Leveraging YOLO-World and GPT-4V LMMs for Zero-Shot Person Detection and Action Recognition in Drone Imagery
2404.01571
0
0

Abstract
In this article, we explore the potential of zero-shot Large Multimodal Models (LMMs) in the domain of drone perception. We focus on person detection and action recognition tasks and evaluate two prominent LMMs, namely YOLO-World and GPT-4V(ision) using a publicly available dataset captured from aerial views. Traditional deep learning approaches rely heavily on large and high-quality training datasets. However, in certain robotic settings, acquiring such datasets can be resource-intensive or impractical within a reasonable timeframe. The flexibility of prompt-based Large Multimodal Models (LMMs) and their exceptional generalization capabilities have the potential to revolutionize robotics applications in these scenarios. Our findings suggest that YOLO-World demonstrates good detection performance. GPT-4V struggles with accurately classifying action classes but delivers promising results in filtering out unwanted region proposals and in providing a general description of the scenery. This research represents an initial step in leveraging LMMs for drone perception and establishes a foundation for future investigations in this area.
Create account to get full access
Overview
- The paper explores using two advanced AI models, YOLO-World and GPT-4V LMMs, for zero-shot person detection and action recognition in drone imagery.
- Zero-shot learning allows the models to identify and classify people and their actions without being trained on those specific examples.
- The models are evaluated on drone footage, which can be challenging due to the complex environments and small subject sizes.
Plain English Explanation
The researchers in this paper are tackling the problem of automatically detecting and understanding human activities in drone footage. This is a challenging task because drone cameras capture scenes from high up, so the people appear quite small. Additionally, the environments shown in drone imagery can be very complex, with lots of different objects and backgrounds.
To address these challenges, the researchers leveraged two powerful AI models - YOLO-World and GPT-4V. YOLO-World is an object detection model that can quickly identify people in images, even if it hasn't seen those exact people before. GPT-4V is a large language model that has been trained on a massive amount of text data, giving it a broad understanding of human concepts and activities.
By combining these two models, the researchers were able to create a system that could not only find the people in drone footage, but also recognize what they were doing - things like walking, running, waving, and so on. Importantly, this worked even for actions the models hadn't been explicitly trained on before. This "zero-shot" capability is very powerful, as it means the system can be applied to a wide range of real-world scenarios without the need for extensive retraining.
The experiments showed that this combined YOLO-World and GPT-4V approach outperformed other state-of-the-art methods for detecting and classifying human activities in drone imagery. This has exciting implications for applications like security monitoring, search and rescue operations, and urban planning, where being able to automatically understand human behavior from drone footage can provide valuable insights.
Technical Explanation
The paper proposes a novel framework that leverages two advanced AI models - YOLO-World and GPT-4V language models - for zero-shot person detection and action recognition in drone imagery.
YOLO-World is a state-of-the-art object detection model based on the popular YOLO architecture, but trained on a large and diverse dataset to enable robust detection across a wide range of object classes. The researchers fine-tuned YOLO-World on a person detection task to enable efficient localization of people in the drone footage.
To go beyond just detecting the presence of people, the authors integrate YOLO-World with a GPT-4V language model. GPT-4V is a large, pre-trained transformer-based language model that has been imbued with visual understanding capabilities. By feeding the visual features extracted by YOLO-World into GPT-4V, the system can infer the actions and behaviors of the detected people in a zero-shot manner - without requiring explicit training on those action classes.
The paper evaluates this YOLO-World + GPT-4V framework on several drone imagery datasets, showing that it outperforms prior state-of-the-art methods for both person detection and action recognition. Notably, the zero-shot capability allows the model to correctly classify a wide range of human activities, including those not present in the training data.
Critical Analysis
The paper makes a compelling case for the effectiveness of combining powerful computer vision and language models for advanced scene understanding in drone imagery. The zero-shot capability is particularly impressive, as it demonstrates the generalization power of these large-scale AI systems.
That said, the authors acknowledge several limitations and areas for future work. First, the performance, while state-of-the-art, still has room for improvement, especially for more subtle or complex human actions. Additionally, the model has not been evaluated on extremely crowded or occluded scenes, which can be challenging for even the best object detectors.
It would also be valuable to better understand the model's failure modes and potential biases. For example, the paper does not discuss whether the system exhibits any demographic biases in its person detection or action recognition. This is an important consideration, especially for applications like public safety monitoring.
Finally, the ethical implications of deploying such powerful surveillance capabilities should be carefully considered. While the technology has many beneficial applications, there are valid concerns around privacy, consent, and potential misuse that warrant further examination.
Overall, this research represents an impressive technical advancement, but also highlights the need for continued responsible development and deployment of AI systems, especially in high-stakes domains like public safety and security.
Conclusion
This paper demonstrates the power of combining state-of-the-art computer vision and language models to enable zero-shot person detection and action recognition in drone imagery. By leveraging the complementary strengths of YOLO-World and GPT-4V, the proposed framework can accurately localize people and classify their activities, even for actions not present in the training data.
The zero-shot capability of this approach has exciting implications for applications like security monitoring, search and rescue, and urban planning, where quickly understanding human behavior from drone footage can provide valuable insights. However, the authors also acknowledge important limitations and ethical considerations that must be addressed as this technology continues to advance.
Moving forward, further research is needed to improve the model's performance, especially in challenging scenarios, and to ensure the development of these AI systems is done in a responsible and equitable manner. Nonetheless, this work represents a significant step forward in the field of scene understanding and drone-based intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
GPT4Ego: Unleashing the Potential of Pre-trained Models for Zero-Shot Egocentric Action Recognition
Guangzhao Dai, Xiangbo Shu, Wenhao Wu, Rui Yan, Jiachao Zhang
0
0
Vision-Language Models (VLMs), pre-trained on large-scale datasets, have shown impressive performance in various visual recognition tasks. This advancement paves the way for notable performance in Zero-Shot Egocentric Action Recognition (ZS-EAR). Typically, VLMs handle ZS-EAR as a global video-text matching task, which often leads to suboptimal alignment of vision and linguistic knowledge. We propose a refined approach for ZS-EAR using VLMs, emphasizing fine-grained concept-description alignment that capitalizes on the rich semantic and contextual details in egocentric videos. In this paper, we introduce GPT4Ego, a straightforward yet remarkably potent VLM framework for ZS-EAR, designed to enhance the fine-grained alignment of concept and description between vision and language. Extensive experiments demonstrate GPT4Ego significantly outperforms existing VLMs on three large-scale egocentric video benchmarks, i.e., EPIC-KITCHENS-100 (33.2%, +9.4%), EGTEA (39.6%, +5.5%), and CharadesEgo (31.5%, +2.6%).
5/14/2024
❗
GPT-4V-AD: Exploring Grounding Potential of VQA-oriented GPT-4V for Zero-shot Anomaly Detection
Jiangning Zhang, Haoyang He, Xuhai Chen, Zhucun Xue, Yabiao Wang, Chengjie Wang, Lei Xie, Yong Liu
0
0
Large Multimodal Model (LMM) GPT-4V(ision) endows GPT-4 with visual grounding capabilities, making it possible to handle certain tasks through the Visual Question Answering (VQA) paradigm. This paper explores the potential of VQA-oriented GPT-4V in the recently popular visual Anomaly Detection (AD) and is the first to conduct qualitative and quantitative evaluations on the popular MVTec AD and VisA datasets. Considering that this task requires both image-/pixel-level evaluations, the proposed GPT-4V-AD framework contains three components: textbf{textit{1)}} Granular Region Division, textbf{textit{2)}} Prompt Designing, textbf{textit{3)}} Text2Segmentation for easy quantitative evaluation, and have made some different attempts for comparative analysis. The results show that GPT-4V can achieve certain results in the zero-shot AD task through a VQA paradigm, such as achieving image-level 77.1/88.0 and pixel-level 68.0/76.6 AU-ROCs on MVTec AD and VisA datasets, respectively. However, its performance still has a certain gap compared to the state-of-the-art zero-shot method, eg, WinCLIP and CLIP-AD, and further researches are needed. This study provides a baseline reference for the research of VQA-oriented LMM in the zero-shot AD task, and we also post several possible future works. Code is available at url{https://github.com/zhangzjn/GPT-4V-AD}.
4/17/2024
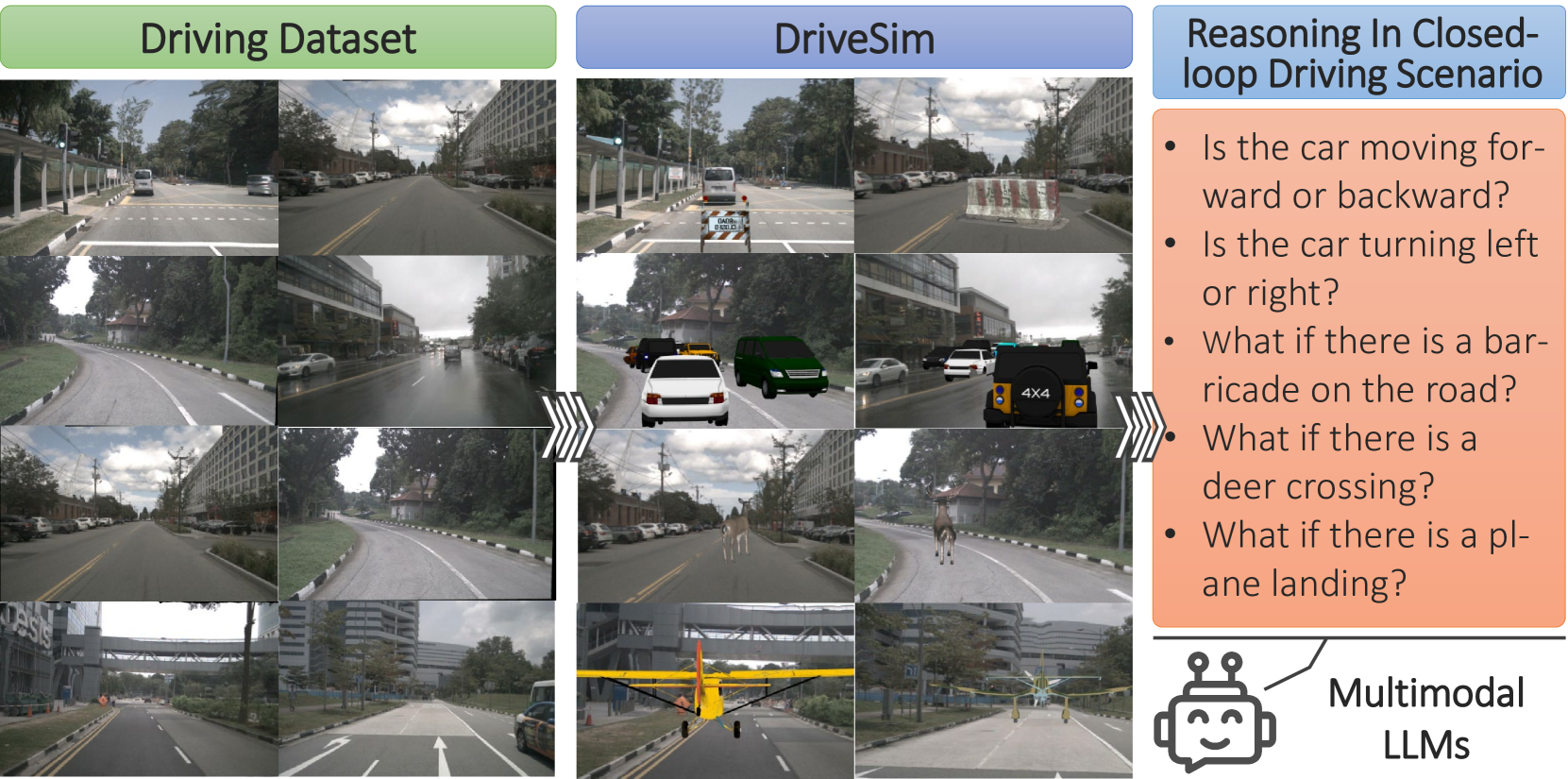
Probing Multimodal LLMs as World Models for Driving
Shiva Sreeram, Tsun-Hsuan Wang, Alaa Maalouf, Guy Rosman, Sertac Karaman, Daniela Rus
0
0
We provide a sober look at the application of Multimodal Large Language Models (MLLMs) within the domain of autonomous driving and challenge/verify some common assumptions, focusing on their ability to reason and interpret dynamic driving scenarios through sequences of images/frames in a closed-loop control environment. Despite the significant advancements in MLLMs like GPT-4V, their performance in complex, dynamic driving environments remains largely untested and presents a wide area of exploration. We conduct a comprehensive experimental study to evaluate the capability of various MLLMs as world models for driving from the perspective of a fixed in-car camera. Our findings reveal that, while these models proficiently interpret individual images, they struggle significantly with synthesizing coherent narratives or logical sequences across frames depicting dynamic behavior. The experiments demonstrate considerable inaccuracies in predicting (i) basic vehicle dynamics (forward/backward, acceleration/deceleration, turning right or left), (ii) interactions with other road actors (e.g., identifying speeding cars or heavy traffic), (iii) trajectory planning, and (iv) open-set dynamic scene reasoning, suggesting biases in the models' training data. To enable this experimental study we introduce a specialized simulator, DriveSim, designed to generate diverse driving scenarios, providing a platform for evaluating MLLMs in the realms of driving. Additionally, we contribute the full open-source code and a new dataset, Eval-LLM-Drive, for evaluating MLLMs in driving. Our results highlight a critical gap in the current capabilities of state-of-the-art MLLMs, underscoring the need for enhanced foundation models to improve their applicability in real-world dynamic environments.
5/10/2024
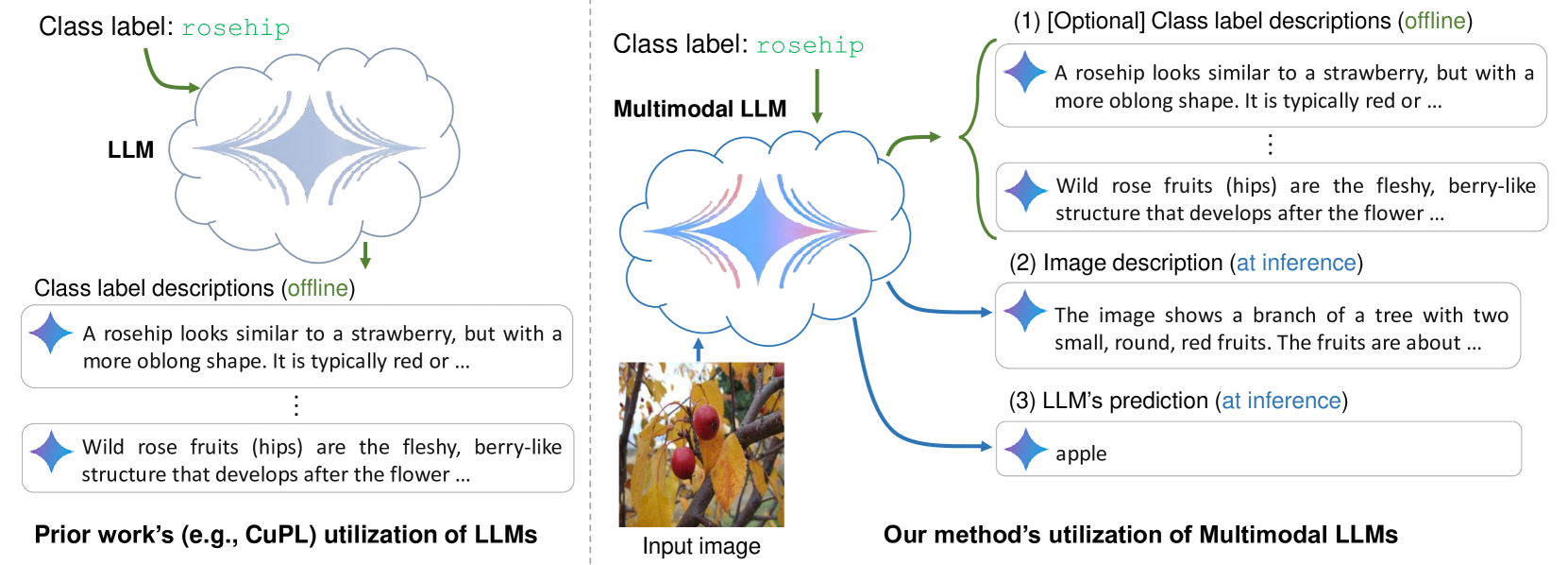
What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models
Abdelrahman Abdelhamed, Mahmoud Afifi, Alec Go
0
0
Large language models (LLMs) has been effectively used for many computer vision tasks, including image classification. In this paper, we present a simple yet effective approach for zero-shot image classification using multimodal LLMs. By employing multimodal LLMs, we generate comprehensive textual representations from input images. These textual representations are then utilized to generate fixed-dimensional features in a cross-modal embedding space. Subsequently, these features are fused together to perform zero-shot classification using a linear classifier. Our method does not require prompt engineering for each dataset; instead, we use a single, straightforward, set of prompts across all datasets. We evaluated our method on several datasets, and our results demonstrate its remarkable effectiveness, surpassing benchmark accuracy on multiple datasets. On average over ten benchmarks, our method achieved an accuracy gain of 4.1 percentage points, with an increase of 6.8 percentage points on the ImageNet dataset, compared to prior methods. Our findings highlight the potential of multimodal LLMs to enhance computer vision tasks such as zero-shot image classification, offering a significant improvement over traditional methods.
5/27/2024