains without relying on advanced models like GPT-4. To this end, we create a paired training dataset automatically by aligning web-crawled data with a smaller set of high-quality data. By training a language model on this dataset, we can convert web data with irregular formats into high-quality ones. Our experiments show that training with the model-transformed data yields better results, surpassing training with only high-quality data by an average score of 9.4% in Chinese math problems. Additionally, our 7B model outperforms several open-source models larger than 32B and surpasses well-known closed-source models such as GPT-3.5, highlighting the efficacy of our approach.
Read more8/16/2024

0
Introducing the NewsPaLM MBR and QE Dataset: LLM-Generated High-Quality Parallel Data Outperforms Traditional Web-Crawled Data
Mara Finkelstein, David Vilar, Markus Freitag
Recent research in neural machine translation (NMT) has shown that training on high-quality machine-generated data can outperform training on human-generated data. This work accompanies the first-ever release of a LLM-generated, MBR-decoded and QE-reranked dataset with both sentence-level and multi-sentence examples. We perform extensive experiments to demonstrate the quality of our dataset in terms of its downstream impact on NMT model performance. We find that training from scratch on our (machine-generated) dataset outperforms training on the (web-crawled) WMT'23 training dataset (which is 300 times larger), and also outperforms training on the top-quality subset of the WMT'23 training dataset. We also find that performing self-distillation by finetuning the LLM which generated this dataset outperforms the LLM's strong few-shot baseline. These findings corroborate the quality of our dataset, and demonstrate the value of high-quality machine-generated data in improving performance of NMT models.
Read more8/22/2024
0
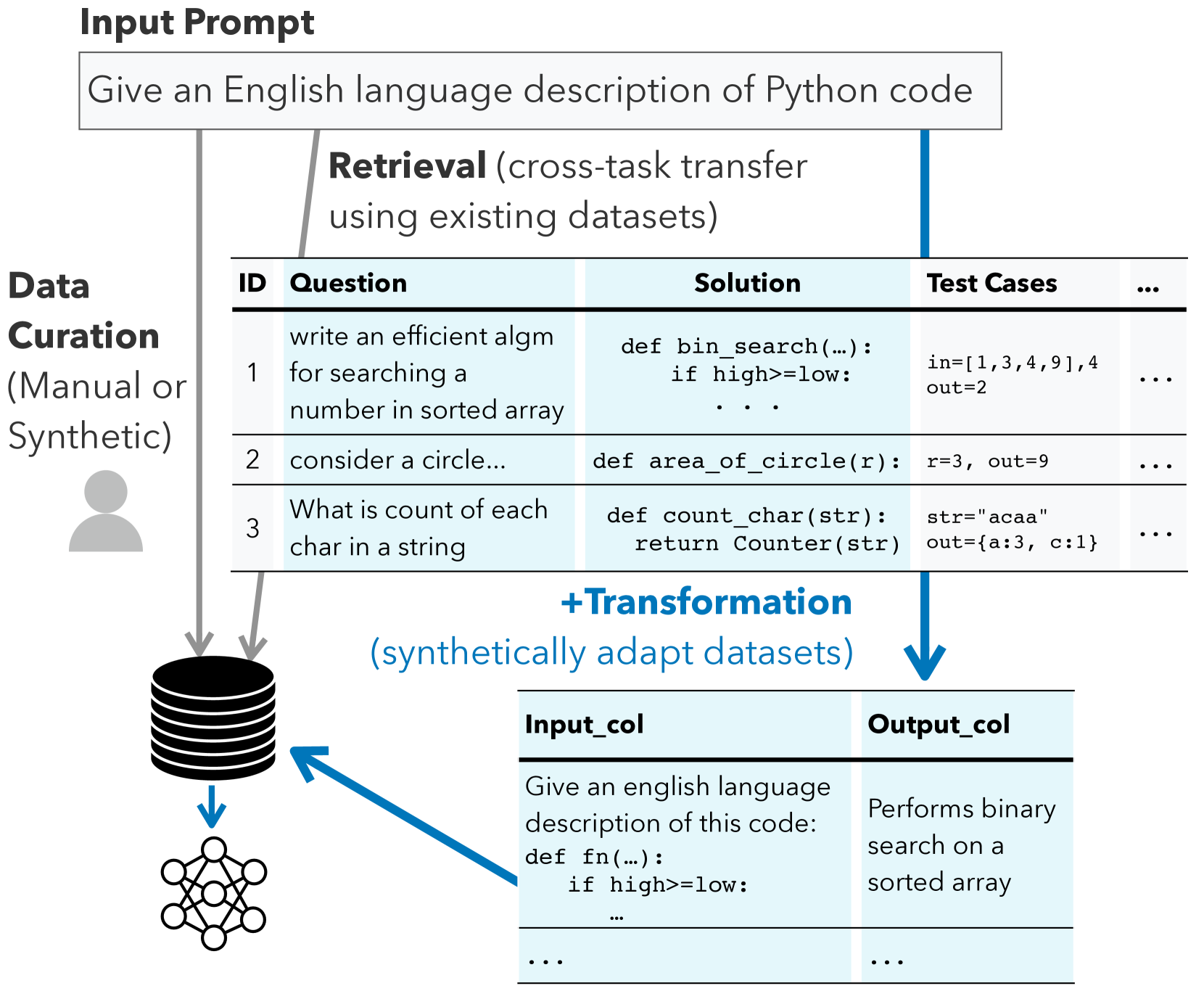
Better Synthetic Data by Retrieving and Transforming Existing Datasets
Saumya Gandhi, Ritu Gala, Vijay Viswanathan, Tongshuang Wu, Graham Neubig
Despite recent advances in large language models, building dependable and deployable NLP models typically requires abundant, high-quality training data. However, task-specific data is not available for many use cases, and manually curating task-specific data is labor-intensive. Recent work has studied prompt-driven synthetic data generation using large language models, but these generated datasets tend to lack complexity and diversity. To address these limitations, we introduce a method, DataTune, to make better use of existing, publicly available datasets to improve automatic dataset generation. DataTune performs dataset transformation, enabling the repurposing of publicly available datasets into a format that is directly aligned with the specific requirements of target tasks. On a diverse set of language-based tasks from the BIG-Bench benchmark, we find that finetuning language models via DataTune improves over a few-shot prompting baseline by 49% and improves over existing methods that use synthetic or retrieved training data by 34%. We find that dataset transformation significantly increases the diversity and difficulty of generated data on many tasks. We integrate DataTune into an open-source repository to make this method accessible to the community: https://github.com/neulab/prompt2model.
Read more4/30/2024
0
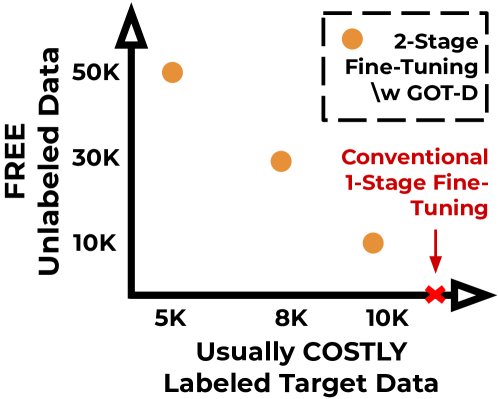
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
Feiyang Kang, Hoang Anh Just, Yifan Sun, Himanshu Jahagirdar, Yuanzhi Zhang, Rongxing Du, Anit Kumar Sahu, Ruoxi Jia
This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
Read more5/7/2024